














Digital innovation
What is Intelligent Empowerment?


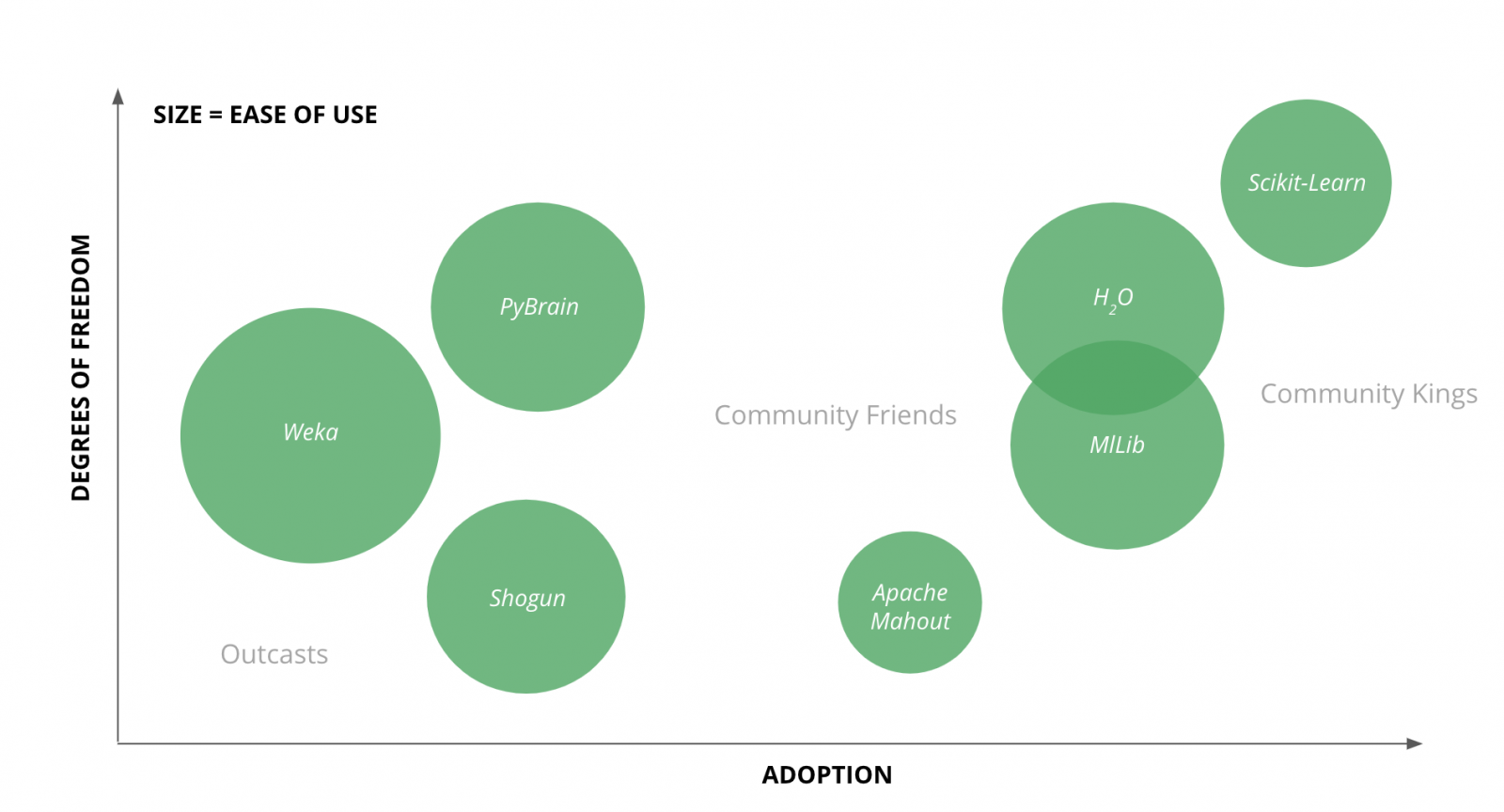
A few broad observations -
For those of you whose main concern is the tech/tool’s scalability, this perspective of the landscape could help -





