














APIs
Event-driven Microservices with Request/Response APIs - Part One

This is the second part of a series of blog posts about integrating event-driven microservices with request/response APIs. In the previous part, we discussed which integration challenges and how idempotent event processing can help.
Having dealt with integration, it’s worth reflecting on the issue of event retrieval. The key lesson from our experience is the importance of decoupling event retrieval from event processing.
In the previous blog post, we briefly discussed how the integration of request/response APIs into event-driven microservices implies tight coupling due to request/response-based communication. The processing speed of a single event depends on the request/response API and its response time because the event processing blocks until it receives a response.
Simple event loop implementations, like the one we used in the previous post or the working example from AWS SQS Java Messaging Library, process events sequentially. We don’t recommend this because the overall processing time is the sum of all individual processing times.
Fortunately, libraries such as Spring Cloud AWS provide more efficient implementations that support the concurrent processing of events. The ALWAYS_POLL_MAX_MESSAGES behavior is outlined in Figure 1.
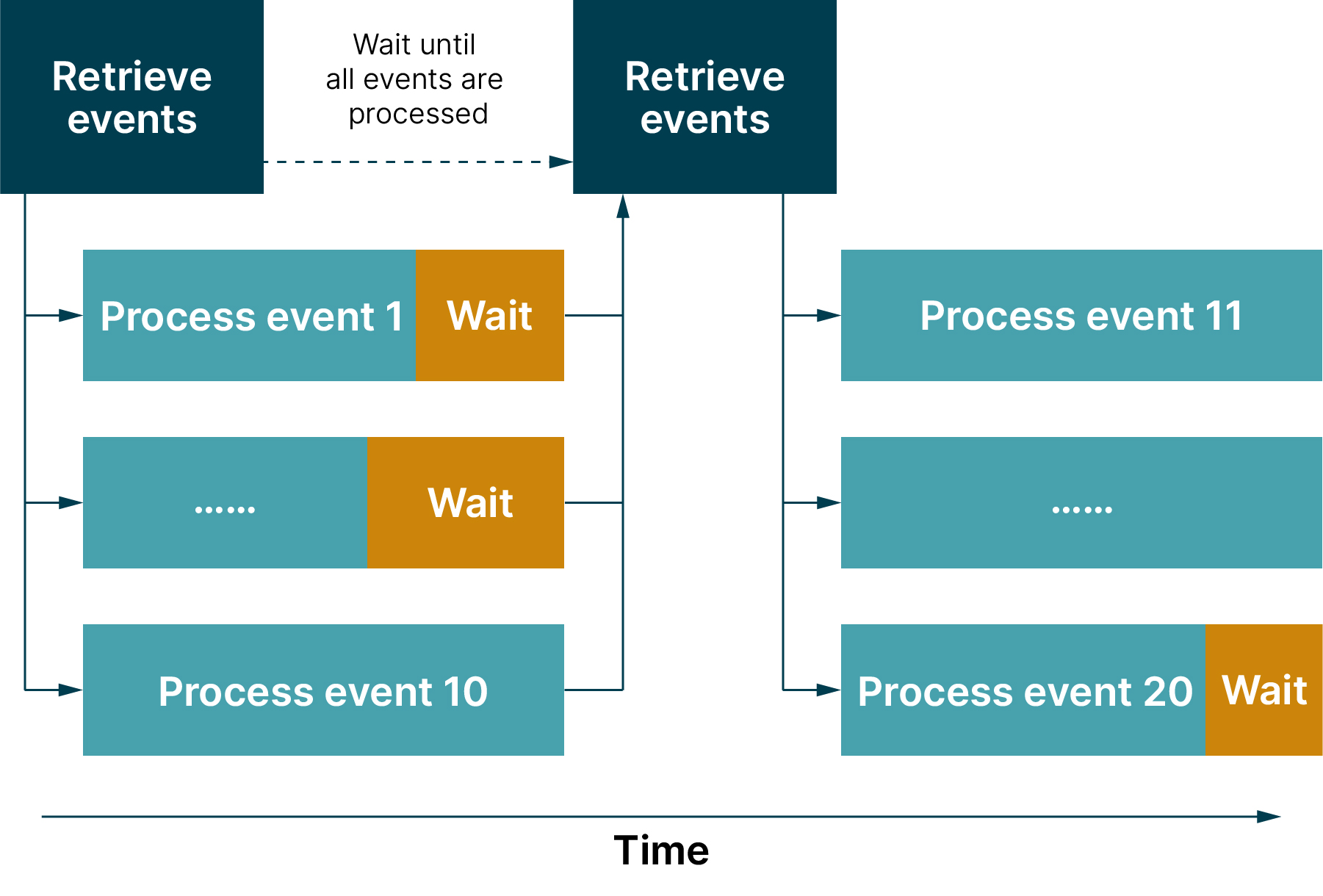
Figure 1: Concurrent event processing
After a batch of events is retrieved (up to 10 events on AWS SQS), each event is processed concurrently in a separate thread. When all threads have finished processing, the next batch of events is retrieved. The tight coupling due to request/response-based communication can have the effect that events are processed at different speeds. Faster threads are then in a waiting state until slower threads have finished processing events. Consequently, the processing time of a batch corresponds to the time of the slowest processed event.
When the order of events isn’t important, concurrent processing can be a sensible default. However, in our experience there are use cases in which event processing can be further optimized. This is the case when there are large time differences between the processing of individual events and threads would therefore be in the wait state for a long time.
For example, we integrated a request/response API whose performance fluctuated significantly. On average, the API responded after 0.5 seconds. But, the 95-percentile and 99-percentile values were regularly 1.5 seconds and greater than 10 seconds, respectively. With this concurrent event processing, threads were regularly in a waiting state for several seconds because of the slowly-responding API before new events could be processed.
