














Generative AI
Evaluating LLMs using semantic entropy

Semantic means understanding the context, the meaning of the language. Semantic search refers to search which isn't just based on keyword searches but also understands the meaning of the query and the documents from which the required text is to be retrieved.
The more our models can understand the semantics of the language, the more effectively our query will be successfully answered, with the model able to retrieve relevant text from the documents.
Semantic search plays an important role in various businesses and technical use cases, including search engines and e-commerce platforms like Amazon.
The basic idea behind semantic search is to develop embeddings of the text — ie. sentences or documents — and store them as a collection of vectors. At the time of inference, when a query is given as input, we embed the query and find the text which is most semantically similar to the query. Cosine-similarity is one such metric to quantify semantic similarity.
But there's also a little more to it: this is where retrieval systems and rerankers come in.
Searching a large corpus of text can be time-consuming and computationally intensive. To optimize this process and make it more efficient, we need both a retriever and reranker.
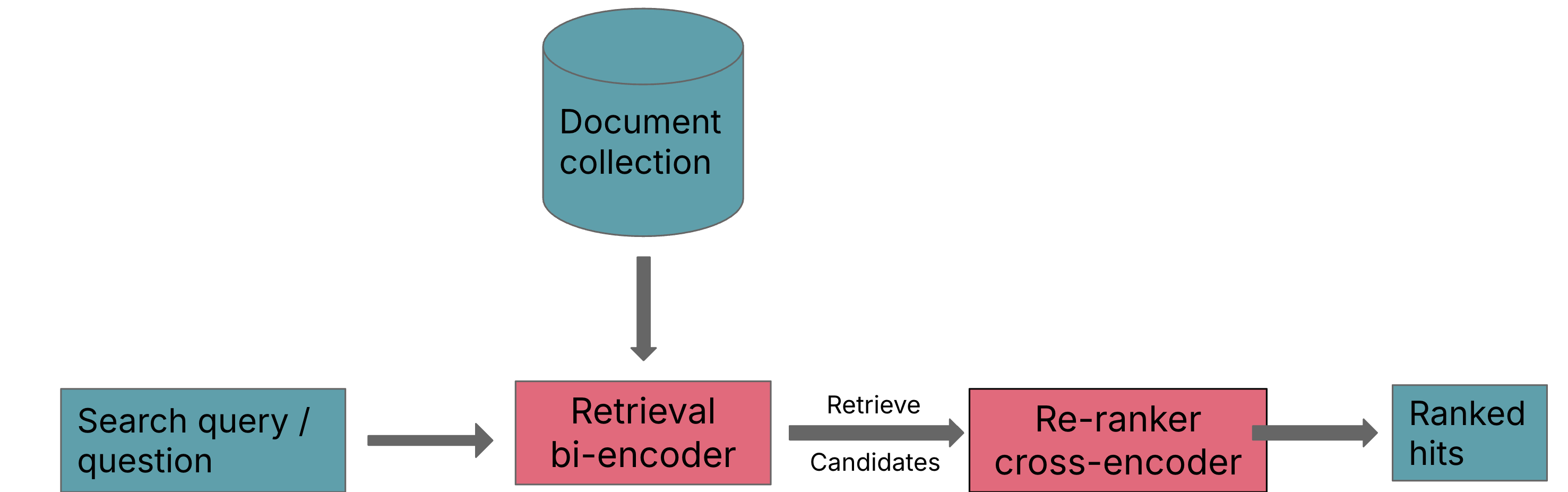
Let's take a closer look at what a retriever and reranker actually are.
We have a search query — that query is embedded in the vector form. We also have a text document in vectorized form too. These embeddings could be developed using Sentence Transformer models — currently a state-of-the art model architecture. These vectors are then passed to a retrieval system which calculates semantic similarity based on cosine scores. It then outputs, let's say, top 32 possible hits which are relevant to the query.
It might be possible that certain documents also come up in the results delivered by the retrieval system which aren't that relevant to the query text. This is why it's important to rerank our output from the retriever.
A re-ranker based on a cross-encoder can substantially improve the final results for the user. The query and a possible document are passed simultaneously to the transformer network, which then outputs a single score between 0 and 1 indicating how relevant the document is for the given query.
So from the re-ranker we get a smaller subset of candidates of documents which are relevant to the query.
There are various sentence-transformers-based models trained on large datasets from Google, Bing, Yahoo search queries which could be used to develop embeddings of text, and then various Cross-Encoders which could be used for Re-Ranking.
Originally published on Medium
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

