














Some of the world’s most important problems require organizations to share highly sensitive data. Although we’ve realized enormous value through data science, data analytics and improved data sharing architectures over the last few years, we’ve also seen valid privacy and security concerns hold back a range of highly valuable use cases. In particular, there are a number of use cases that require the sharing of highly sensitive data across different organizations or between different departments within organizations.
To tackle this, we’ve developed Anonymesh.
Anonymesh is a data sharing service that allows you to connect sensitive data sources to answer questions, with privacy and security built in.
The challenge: The privacy - utility trade off
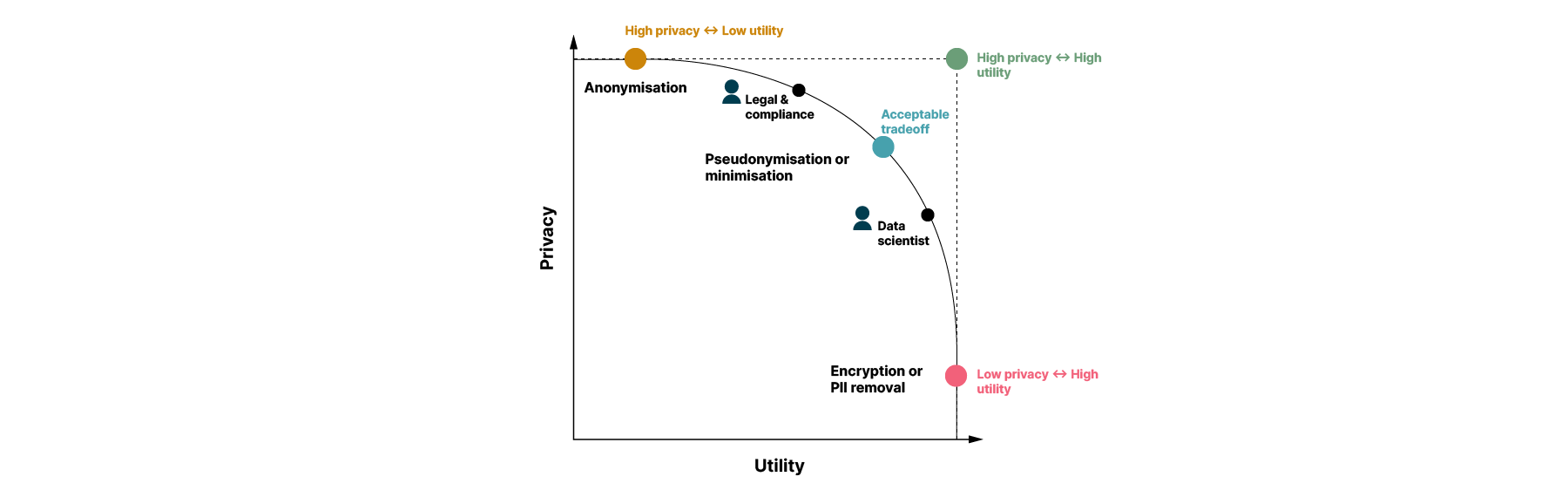
When designing the solution for this space, we first had to consider a classic problem in data: the privacy vs. utility tradeoff. Although a range of privacy techniques exist, there is no ‘one size fits all’ solution; different privacy technologies and approaches are appropriate for different use cases. For instance, anonymization may be useful for regular reporting around specific metrics, but it may prevent a data scientist from creating a personalized recommendation algorithm for customers. When deciding on an approach, an “acceptable” trade-off has to consider all sides; the legal and risk appetite of the company, the use case you’re tasked with solving and, most importantly, the sensitivity of the data.
We therefore needed our architectural approach to provide flexibility for a range of techniques depending on the use case.
Today’s advantage: The market has changed
As mentioned previously, a wide range of sophisticated techniques exist, including federated machine learning and analytics which move the algorithm to the data rather than the data to the center, as well as advances in mathematical techniques in encryption and anonymization — such as differential privacy. These have advanced massively over the last five to 10 years and are being used by tech behemoths including Google and Apple.
Of course, their sophistication may be off-putting given the skill set needed to develop these techniques, particularly when seemingly simple privacy solutions such as third-party “clean rooms” exist.
However, we’re also seeing these solutions become more easily available thanks to projects such as Flower Labs. Given the new and open availability of these technologies, such as those developed by Flower, and the escalated risk of sharing highly sensitive data when using third-party clean room solutions, we decided to develop an architecture that allows for increased privacy by taking advantage of them. This enables further risk mitigation without increasing the cost.
