














某天,正跟小张pair做卡呢。突然收到客户通知:不用做了,这系统不要了。
啊? 都搞了好几年,说不要就不要了,客户这么财大气粗?
细问之下,原来变化来源于最新的商业决策——客户收购了一个市场占有率比较大的新公司,打算直接使用新公司已有的系统。那我们是不是可以下项目休息了?曹老大瞟了一眼我:你想得美。客户希望把现有的生产数据迁出到新系统去。不是吧,又迁,咱们不是刚把之前收购的老系统数据迁到新开发的系统吗?
模型分析
前方目标很明确:数据迁移,让数据的价值在新系统中继续发光发热。
新老系统由于只是同一个领域的不同实现,所以模型上很相似。主要的源数据模型都能映射到目标模型,模型上的部分字段甚至也是等价的概念。但是毕竟是两波开发实现的两个不同的系统,很多业务概念叫法完全不同,首先就需要坐下来跟客户一起统一模型语言。另外,还有很多新系统的目标字段不能由源数据直接获得,有的字段甚至无法获得。所以,我们根据不同类型的数据特征,将数据分成了4种类型:
直接映射,源数据模型的字段值直接映射为目标数据模型的字段值。
间接映射,源数据模型的一个或多个字段值经过一定的业务规则转换为目标数据模型的字段值。
默认值,源数据模型没有相关的字段,而目标数据模型又是必填的字段值。
丢弃,源数据模型没有相关的字段,而目标数据模型也不是必填的字段值。
根据这四类规则,在和客户友(lai)好(hui)讨(la)论(che)了多轮之后,我们得到了一个数据映射表,将所有需要迁移的源数据模型映射为目标数据模型。
迁移策略
数据清楚了就开搞吧!等等,客户对迁移又提了几个新需求:
新系统的数据加载部分想复用已经写好的脚本,脚本的输入是json文件,所以希望使用json文件作为介质将老系统的数据传输到新系统。