You can further optimize event processing by decoupling the retrieval of events from the processing of events. This way, individual events that take longer to process won’t slow down the processing of other events. Spring Cloud AWS provides the FIXED_HIGH_THROUGHPUT behavior that shows what such a decoupling can look like.
It’s outlined in Figure two with further description below. All details can be found in the documentation.
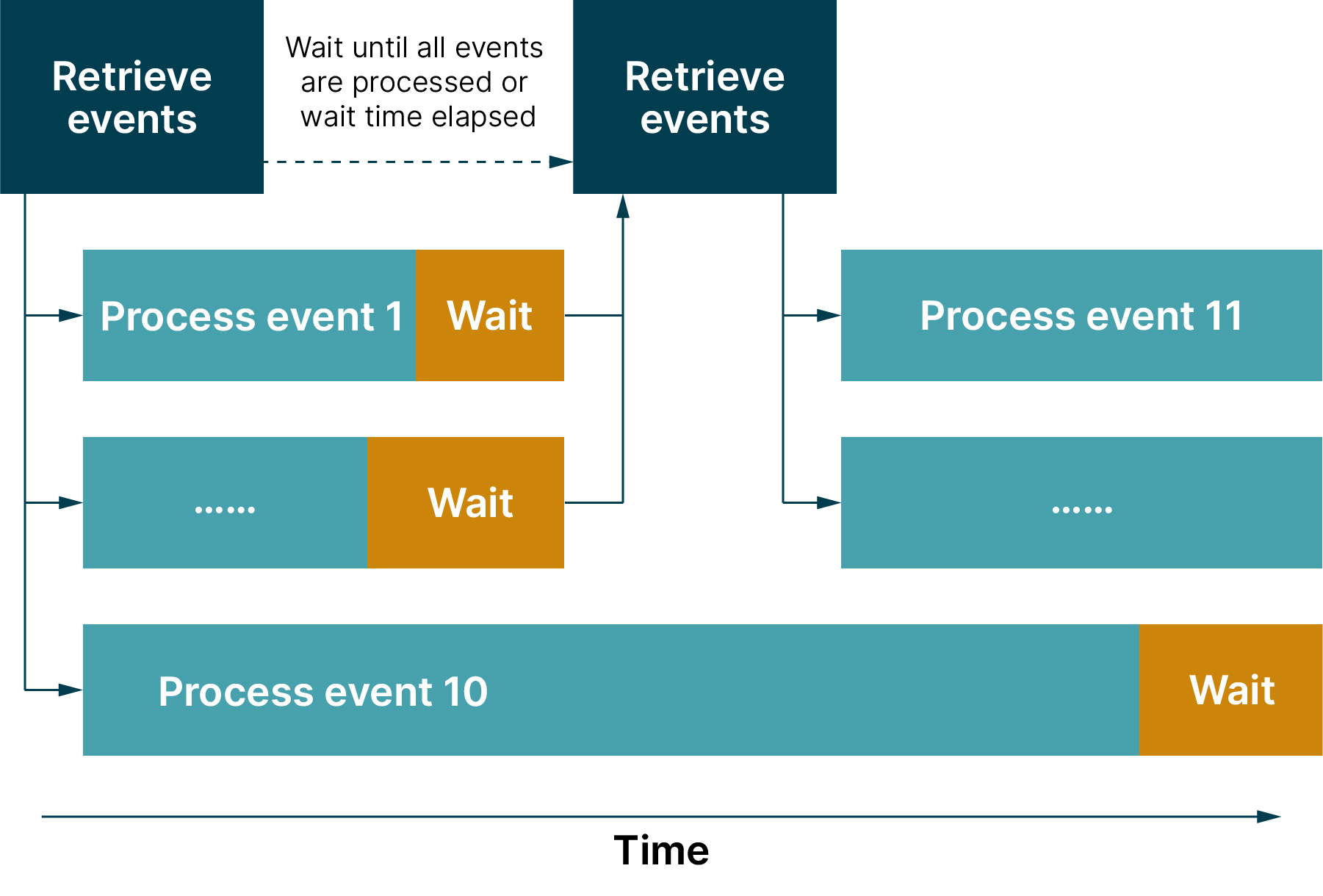
Figure 2: Decoupled event processing strategy
For this purpose, an additional property is defined for the maximum wait time between two event retrievals. New events are retrieved when, as before, all events have been processed or when the wait time has elapsed. If, after the wait time has expired, for example, one event is not yet processed, then nine new events would already be received and their processing can be started. This means those nine threads won’t be in a waiting state until the last event is processed.
In our experience, this decoupling can improve the utilization of individual threads if the wait time and other parameters are well configured. A possible disadvantage can be the additional cost, since events tend to be retrieved more frequently but in smaller batches. For this reason, it’s important to understand the performance characteristics of the APIs in order to choose between concurrent or decoupled event processing.
When you integrate event-driven microservices with request/response APIs, you introduce tight coupling. The performance characteristics of the request/response APIs are important because they help you choose between concurrent and decoupled event processing.
In this post, we focussed on the performance of request/response APIs in terms of request times and how they impact the performance of event-driven microservices. In the following piece, we’re going to take a closer look at how to pause event retrieval.
You can read the rest of the series here:
Retries are inevitable and event processing including the request/response APIs should be idempotent (Part One).
The response times of request/response APIs impact the performance of event-driven microservices. If response times fluctuate significantly, it makes sense to decouple event retrieval from event processing (Part Two).
Circuit breakers can improve the integration with request/response APIs as they handle periods of unavailability (Part Three).
Request/response APIs may have usage limits and rate limits help adhering to them (Part Four)
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