How does this work now?
Suppose a user — whether a data scientist, analyst or other — requires access to data from different sources to uncover the answer to a question. These sources might be databases in different departments, databases in different organizations entirely or a million internet of things (IoT) devices. In many organizations, each data producer would develop an API solution so others can pull data, supported by a centralized data platform that makes self-serve easier. However, where there are serious concerns about sharing this data beyond certain boundaries, this becomes challenging. One common pattern we’ve seen is creating a request system where experts can determine whether they can fulfill certain data sharing requests based on predetermined sharing agreements. We’ve observed this at a range of organizations including large banks with a Data Mesh, but for our proof of concept (PoC) we focussed in particular on the challenge facing UK public sector organizations.

Data sharing legislation is constructed in such a manner that it allows the government to provide better services for citizens. However, the challenge we have repeatedly seen is that the legal agreements are often so complex that those receiving the requests will typically err on the side of caution — often simply opting not to fulfill the request. These processes also often rely on email which makes it difficult to maintain accountability, and relies on junior members of staff to interpret data sharing agreements and make complex disclosure decisions.
Many examples of complex data sharing use cases exist across the public sector. In particular there are very high value use cases where the challenge is not so much a lack of sophisticated algorithms to interpret the data, but instead having a secure way to share sensitive information that doesn’t require repeated interpretation of complex legal agreements.
We’ll first consider just one to demonstrate how our proof of concept approach can work in practice.
Example one: Proactively identifying at-risk children
One powerful example of the above pattern was revealed by the children’s commissioner inquiry in the UK last year. The commission investigated why there were so many cases of babies and children being abused despite multiple public organizations (eg., the school, policing, and healthcare systems) having evidence of concern and having legal agreements to share relevant information to protect children. They found that “Despite attempts to make data sharing the ‘default’… many were still apprehensive about sharing information for fear of oversharing details and being prosecuted or fined.” (Note that this problem has not yet been solved.)
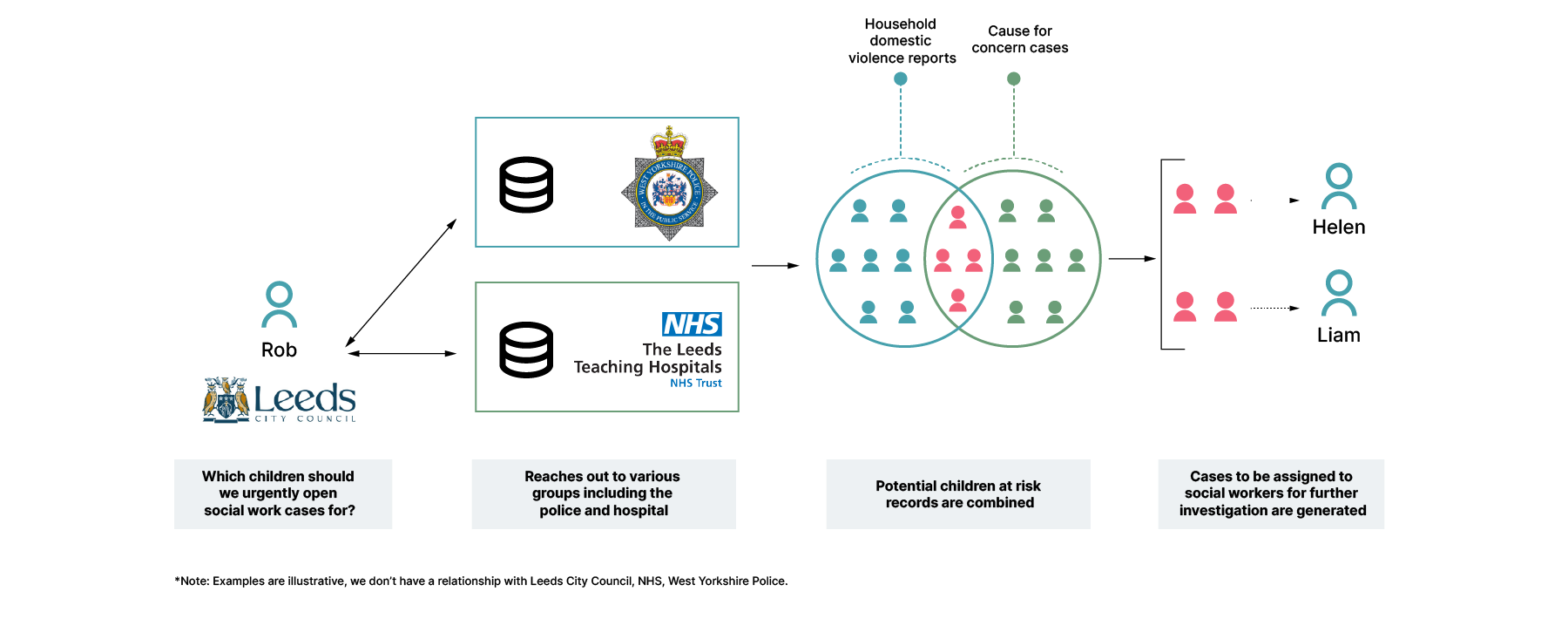
In order to demonstrate the Anonymesh approach, let’s first consider the above problem. A council may wish to create urgent cases for children where both a doctor has identified a potential cause for concern and their home is linked to household domestic violence reports. Both police and NHS groups hold relevant data but may not be comfortable sharing out the full lists as only the children in both risk groups are considered at high risk — and medical records in particular are highly sensitive. Here lies the major challenge: how do we share the list of children who are at very high risk without exposing information about children whose risk profile is much lower?
