














本文作者:张旭海
作为一名程序员,总有一些时候,会对自己所做的重复性的工作感到厌倦,也会羡慕明星项目做得热火朝天 Star 数蹭蹭上涨。而读代码,则是缓解焦虑的良方。
每当读懂软件的精彩设计,赞叹优美整洁的代码,甚至发现藏在注释中的彩蛋时,都好像在不同的时空与作者产生了交叉,畅快地聊了会儿天。
读代码很有趣,但要读通读懂也很费功夫。本文是我在日常读代码中积累的一点心得,分享出来,希望能与大家产生共鸣。
1. 寻找一位好老师
优秀的项目就像一位好老师,我们可以从它身上全方位地学到各种领域知识。
不过在开始读代码之前, 最大的问题就是:怎么样才能找到合适的代码项目?
Star 数高的项目更优秀吗?从某些角度讲的确是的,但是在 gitstar-ranking 上, 4k 个 Star 的 Repo 只能排到第 5000 名,而至少有 50k 个 Star 才有可能排进前一百。光看 Star 数,这项目太多了根本选不出来啊。
在我看来,抓住如下几个方向,一般就能筛选到合适的项目了:
兴趣使然
首先就是一定要选自己感兴趣领域的项目。
不少代码片段都是比较枯燥而难以阅读的(比如“飞一般”的位操作,为提升性能而莫名其妙的语句,或是包含了大量隐含知识等等),只有自己感兴趣,才会有读下去的意愿和动力,才能在其中发现乐趣。
有时候我们开始读代码的契机就单纯只是在工作当中用到了,想要进一步了解其原理和设计,这是一个不错的起点。想必很多同学第一次看源码都是因为一层层追到了 Spring 的 Class 里面去了吧。
有的时候可能就是觉得某项技术很神奇,像魔法一样,越是猜不透,就越想了解它是怎么“施法”的。
总之一旦有了兴趣,就会很想进一步去了解它。不过,如果读到一半又失去了兴趣,也请大胆放弃它。失去了这一片草丛,还有整个树林等着我们去探索。
经典且被大量使用
经典的、拥有大量用户的项目,经历了时间的考验,不断地迭代,通常在设计上都有很多出众之处。
经典项目的维护者一般都是非常资深的工程师,并且也都会有大公司赞助,确保了代码的高质量。这类项目在阅读的过程中能学到很多知识,包括架构抽象、性能优化、工程化等等。