在数据还没全部迁到新系统之前,两个系统同时都要用,因为客户需要在用户慢慢熟悉新系统的同时,使用老系统保证业务连贯性。
这意味着两件事:老系统在几个月内还会源源不断的产生新数据;新系统需要在一定的时间段内看到老系统新产生的数据。这样的状况可能要持续很久,直到客户喊停才能停。于是,迁移可能会变成这样。
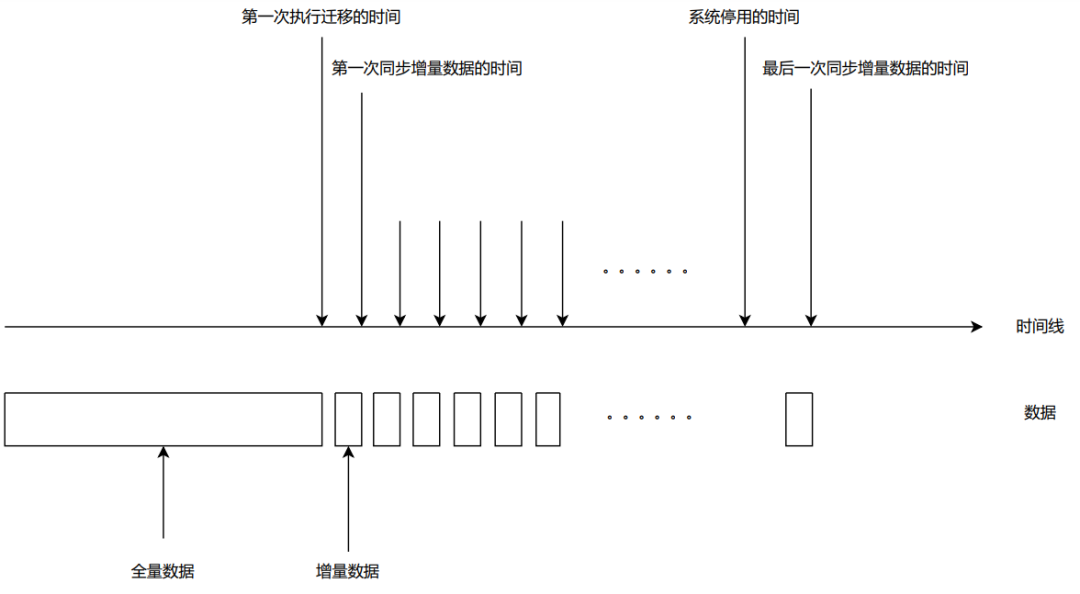
根据数据量的不同,我们把迁移又分成了全量迁移和增量迁移。
全量迁移关注的是如何把大批的数据一次性迁入到新系统,由于数据量较大,文件需要进行分片处理。增量数据则关注的是如何保证数据实时性,在客户能够容忍的时间范围内,将增量数据同步到新系统。客户对实时性要求并不高(一天之内),而且也不希望在新系统上新增API去做实时同步,所以定时任务已经能够满足增量数据同步的要求。
数据实体间存在单向依赖,希望按照依赖关系分批进行迁移,简化的说明图如下:
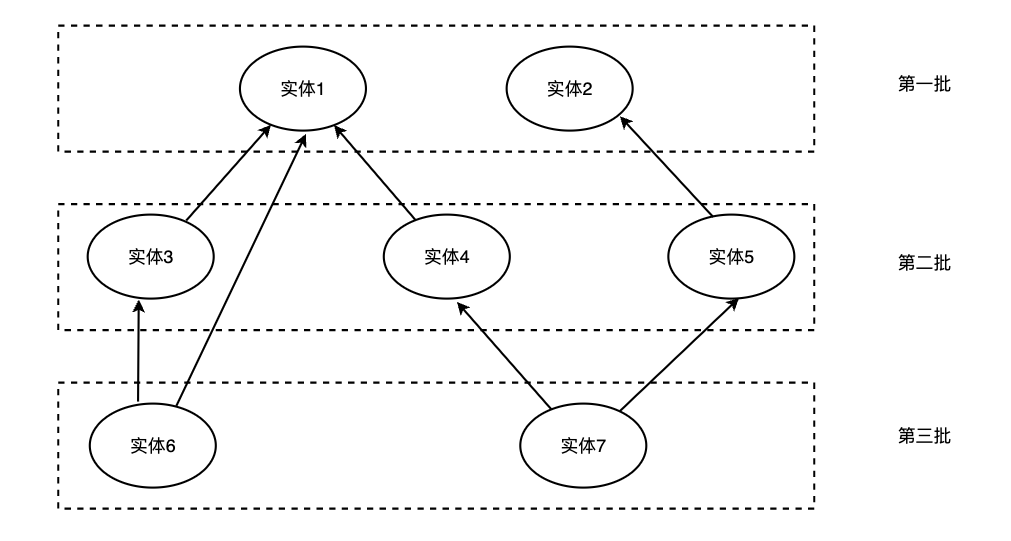
对于增量数据,也需要考虑根据依赖关系,调整定时任务的实体同步顺序。
实现
其实整个迁移过程看起来就是一个经典的ETL过程,先将源数据从老系统提取(E)出来,根据数据映射表进行转换(T),最后通过生成文件并加载(L)到新系统中。但在实现过程中还是遇到了不少麻烦。
AWS to GCP
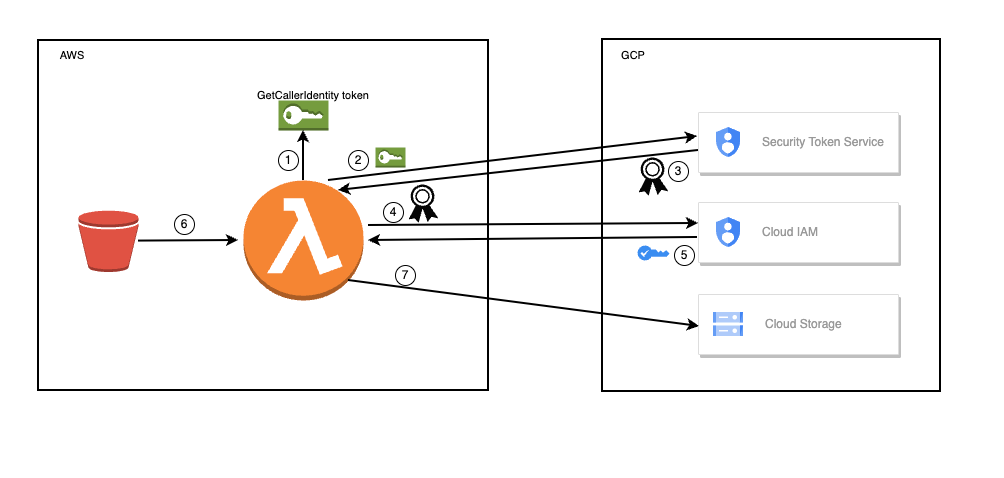
这是我们在设计阶段遇到的第一个大麻烦,老系统运行在AWS环境,而新系统运行在GCP环境。云迁移的案例在网上搜集相关资料比较少。Spike了几轮之后,处于安全性,效率等因素考虑,我们决定使用GCP的Workload identity federation(WIF)进行云平台间数据迁移。WIF是GCP提供的外部服务访问GCP资源的服务,它旨在消除与服务帐号密钥相关的维护和安全负担。WIF遵循OAuth 2.0 令牌交换规范,令牌交换的主要过程大致为:
获取AWS GetCallerIdentity token
使用AWS GetCallerIdentity token交换GCP federated access token
使用GCP federated access token交换GCP service account access token
使用GCP service account access token访问GCP资源
在我们的项目场景中,由AWS lambda与GCP Security Token Service及Cloud IAM交互完成短期token的获取,并持有短期token执行将S3中的文件存入Cloud storage的过程。
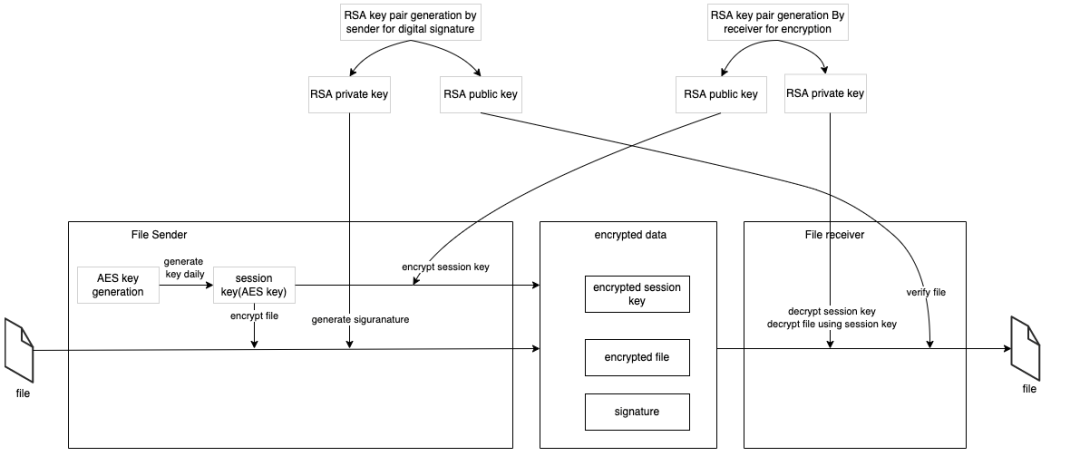
数据安全
数据本身全是跟钱相关的东西,文件又需要走公网从AWS传输到GCP,所以数据安全也是需要重点考虑的环节。虽然GCP本身已经提供了一定等级的数据加密,但是客户还是不放心,希望我们在应用程序本身再提供一层数据安全的保障。于是根据数据安全经典过程,我们在AWS发送文件前对文件做了加密及签名,并在GCP收到后文件完成解密及验证。加密为了保证数据不被中间人窃取,签名为了防止恶意传输攻击文件:
数据合并
前文提过,由于历史原因,老系统当前的数据其实也是从更老的系统中迁移过来了(更老的系统实际也还在使用中),老系统当前对外提供的API存在着大量的数据合并逻辑。如果以数据库为源头对涉及数据合并的实体进行迁移,那么就需要大量重写这部分业务逻辑,而这将会是个漫长而又复杂的过程。如果直接使用当前系统的API,由于迁移访问的数据量很大,又会对线上业务造成影响。