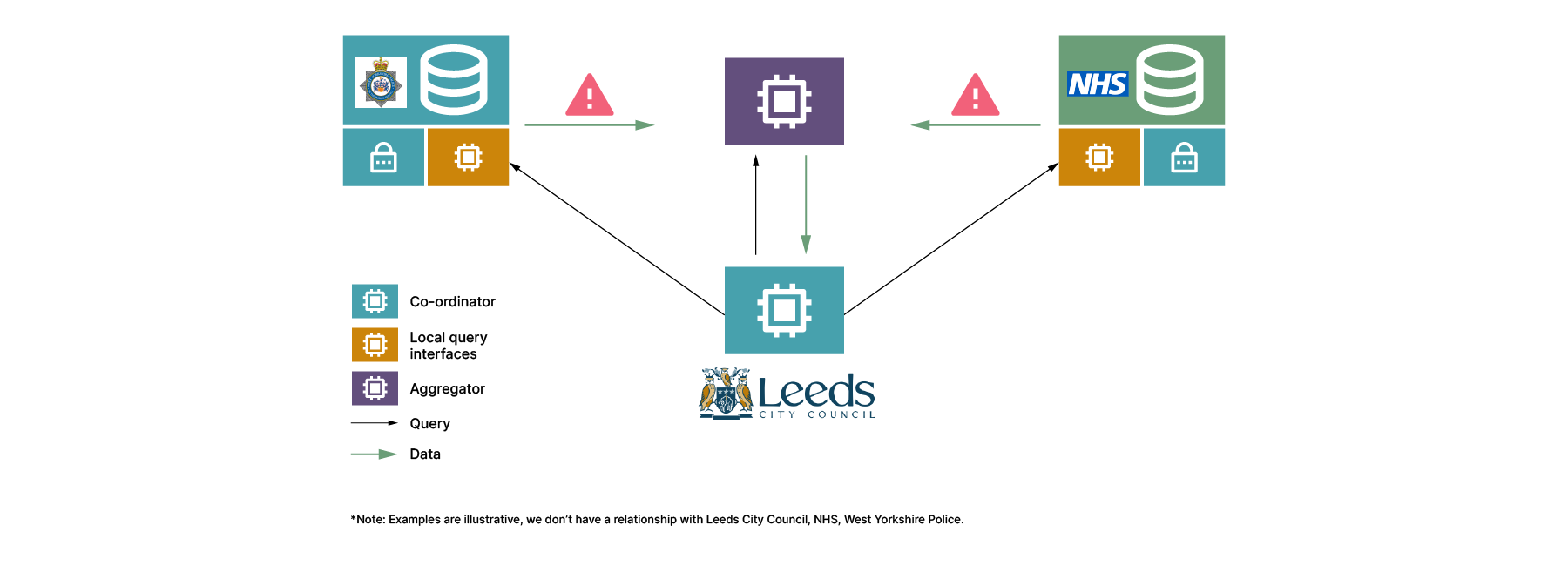
Now we can discuss the Anonymesh approach and how we might solve this. First, we know that in order to serve up insight (ie., a list of children at high risk) we need to perform a series of computational steps: select the appropriate reports from the police and NHS, merge them, identify the overlapping set, remove any data that’s not required and, of course, any encryption/decryption that may be required along the way. Under our approach, we consider where the required computation can take place: in the systems of our data holders (in this case the local police and NHS groups) and the systems of our data requester (in this case the council), but we also add a key area of computation which takes place separate to all these three user groups. We expect requests for information to flow from the data requester system to the data holder systems, and data to then flow from the data holder systems via the central system, back to the data requester system.