比较常见的典型的项目有如:Go等等。
合适的规模
代码量太过庞大的项目,有时虽然很出名,但难免令人生畏。实际上可以找到很多行数不多,但依然精彩的代码库。
首先就是各种语言的标准库,比如 Java 的 Stream、Lock 的实现等。另外也有不少开源的小而美项目,比如 redis、leveldb等。甚至,许多经典大学课程里面的 Lab 也隐藏着优秀的代码,比如 xv6。
总之,这一类代码可能几天或几周就能大致看完主干,特别适合学习设计思想。
2. 先看文档
选定了项目,我们就差不多能对它有一些浅尝辄止的了解了。
这时候,先不要直接 Clone 代码。代码完整地包含了所有知识,但也将细节毫无保留地暴露出来,直接进到代码里面很容易迷失方向。
对于事物的理解,从全局到部分,从抽象到细节才是一个比较容易让人接受的过程。
成熟的项目通常会有比较详尽的文档,文档一般分为两类:给用户看的使用文档,和给贡献者看的开发文档。
了解概览
通过阅读使用文档我们能快速地了解到项目创立的目的、解决了哪些问题,以及从用户的视角看该软件是什么样子的。除了看 overview,我也会大致关注配置,通过必填配置可以进一步了解软件的依赖和外部特性。
以 TiDB 为例,它的使用文档截图如下:
从左侧边栏能了解到使用文档的结构包括了简介、部署、配置、参考等部分。这些部分都是使用者最关心的内容。
架构和模块
优秀的开发文档一定会包括整个软件的架构模型,和关键模块的设计。
通过阅读架构图和高层设计,软件的原理以及解决问题的思路一目了然。对于有一定经验的读者甚至可能看到架构设计后就已经大概知道软件的工作流程了。

上图是 TiDB 开发文档截图,我们发现它不仅包含了架构设计,还事无巨细的告诉读者如何启动代码、怎样贡献、详细的设计流程等等。
除了架构设计,比较完善的开发文档也会包含关键模块的信息。关键模块可能会涉及核心逻辑的设计和数据结构,以及边界处的契约和交互方式等。
