














Mobile outreach is becoming an essential part of every organisation's digital strategy. Mobile product owners are losing sleep over constant churn of UI refinements, OS releases and additional hardware support that we have been seeing in Android and iOS. If a business is spread wider than those two mobile platforms, things get even more complicated.
According to Wikipedia, the Android team has been releasing two new OS versions every year consistently for the last three years. Some of them are major UI upgrades. Alongside of this, iOS is rapidly evolving with new OS releases announced every June. We have not even taken into account rapidly increasing diversity in the type of mobile devices: mobile phones, car navigation systems, watches, and televisions to name just a few.
Being pressed against timelines means that if development teams don’t stay nimble and agile it can severely undermine the quality of the apps that ship out. Using Mike Cohn’s idea of Test Pyramid that has been elaborated on by Martin Fowler on his blog here, we have built several layers of safety nets for our mobile app. Our current suite includes a mix of unit tests, service tests and behavior tests. All of these have a specific intention, execution style and coverage.
Among all these, behavior tests are most notorious for being brittle and a maintenance overhead. We have experimented a bit to evolve into a structure that we find more fruitful, stable and effective. In this post I intend to elaborate on some of those aspects. Here is a bit of context around our technical setup.
Android and iOS are our primary platforms of choice and we build native apps for both platforms. We use calabash-ios and calabash-android for writing behavior tests. Both the tools are based on principles of behavior driven development (BDD) pioneered by Dan North and Chris Matts. Calabash also has support for cucumber, which allows these tests to be developed in natural english like language syntax aimed at non technical folks. With that context, lets dive deeper into the aspects that makes behavior tests behave.
Classify by Frequency and Intent
While BDD is a compelling approach to write behavior tests, do not mistake its readability for its robustness. Behavior tests are written at a very high level and are extremely slow to run. This is even more so for mobile devices since it requires booting up a device with an app deployed before tests can run. A sizable suite of behavior tests can often take up to 45 minutes or more to run across platforms. So the first important lesson is to clearly distinguish between what should be part of behavior tests and what shouldn’t be.
Unit tests are robust, fast and atomic in unit. Behavior tests are not. We often classify end-to-end, happy path scenarios as part of our behavior tests. These tests are further sub-divided into “smoke”, “regression” and “everything else” categories. I would encourage you to form a categorization that makes the most sense to you as a team.
Smoke tests are triggered on a developer’s machine right after a unit test run with the help of a pre-commit hook before pushing code to source control. These are key happy path flows. A bit of intelligence in the pre-commit hook can help you limit these tests to the flows that were actually changed thereby reducing the number of scenarios that need to run.
Regression tests on the other hand are a chunkier set of tests. They run at periodic intervals and are slowest to run. Their intent is to verify all possible navigation paths of the app.
Everything else in our context is a set of remaining happy path scenarios that guarantee the well being of an app for most used features and flows. These run on our continuous integration server post a commit to source control.
Striking a balance between all three is important since the trade offs are quicker feedback cycle versus absolute coverage of functionality. I would also encourage to push things down to unit tests instead wherever possible.

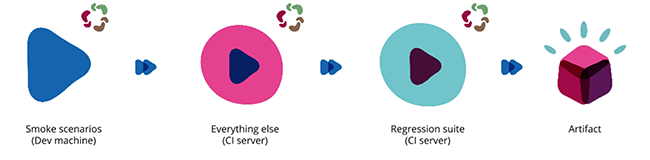
[Test classification by frequency and intent]
Abstraction and Code Organization to Reduce Effort
Both calabash-android and calabash-ios have similar programmatic apis to tap, touch, scroll and pinch/zoom. However, they are not uniform in naming and implementation underneath. This difference makes it hard for both of them to be used agnostically. We have built a lightweight abstraction layer. It leverages a factory pattern to inject a wrapper that exposes both the frameworks in a consistent API format. This helps us choose one of the two frameworks dynamically at execution time and write layers on top. With that design our code can be agnostic of the framework used underneath.
The biggest advantage of this approach is that we write our tests only once for either of the frameworks. Since most of the navigation styles across platforms is same, the same tests run seamlessly across Android and iOS.
Of course, this is based on an assumption that app navigation and other fundamental aspects are similar across platforms apart from minor platform-specific quirks. In some cases the abstraction layer handles these differences. For instance “back button” in Android would trigger a “hardware back function” but in iOS it would use “back button on top navigation bar”. If there are metaphors/flows specific to platforms, it is easy to create a structure that allows a platform-specific step definition.
So, in summary, we write our tests for one platform and run them on both with an abstraction layer in place. I would encourage you to do so as well and leverage an abstraction layer to build an underlying uniform interface across both platforms.


[Building abstractions with unified interface]
Page object pattern for structure
Cucumber has a concept of global state which is typically accessed by all tests rampantly. This is significantly detrimental to the overall health of the behavior tests and results in a spaghetti code base quickly. We use the Page Object pattern to bring structure and predictability in our tests. This helps us define a few conventions and curate them better over a period of time. It also helps in reusability of steps and flows across tests. Here’s a simplified explanation of page object in terms of web apps by Martin Fowler. There’s another example worth looking at here.
Frequent Mock Runs and Manually Triggered Live Runs
Teams often misuse behavior tests by using them as service tests and thereby placing an overarching responsibility of something that they are not intended for. Running behavior tests against a live API can cause them to be brittle with non-deterministic results. Remote services could perform slowly or be unavailable altogether leading to wasted developer hours in debugging.
The value provided by behavior tests lies in the validation of the app behavior for a given API response. We use HTTP service mocking tools like Stubby and Mountebank to stand up independent endpoints that serve a designated response for a specific request flow. We invest time in building flows with mocks for the first time. Once these mocks are ready, we run our behavior tests with no external factors affecting their stability. They are faster, more robust and effective.
Running behavior tests against live services is a common source of recurring failure, a red herring and a maintenance overhead. We create only a minimalistic set of tests that verify basic happy flows end-to-end against a live system. These are triggered manually, often before we push out a new release. For such tests, data for mock and live environments is externalized and is swappable using configs. This allows injection of mock data for assertions when running against mock endpoints or injection of real data for system assertions when running with live system.
On our project we run a service job ahead of the manual run to delete residual data and reset other data elements to the extent possible, on live systems. Tests are run against mock endpoints on the CI server with every code commit, whereas they are only run against the live systems when triggered manually.
However, I would like to caution you against going down the road of running behavior tests against live services. We have had more pains than benefits with it. A more reliable approach is to invest in a more exhaustive test suite that runs against mocks, and complement them with a service test suite that validates contracts via direct calls to web services.


[Running against mocks versus live services]
Constant Refactoring
Finally, nothing ever replaces the benefits of constant refactoring and constant curating of tests. It’s crucial to hold periodic refactoring sessions to identify and improve parts that could use some refactoring to keep up with the pace and burden of growing code.
An apt analogy of automated tests that I read a while back compares how the utility of brakes in a car are not to slow a car down; instead to let a car go faster with confidence knowing we can stop when we need to. It is imperative that we remember that some of these safety nets are a considerable overhead when you need to build them. But it is the benefit of speed in long term that we need to appreciate as a team.
I would love to hear about your experiences around implementation of similar safety nets in your team.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.