Now we have established the problem — i.e. the need to share specific data without unnecessarily exposing highly sensitive data that is not required — and the potential systems for computation, we can consider how to break up the query. In this case, we pay particular attention to the data leaving the data producer systems. This is the most sensitive part of the system — where data leaves the highly trusted secure area into an area which is of lower trust. How might we do this securely?
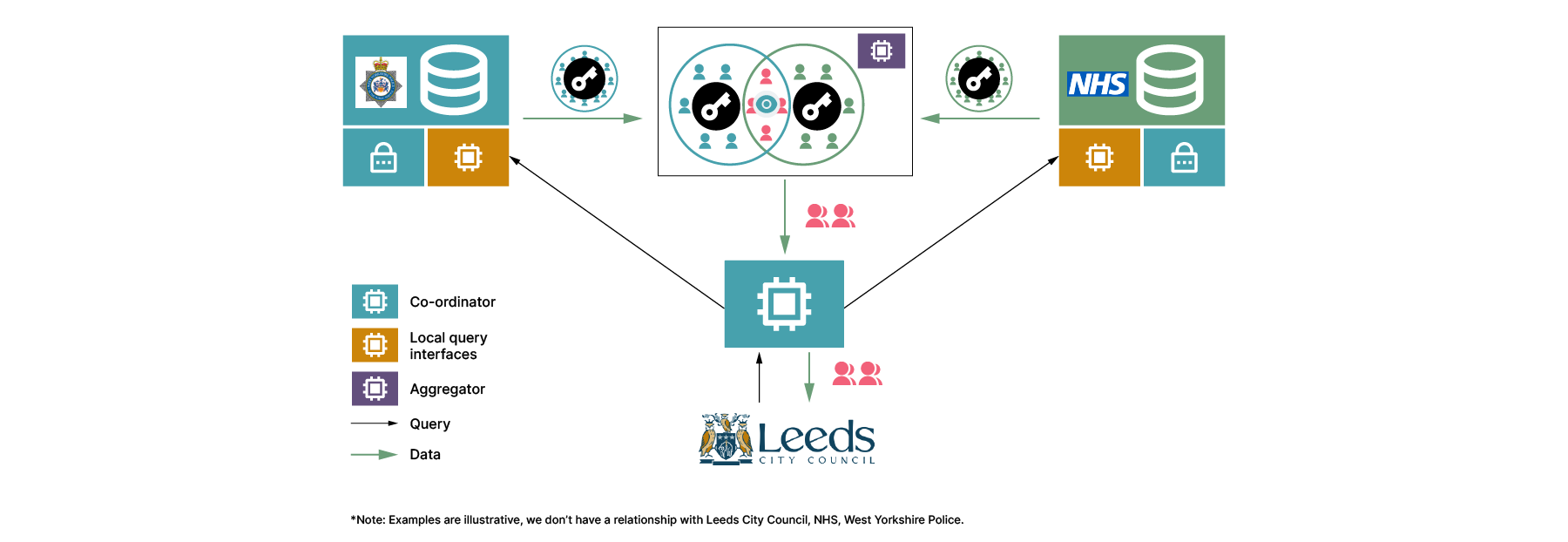
One possible solution is to use the private set intersection technique. This is an encryption protocol that allows us to reveal matches in the data without revealing all of the data; it's sometimes referred to as a private join. A private join allows two data holders to compare their data sets, sharing only encrypted versions of their data and still finding overlaps amongst those datasets, which can be used for later analysis. Importantly for this use case, the only data leaving the NHS and police systems would be encrypted. Even though the data is encrypted, the council could use the private join to identify the relevant cases, thus protecting the most at risk children while maintaining anonymity of others.
The Anonymesh approach
At a high level, the architectural pattern used in the above example is ideal for data sharing across two or more data sources where there are high privacy concerns. We used this same pattern for our in-house proof of concept.