对于 Go 语言这种持续演进的开源编程语言,甚至专门建立了一个 Proposal 仓库来追踪各种提案的设计、讨论、代码以及发布的情况,比如等了 10 年的泛型提案:

搞明白了架构模型和关键模块,真正打开源码时就能将包、文件名、接口等包含的知识与整体结构相互映射,在脑中形成一张完整的图。
其他的前置知识
有时候文档的作者还会加上不少前置知识,比如基于什么样的算法,受到了哪些知识的启发甚至是实现了哪篇论文的思想等等。
这些前置知识,对我们的理解会大有帮助。我们可以通过学习这些知识来进一步了解软件的细节设计。

上图是 etcd 的 github 页面,在显眼位置标明了它采用 Raft 共识算法,并链接到 Raft 算法的主页,如果我们没了解过 Raft,直接去读 etcd 的代码,很可能就对里面的选举、日志复制等概念一知半解,这就好像在看没有字幕的外文电影,精彩程度大打折扣。
3. 再读代码
看完了文档,就可以开始看代码了。为了防止在代码中迷失方向,我们可以遵循几条原则来阅读:
从入口开始
虽说通过架构模型以及包和文件划分的关系,我们能大致确定哪些代码是核心代码,但从入口处开始看会更符合大脑的思考方式。
因为入口代码的工作一般是先对各种模块进行初始化,然后调起主线程或者启动主服务,这种明确顺序的简单工作让我们不会一开始就遇到困难,循序渐进的过程更容易让大脑产生奖励。
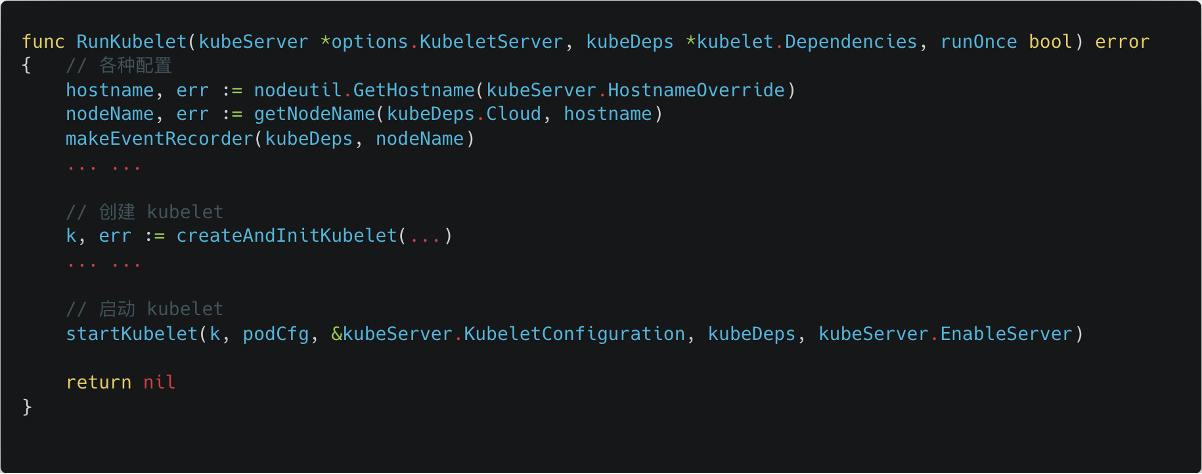
如图所示是 kubelet 启动入口简化后的主线逻辑,非常清晰。以此为起点沉下去,就可以分三路去细看配置详情、创建 kubelet 的详情,以及启动的详情。
抓住主线,从抽象到实现
主线就是从输入是怎么样一步步产生输出的。在这一过程中,会涉及到多个模块,每一个模块又有自己的输入和输出。
当我们顺着函数调用、数据传输方向一步步向下时,随着抽象层次的不断降低,涉及到越来越多的细节,这个时候应该及时折返,不要一路看到底,很容易迷失在里面。
良好的设计会有合理的抽象,根据不同的开发语言,我们可以通过查看包、接口、特性、公有方法列表、头文件等等来快速获取抽象信息,逐步地拼接出程序主线。搞清楚了主线,再逐步将抽象展开,阅读具体实现代码。