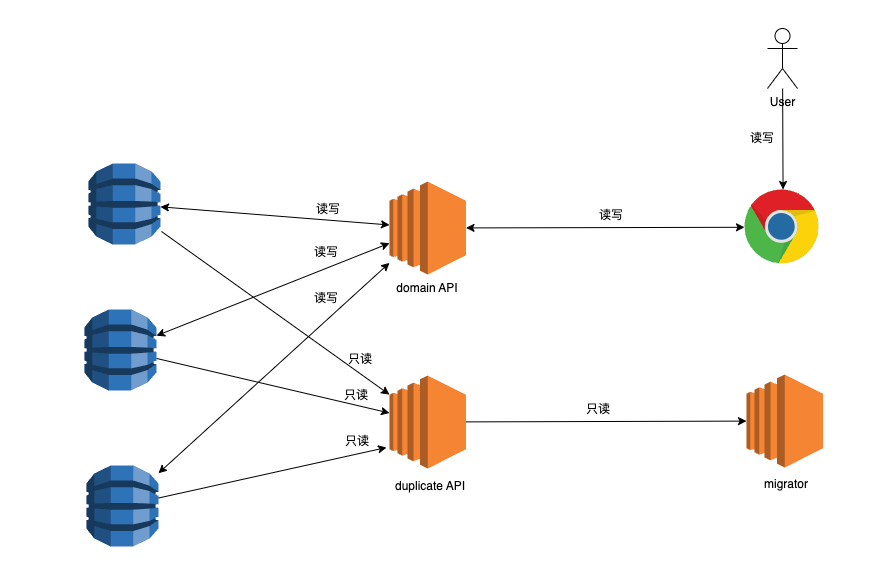
于是我们采取了一个折中的办法,在生产环境中复制了一个只读实例来规避对数据合并逻辑的重复工作,并且不影响线上环境的实例性能。
增量数据统计
对于迁移期间的增量数据,我们采用事件驱动的方式,通过监听源数据库的新增或修改,并触发lambda执行转换过程,将转换后的数据存入中间表并记录修改时间。在每天生成增量数据文件时,通过查询所有比上次迁移时间晚的记录,得到所有增量数据并最终生成本次文件。
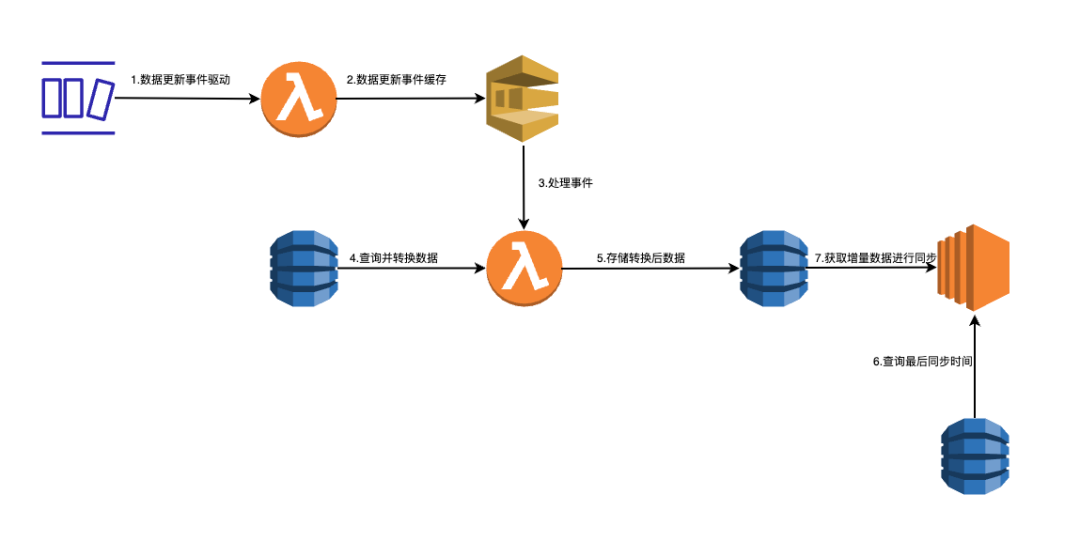
数据校验
在生成文件的过程中,我们会对实体的各个字段根据业务规则进行校验,对不符合校验规则的数据将其原始数据及错误原因收集到错误日志表中,方便我们后续修数据的环节。我们的测试环境虽然有一部分数据也来自生产环境,但出于安全原因,大部分字段都做过混淆。所以在测试环境无法收集到所有真实数据的错误,很难保证迁移的最终结果。
于是在上线前的一两个迭代内我们做的事情是,在生产环境中进行若干轮预迁移(但不执行加载)。这样每一轮预迁移会收集到一部分数据错误。这些数据错误大部分需要与客户讨论后进行处理,主要处理方式有:
数据本身输入不合法,需要客户确定正确的值并修复
数据本身输入合法,根据新系统的表现形式,重新确定转换逻辑给予合法值
数据无法修复且不重要,丢弃
这样在经过多轮预迁移以后,我们修复了所有生产环境上的错误,从而保证了最终迁移到新系统的数据质量。
数据审计与错误追溯
在做完数据迁移之后,我们需要进行数据审计及错误追溯,以保证迁移过程没有丢失数据。在第一批数据迁移完成后,QA同学经常抱怨说现在对数据审计及错误追溯非常不友好。原因是我们对第一批数据迁移的设计是,源数据转换后直接生成目标文件。这导致进行审计以及出错排查的时候,需要对文件直接进行分析。而分析文件有两个非常不方便的点:
生产环境不允许下载文件,只得在生产环境上搭建用于审计及错误排查的脚本运行环境
即使是测试环境允许下载文件,有些实体数据量非常大,文件无法直接打开,还是得写脚本进行分析
为了解决这个痛点,从第二批数据迁移开始,我们首先将转换后的数据存入中间表,这样也就对迁移过程做了一次解耦。事实证明解耦后我们对数据库直接进行计数对及查询,对数据审计及错误排查的效率有非常大的提升。
收获
数据迁移过程涉及在三个系统之间传输数据。以及AWS到GCP的云平台间的迁移,在这个复杂的过程遇到了大大小小数不尽的坑,也顺势学到了很多东西。
迁移并不是一锤子买卖,为了确保用户的无缝过渡,在迁移过程中保证多个系统的可用性及系统间的数据一致性也非常重要。
实体间依赖对迁移计划影响很大。在迁移过程中,需要建立了依赖映射并监控了每个实体的迁移历史,以检查每个记录的实体关系/依赖关系。每当出现错误时,无效数据和依赖于无效数据的数据将被过滤掉,以确保整个迁移过程能够继续进行。
保持数据可追溯性是迁移过程的关键方面。通过确保所有数据都可以追溯到其来源,可以帮助最大限度地减少数据丢失或损坏的风险,并确保在整个迁移过程中数据的准确性和完整性
为确保成功的迁移,需要对复杂的业务逻辑进行彻底分析,并确定在过程中可能出现的任何潜在问题。这包括将所有必要的字段映射到新系统,并解决源数据中可能存在的任何数据质量问题。
为了确保迁移过程中数据的质量,重要的是制定一个测试策略,并由团队中的每个人进行审查和维护。迁移的验证过程需要充分考虑数据完整性和无数据丢失,并确保在迁移后满足所有指定的功能和非功能方面的要求。
免责声明:本文内容仅表明作者本人观点,并不代表Thoughtworks的立场