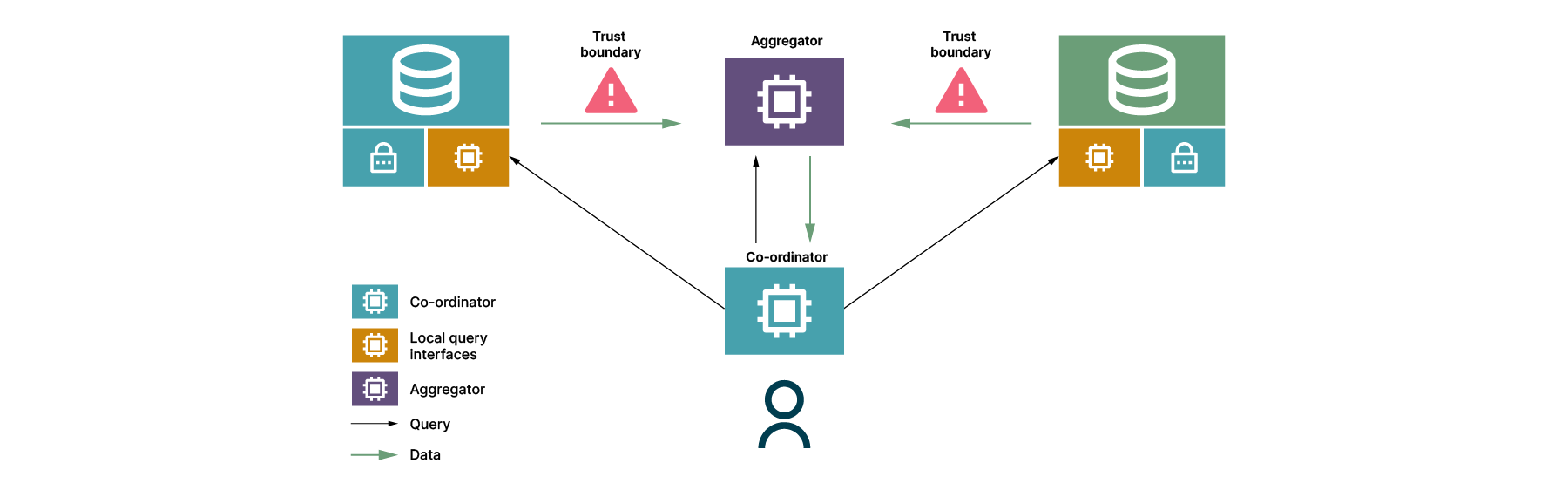
Let’s consider the key components:
Co-ordinator: A data ecosystem needs to manage a diverse range of users making different requests. The co-ordinator manages requests across the federated architecture, serving as a router within the mesh. For each user request received, the co-ordinator can then generate local query interface (LQI)-specific requests - each LQI is only provided with the data it requires to execute its specific part of the request, further increasing data privacy.
Local query interfaces: Each data producer that is part of the mesh may have its own independent architecture. Local query interfaces facilitate interaction between these architectures, making it possible for requests to be received and interpreted. They also support privacy by enabling encryption or data minimization by executing a detailed query type to provide a single answer.
Aggregator: Finally, we have a central location for the final computation to take place. This exists not only because the use cases require data from different sources to be combined in order to answer a query, but also because the sensitive nature of the data means we don’t want the user to access the data until the query has been executed. Hence the aggregator is a separate component to the co-ordinator.
Finally, although not a component, the final concept to consider is trust boundaries. For any given use case we wish to build across this architecture, we need to ensure that data crossing any trust boundary is secure. For example, when the local query interfaces respond to a query and send their responses to the aggregator, this can open up to privacy and security threats. As mentioned previously, a number of common techniques such as data minimization, encryption, federated machine learning, federated analytics and differential privacy can be applied to those responses before they hit the aggregator — or the aggregator can act as a participant in the computation and provide those services as a core step of processing the individual responses. While each use case will require a different set of techniques to be applied, many can be applied using this architectural pattern.
Let’s consider another example to further demonstrate this approach.