仍以 kubelet 为例,kubelet 作为负责整个节点运转的核心,工作多且杂。
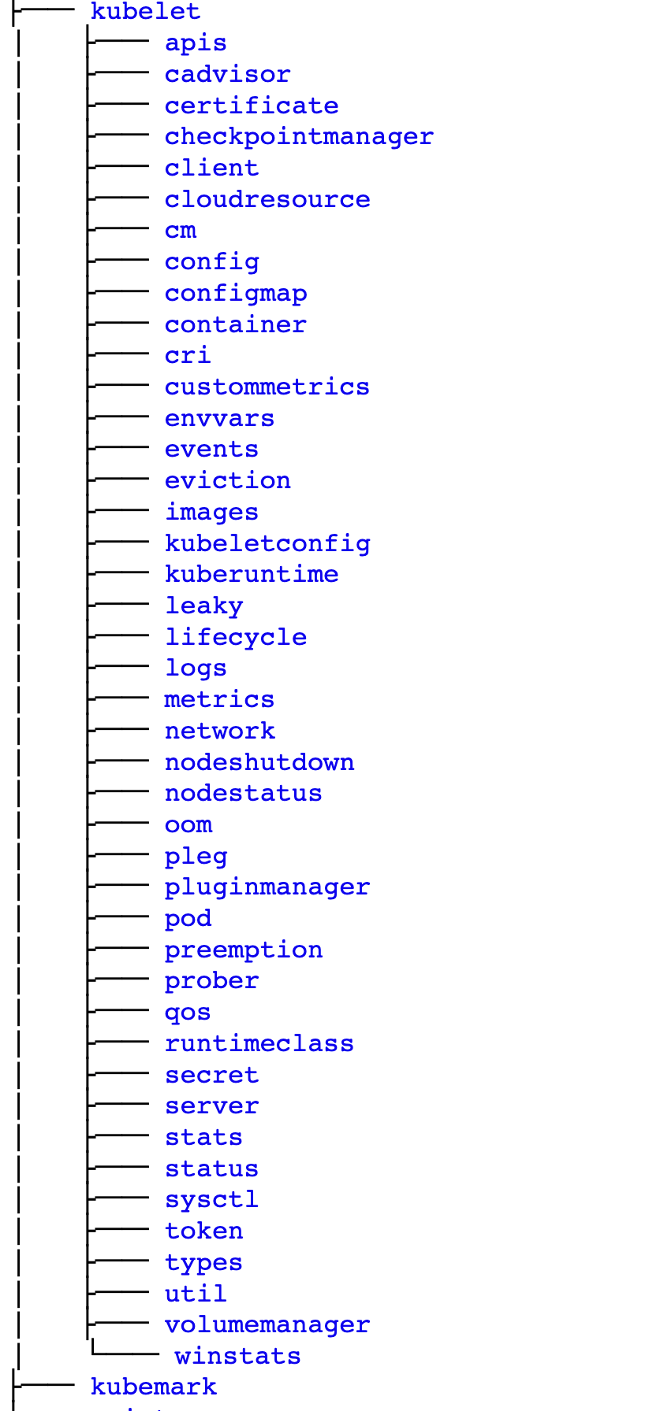
但看它的代码分包结构,非常清楚地将不同功能点划分到不同目录下,结合初始化逻辑,再进一步深入到每个功能目录内,又可以发现 kubelet 的模块设计遵循的是多个 manager 围绕着一个核心共同协作的模型。好的抽象,就像一颗洋葱一样,层层分明。
一边阅读一边记录
初识一个项目,对结构和流程把握的不会太清楚,因此一边读一边写写画画是很重要的。
有的时候跳转次数比较多,前面看过的东西后面就忘记了,所以对关键路径,记录具体的函数名、模块名,能帮助我们快速回溯到入口。
也有的时候遇到了需要拓展的知识盲区,为了不打断主线思路,可以先记录下来,找其他时间再学习。
另外,遇到不直观的、难以形成概念的代码表达,翻来覆去的看也看不懂,这个时候就需要画个图来帮助理解了。
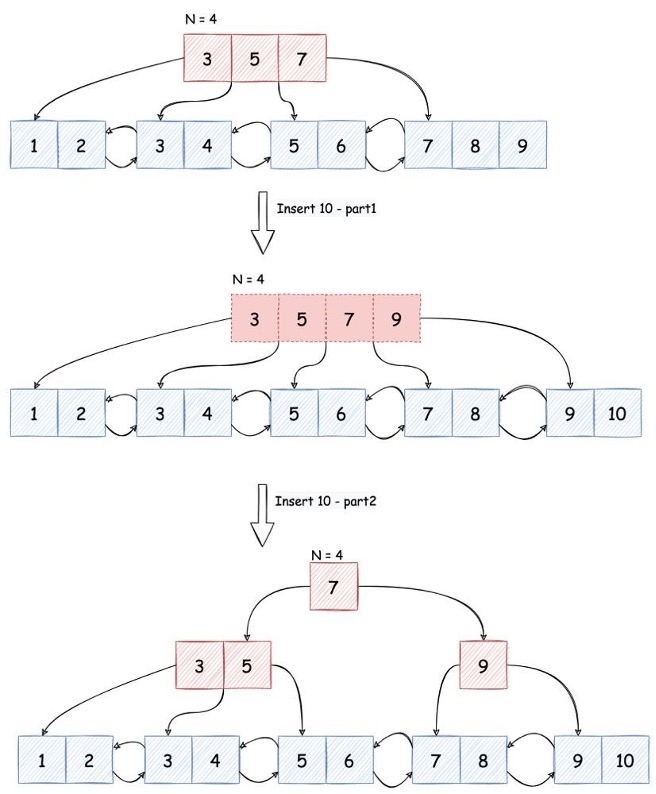
一个典型的例子就是在学习 B+Tree 的分裂、合并、上移下移的时候,全看代码特别不直观,想要理解这类内容画图定有奇效:
必要时借助 debug
有一些代码为了正确性、性能等考虑,其表述可能会让人百思不得其解。人类的思维方式是偏向顺序的,用软件开发做类比就是,我们更容易理解 Happy Path,而忽视分支细节。
当横竖想不通某段代码为什么要这么写的时候,实际运行一遍,加断点 Debug 一下可能就会发现真实的原因了。
一个有趣的例子是:在环形队列中,判断队列是否为空需要看头指针和尾指针是不是已经重合,下图的代码来自一个无锁环形队列的判空实现。

道理上讲,环形队列入队 tail++,出队 head++,先有入队,才会有出队,所以 tail 一定比 head 大。那为什么上面代码里,除了判断 tail - head == 0 以外,还一定要加上当 tail < head 时也认为空呢,这根本不可能发生啊?
