














AI and ML
Intelligent risk and compliance


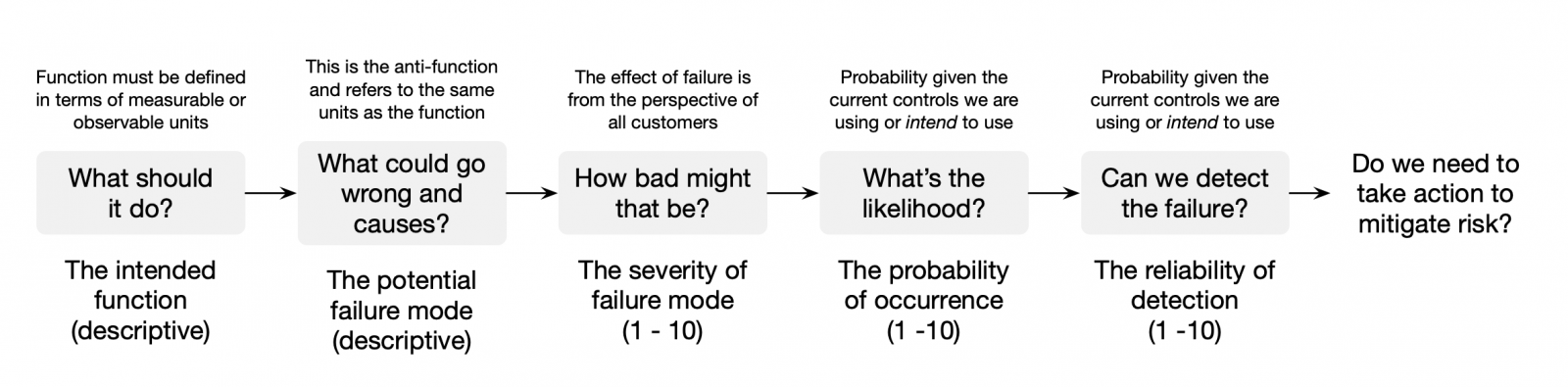
Criticality (C) = Severity x Occurrence (SO)
Risk Priority Number (RPN) = Severity x Occurrence x Detection (SOD)
These questions prompt us to consider the conditions in which the system and its functions need to operate and the noise factors that the system will be subjected to.
Noise factors are anything that interferes with a system performing its normal, intended functions and can include things like unexpected loads from other services, security patching and updates, hardware faults and failures, and denial of service attacks. With a little imagination, we can quickly develop a list of noise factors that we should consider when making decisions that affect how the system is built and operated.
Where we are able to identify the possible causes of a serious failure, we can introduce or improve controls that work to prevent the cause from occurring in the first place. And where a failure is potentially catastrophic, we should consider both controls to prevent the failure and controls to detect it as early as possible so that we minimise the chance of the failure affecting customers.
Let's use a simple example to illustrate the difference.
If a specific function of a software component is to provide secure authentication between a user and a service, there is a risk of the loss of integrity of the user's authentication information (the potential failure of the function of the component). One possible cause of the loss of integrity of the users' authentication information could be determined to be no, poor or incomplete encryption of information in transit.
Therefore, a decision is made in the design phase to use a security certificate issued by a Certificate Authority for end-to-end encryption of the user's authentication information. Based on the decision to use a digital certificate (the intended design control), the risk of the likelihood of the potential failure occurring is then evaluated using the rating system. Further mitigation may be required as a result of the evaluation if the risk is deemed too high.
Correspondingly, in the operation of that same function in the run environment, the same failure is considered (the potential loss of the integrity of the users' authentication information) but in this case a possible cause of the failure might be determined to be an expired security certificate (no encryption).
Assuming there are no existing controls in place to address this risk, the risk of the expired security certificate could be mitigated by the planned introduction of an automated check and notification script to flag a certificate when it is less than 1 month from expiry. The service management plan would need to be updated to incorporate the new control.
When failures do occur in live systems, proper problem solving (with deliberate root cause analysis) can be used to feedback information to improve future risk analysis. Actual root causes of failures are found and verified and the knowledge can be used to inform future decisions at risk of similar failures.
This information becomes proprietary knowledge about how systems actually work in the real world and it increases the accuracy of predictions of future failures for better decision-making and better delivery and run controls.
The knowledge must be centrally stored within the organization and must be accessible for use in all new projects and incidents. Over time and across projects, this knowledge grows and is supported by real-world experience. This, in turn, reduces risk and increases the resilience of systems that we build to survive in the wild.
Risk needs to be deeply understood, both from the perspective of how design decisions we make create risk and how we manage risk once a decision is made and the risk is built into a system. Like problem-solving skills, risk-based failure modelling skills are essential to anyone involved in architectural and engineering decisions and product build and run. The better we understand how what we do affects risk, and by extension, the experience of the customers who use the systems we build, the more robust, reliable and resilient we can make those systems.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