Example two: Our PoC to determine EU citizens’ eligibility for right to remain status
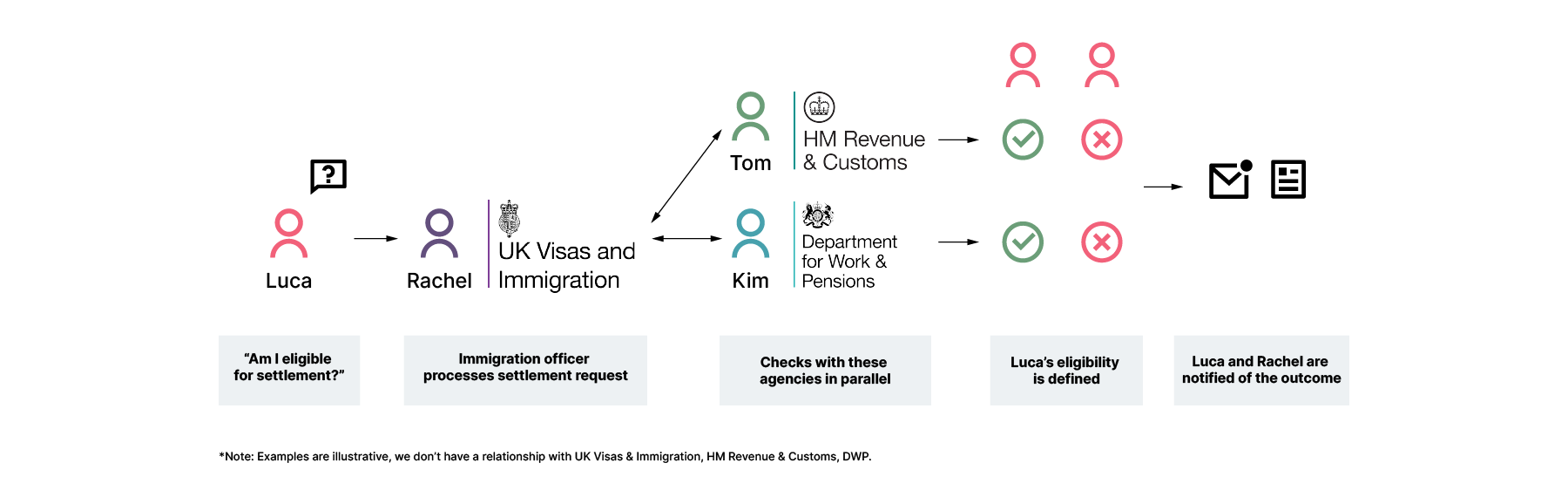
Following the vote for the UK to leave the EU in 2016, a policy was implemented that would allow EU citizens to gain long term residency status in the UK. The civil service was tasked with rapidly implementing this service. The process required immigration services to manage each application for this right to remain, and involved sourcing information from other government departments to determine, for instance, whether an applicant has indeed been resident for over five years. Again, this presented challenges around the sharing of sensitive information between government departments.
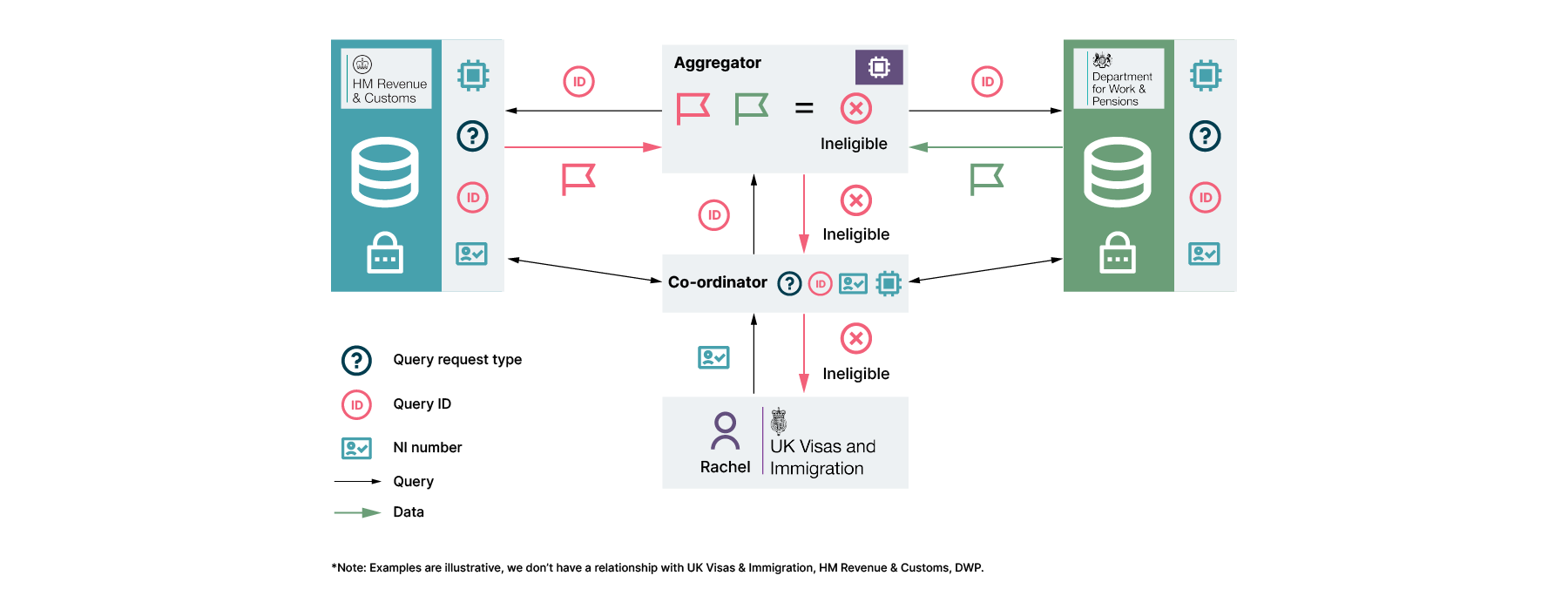
We have built a working demo, following the Anonymesh architecture to demonstrate how we can accelerate the process without compromising data privacy.