实际的原因是,由于该环形队列是无锁的, tail 和 head 之间不保证任何同步,那么就可能由于调度因素,导致不同线程读到不同时刻的值,结果 tail < head 就真的产生了。
想要搞清楚这种场景,最好的办法就是真正执行几百万次测试,通过条件断点让代码在发生 tail < head 时停住,再观察内存中的值来解释。
4. 写篇文章讲讲整个设计
代码看个七七八八,差不多就对设计和实现都有一定的认识了。这时候心里多少会有点冲动想要把获得的知识讲出来。那么最好就是写篇文章,写文章可以对知识进行梳理,在写的过程中也会不断加深印象。随着文章的撰写,作者的设计意图亦会越来越清晰,对软件的理解也会越来越深刻。
整理大纲
写文章,目录最关键。一篇文章是不是有逻辑性,结构是不是清晰,全都在大纲的设计上。
既然我们的内容是讲软件的设计与实现,那么文章的大纲就可以按 Why - What - How 来展开:先告诉读者为什么要设计该软件,它解决了哪些问题。之后讲述软件的架构模型、关键模块以及主线流程。最后详细地讲解具体实现。
在写文章之初,我们的知识还不够深入和整体,可以先写 what 和 how 的部分,加深理解之后,就能明白设计的 why 了。
以我写的一篇介绍 Go 语言 Runtime 计算模型设计的文章目录为例
最后祝愿所有读者都能从代码中获得最大的乐趣。

可见大致就是按照 “设计意图和目标 -> 核心概念解释 -> 具体实现 -> 总结拓展” 这样的顺序来设计的整体文章结构。这种结构清晰、简单明了的目录结构很适合用在技术文章上。
描述设计原理,通过画图帮助分析设计意图
在介绍原理和实现的时候,相比于贴代码,更好的方式是通过画图来表达。代码的确能体现全部的设计细节,但代码更重要的任务是作为知识和硬件指令之间的桥梁。相反,如果我们用图表的形式表达设计意图,就会对人类更友好,更容易阅读、理解和学习。画图本身也是一种加深理解,去粗取精的过程。
下图是我读了 leveldb 之后画的 leveldb 存储架构图:
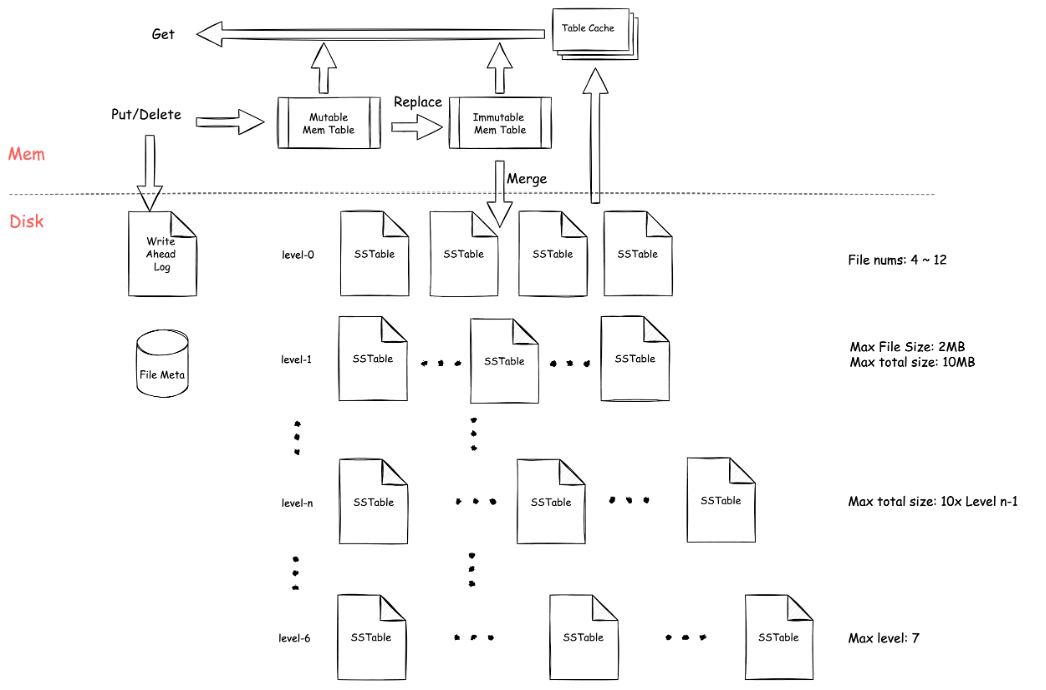
作为存储引擎,LSM Tree 的实现是 leveldb 的核心,leveldb 本身源码已经很清晰、简洁,但如果通过上面这样一张图来讲述其 LSM Tree 的具体设计,一定会比贴代码要易懂得多。
想一想,为什么要这么设计,好处在哪里?
当我们能用图表和文字来表达出软件的完整设计后,我们对代码的理解已经比较透彻,甚至,让我们自己来照着写一个新的也不是不可能了。
这个时候,就应该进一步的思考,如果是我自己来解决问题,我会怎么做?我能比原作者做得更好吗(通常不能)?
