














Continuous delivery
Getting Smart: Applying Continuous Delivery to Data Science to Drive Car Sales




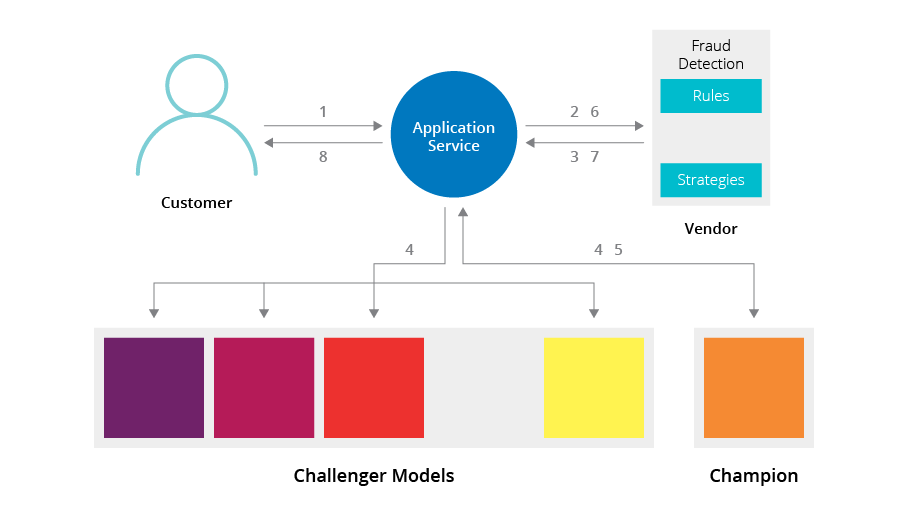





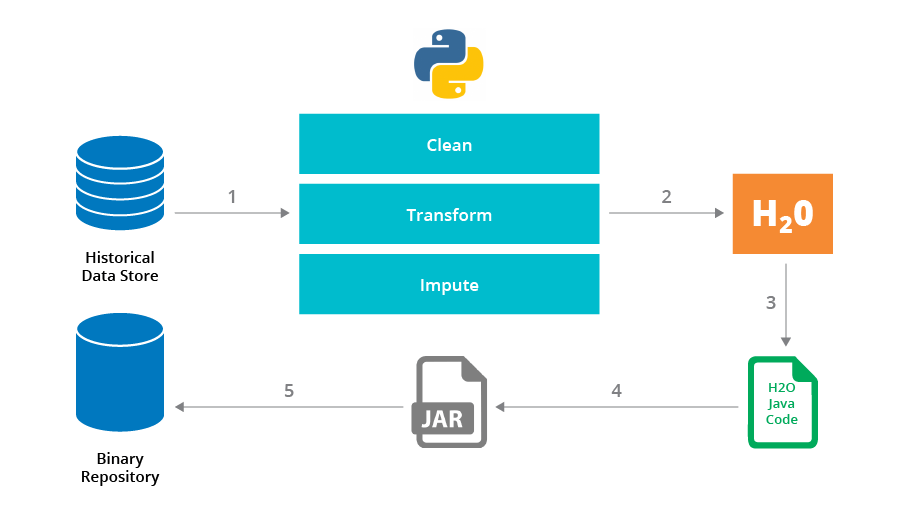



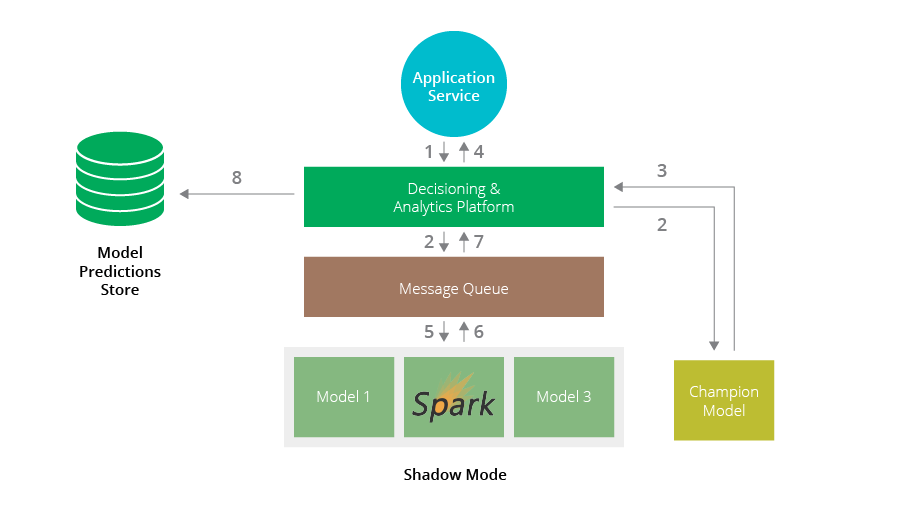


Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

