














In this first of a six-part series we'll do a deep dive into doing Continuous Delivery with Go
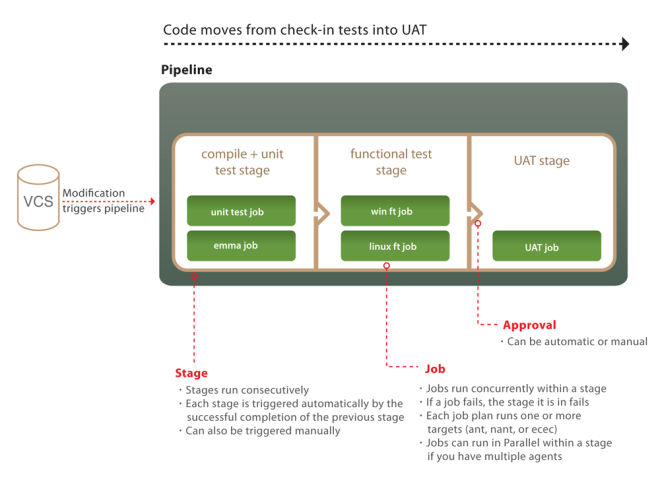
The official Go documentation explains some key concepts with the help of a nice diagram:

Here is another clickable diagram that tries to tie in other important abstractions in Go.

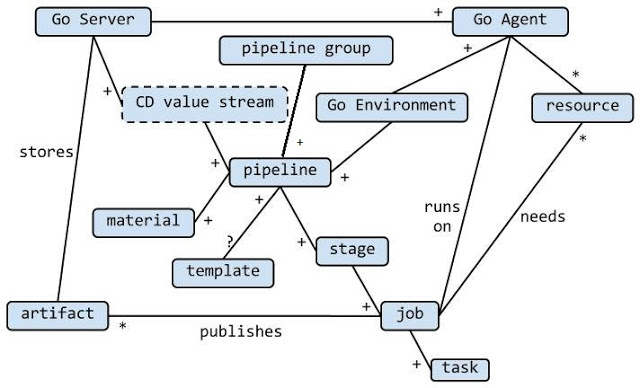
Briefly, a pipeline may be based off a template. Materials refer to source code repositories or other pipelines. A pipeline group is a grouping of pipelines for administrative convinience. It is useful to think of a directed graph of pipelines (say from build to functional-test to integration to performance to QA to UAT to staging to production) as your continuous delivery value stream. An environment represents a ring-fencing of agents and includes one or more pipelines. The unit of work is a job. Jobs may be tagged with required resources so that they run only on correspondingly tagged agents. Jobs can be made to publish artifacts that are then stored on the server.
At first blush, it may appear overkill to have four levels of abstraction (pipeline, stage, job and task) for work execution. But the moment you start doing more than single team CI, they become indispensible. For instance, it is trivial to set up an integration pipeline that feeds off three upstream component pipelines and also feeds off a integration test repository. It is also easy to define different triggering behaviours for pipelines and stages. If we had only two abstractions, say jobs and stages, they'd be overloaded with different behaviour configurations for different contexts. Jobs and stages are primitives, they can and should be extended to achieve higher order abstractions. By doing so, we avoid primitive obsession at an architectural level.
Also note that multiple instances of a given pipeline can run in parallel. Stages within a pipeline run in sequence. Jobs in a stage can run in parallel. Tasks within a job run in sequence. This alternating behaviour is designed deliberately so that you have the ability to parallelize and sequentialize your work as needed at two different levels of granularity.
In the next part, Part 2 of "How do I do CD with Go?", I delve into Pipelines and Value Streams
"How do I do CD with Go?" blog series:
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.