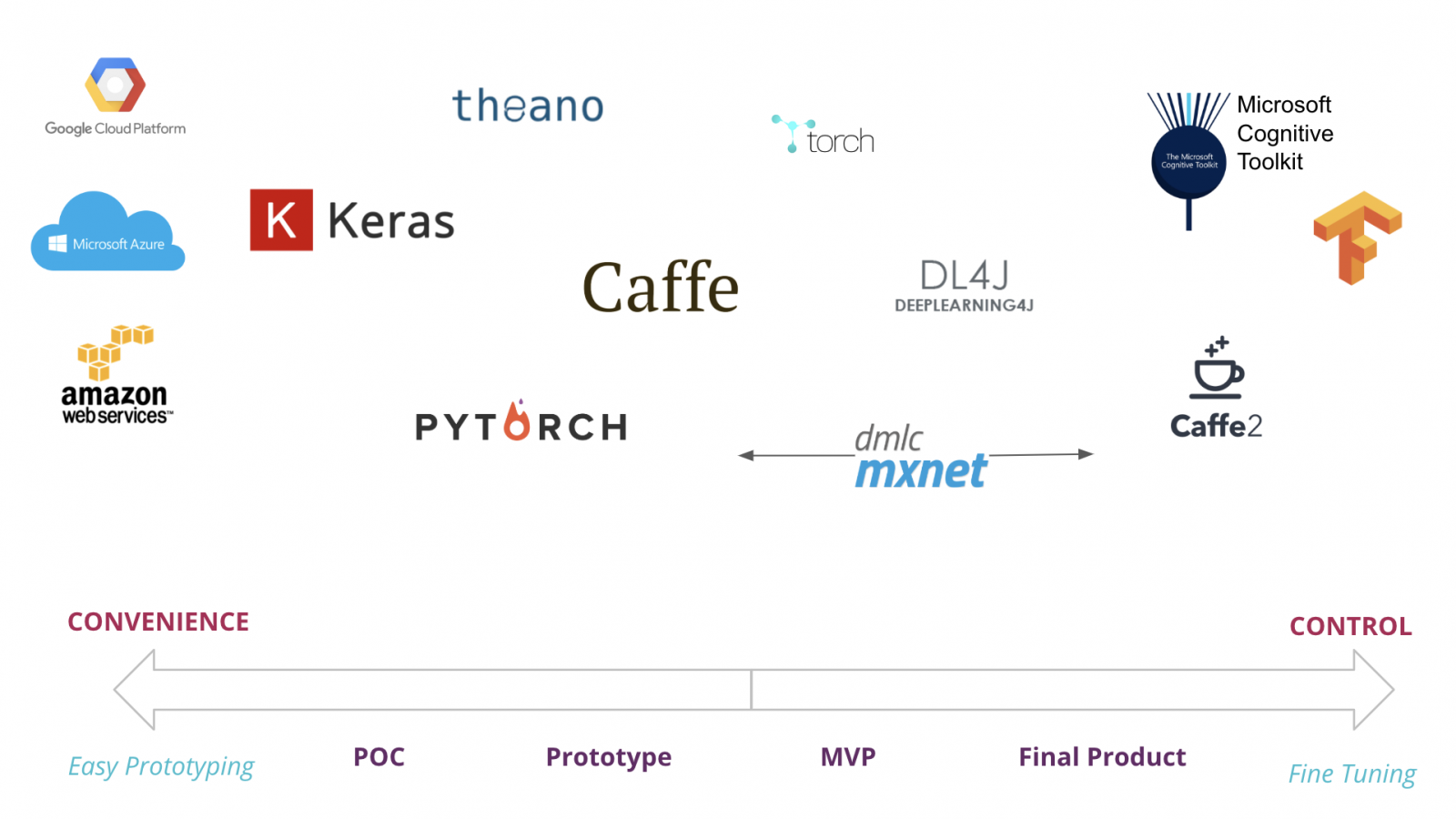 Deep Learning tech plotted during a project’s life cycle
Deep Learning tech plotted during a project’s life cycleDisclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