Rachel, an immigration department employee, receives an application for the right to remain from Luca. As part of the process, she shares Luca’s National Insurance (NI) number with the DWP and HMRC via a query to the co-ordinator.
The co-ordinator generates a query ID and shares this, along with the request type (eligibility for right to remain check) with the relevant departments. Luca’s NI number is also shared with the relevant departments.
Each department processes the request and generates a boolean flag to confirm whether there are any concerns. In this case, HMRC has concerns, whereas DWP does not. In our example, the local query interface can support multiple data backends, such as structured documents or SQL databases.
When the aggregator is ready, it requests these booleans using the query ID. Based on the request type, it can then produce a single boolean result for the co-ordinator. In this case, it shares with Rachel that there are concerns about this application. Rachel can share this with Luca and pause the application.
This is just a simple example, but it’s designed in such a way that:
The only data to leave the departments are booleans. We have minimized information leakage by sharing only a boolean instead of a long list of potential factors that are evaluated to come to that conclusion
The aggregator never receives any NI numbers, only booleans and query numbers. By disaggregating the query ID and the NI number, the results are not immediately linkable to the person, providing an extra layer of security and less duplication of sensitive information.
The co-ordinator and UK immigration officer only receive a single boolean, not details of which department(s) may have rejected the application. Ie the only data shared is that which allows required actions to be taken. Rachel can now inform Luca that there’s been an issue.
So what happens next? Well we imagine that Luca might want to understand why he was rejected and correct any issues. We also developed a solution for this.
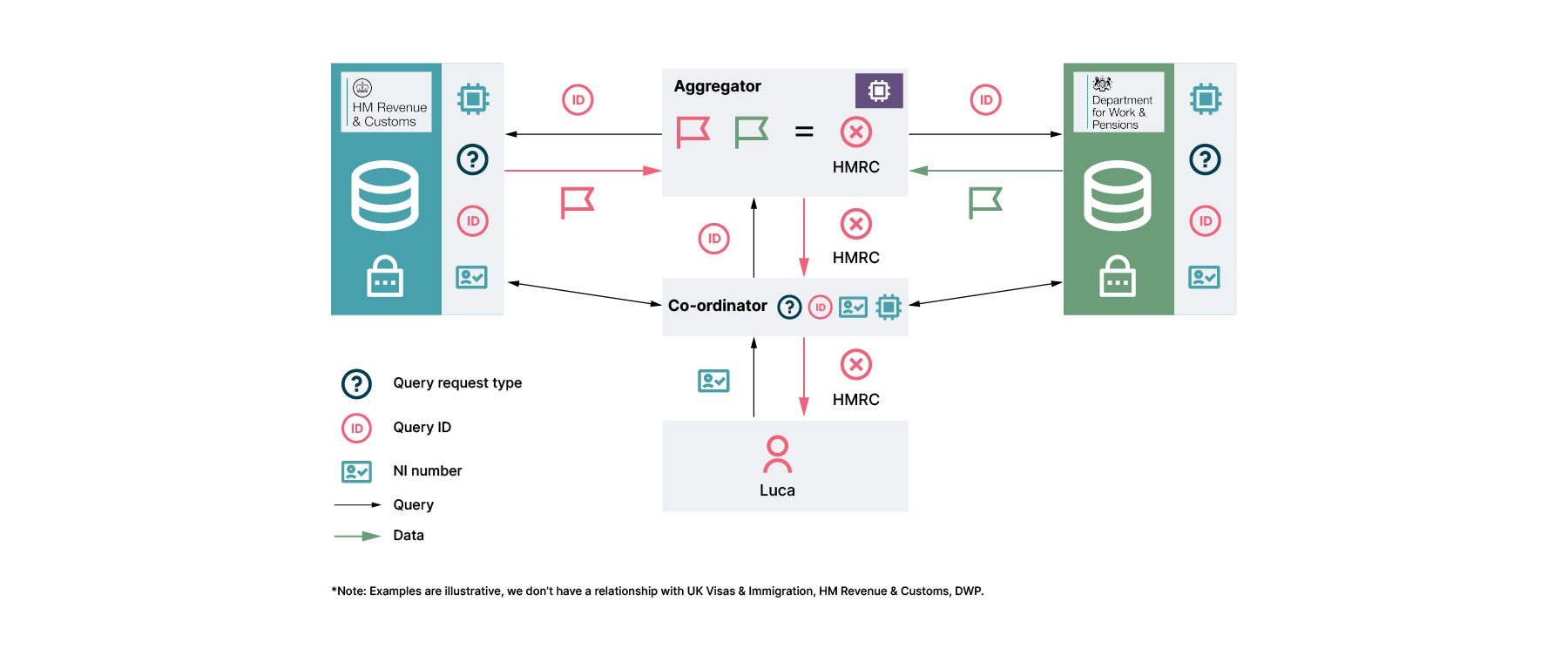
This time, since Luca is logged in, he is able to request an appeal. The aggregator knows, from the changed request type (which is available to Luca but not Rachel), to share the list of departments with concerns. Luca now knows to directly contact HMRC, without HMRC having to share detailed information with immigration employees across the immigration system.
Considerations and further development
This is just an early stage PoC but we believe it gives the foundations for privacy-first data sharing. A few considerations to keep in mind:
The querying process used above assumes synchronous systems and a low chance of faults. There are many other options for how the coordinator could manage queries based on technical requirements of different organizations. We are developing this further to ensure the architecture and processing is adaptable to a wide range of query types. In particular, Anonymesh may require human-in-the-loop approval requirements or systems with limited networking or compute availability.
For the initial implementation, we decide the list of acceptable queries in advance. These should be decided by agreement between relevant departments. The code to execute these is then written locally on the client-side across the different systems. In any given organization, agreements will have to be made around who is responsible for writing this code and how it will be reviewed and managed.
By providing leading technologies, such as encryption in the first example, or simpler approaches, such as data minimization in the second, we have reduced the need to duplicate and share sensitive data. This allows public authorities to process data well within the limits of their legal agreements without endangering citizen data unnecessarily.
There are a very wide range of data processes that may need to be used, like more flexible querying or development of machine learning models. We’re continuing to test and develop these use cases and would love to hear more challenging problems Anonymesh could help solve!
Key learnings
We can reduce sensitive data exposure by pushing compute to the edge, rather than pulling data to the center. To do this, we need to implement an architecture that allows for coordinated distributed computation, where centralization happens only in the final stages.
A one size fits all approach to complex data sharing processes does not work. Each case has different data requirements. Decide which approach to use on a case by case basis - with a particular basis on what data crosses trust boundaries. Prioritize high value use cases and reduce data access to what’s required to achieve value.
New algorithmic techniques are available that have been developed over the past decade that have changed what’s possible. Take advantage of readily available software, such as Flower, that make these techniques easy to use, reducing the need to code complex distributed algorithms from scratch.
* all examples above are for illustrative purposes only, and are not representative of relationships Thoughtworks has with organizations, or relationships they have with each other.
Team and contacts
If you have any questions about Anonymesh or ideas for its use, please reach out to any of us for more information:
Erin Nicholson, Global Head of Data Protection - erin.nicholson@thoughtworks.com
Katharine Jarmul, Data Scientist, author of Practical Data Privacy (oreilly.com/library/view/practical-data-privacy/9781098129453/) - katharine.jarmul@thoughtworks.com
Rajat Jain, Data Scientist - rkjain@thoughtworks.com
Viviana Perez, Anonymesh Product Owner - vperez@thoughtworks.com