在思考为什么这么设计的时候,如果相关领域知识不充足,就会驱使我们去查找很多参考资料,了解和借鉴别人看问题的角度。找资料的过程总有惊喜,如果能读到一些非常深入浅出的文章,而后就会怀着敬佩之情,收藏、关注作者的博客,想想如果不是因为读了某段代码,还真无缘遇到这些精彩的文章和优秀的作者。
我在读 Go 语言内存管理代码的时候,一开始搞懂了 tcmalloc 的原理和实现,但对其所谓线程缓存、无锁分配等等卖点理解不深刻。直到回过头去读了 CSAPP 动态内存分配的章节,又结合 ptmalloc、jemalloc 的设计,相互对比理解,这才更清晰的认识了 tcmalloc 的设计决策。
经过这一阶段的思考并结合其他人的理解之后,我们就能清楚地意识到,软件所面临问题的限制条件是什么,作者这样设计的好处有哪些。把这部分写完,添加到文章的最开始,就比较完美了。
这一节讲了一点关于写文章的内容,对于技术写作,推荐 Thoughtworks 洞见团队出品的 《技术写作手册》。
5. 讲个 Session,收获 Extra Bonus
如果还有精力和兴致,那不如把文章的内容提取出来做个 Session 讲给大家,额外的付出能收获额外的奖赏。
有过做讲师经历的同学肯定会知道,给别人讲东西,收获最大的不是听众,而是讲师本人。想要输出一小时的 Session,所花费的准备时间可能要十个小时。我们需要花费数倍于讲解的时间来完善素材,理清思路,准备问题,甚至还包括思考可能会涉及到的拓展内容。做这些工作在提升我们 session 质量的同时,无形中也不断地强化了我们对相关知识的认知。
梳理要点,逻辑自洽
一个 Session 成功的基础在于能不能逻辑自洽。而逻辑自洽的前提就是关键要点必须清晰,并且前后可以呼应。
上一节提到的文章,正好就是 Session 材料的源泉,因此我会反复遍历整篇文章,期望从中抽取所需的内容。这个过程往往伴随着不断地发现文章的内容缺失、逻辑不通之处,这时文章就得到了进一步的改善。所以经常发现,当整个 Slide 完整的顺下来后,不仅成就感爆棚,文章也丰满了,理解还更深刻了。
去粗取精,锻炼表达
相比写文章,讲 Session 要我们进一步的去除细节,只保留最核心的思想,这本身是对抽象能力的一种锻炼。
另外,自己了解清楚,和能给别人讲清楚是完全不同的两种概念。如何能把核心知识讲给听众,并且能让听众更容易的听懂,需要仔细地思考语言的表达。每一次成功的 Session 都是对自己表达能力的一次提升。
表达上最常见的问题就是照着文字念。我个人喜欢通过减少 Slide 中文字的数量,来倒逼自己提升表达的逻辑性与连贯性。可以尝试思考,如果内容只是一张图,那么要怎么讲清楚这张图,用这种办法训练表达能力。
揣摩听众感兴趣的方向
考虑听众的感受也很重要,如果讲的内容大家不感兴趣,不爱听,或是晦涩难懂,跟不上节奏,就容易导致整个 Session 反响寥寥,大家会觉得来听你的 Session 浪费了自己的时间。
所以不仅要能讲清楚,还要揣摩听众感兴趣的方向。合理的设置内容,去除枯燥乏味而非关键性的东西,并且调整讲解的顺序,把易懂的、精彩的部分穿插放置,这样就可以不断地激发听众的兴趣。
最后,线下组织的效果要比线上视频讲解好得多。在线下听众的注意力更集中,互动效果好,演讲者也更容易通过听众的表情、神态来判断是否需要调整内容和速度。如果因为条件限制一定要做视频 Session,那么可能需要经常停顿下来问些问题,或是主动的寻求反馈。
6. 结语
本文是我日常读代码的一点经验,总结下来,就是要
- 仔细地选择学习的项目
- 先通过文档了解全景,再逐步深入代码;
- 找对抽象和边界,能帮助我们建立思考模型;
- 写篇文章讲述代码的设计,是深入理解代码的好办法;
- 自己学会了还不够,能清楚地讲给别人才是真正的掌握。
免责声明:本文内容仅表明作者本人观点,并不代表Thoughtworks的立场