














Generative AI
Evaluating LLMs using semantic entropy

Min-\(\rho\) sampling is an MIT-licensed technique — a Thoughtworks AI researcher is one of the authors of the research that developed it. Thoughtworks is also the first organization to integrate it in a client setting.
At the core of LLMs is their ability to predict the next correct word (or token) to their previously generated output in response to the input provided. The input content gets converted into tokens and then into embeddings; at the output layer, the embeddings get reconverted into tokens.
The challenge, for the model, lies in the process of identifying the right token as an output for a given input. This process is statistical and stochastic in nature. It’s called sampling. In other words, LLMs generate text by sampling the next token from a probability distribution over the vocabulary at each decoding step.
Sampling is a strategy to help the model pick a word from the list it's given. If it chooses only the top options the output will be fairly safe but not very creative; choosing randomly from the whole list, meanwhile, can lead to deeply chaotic outputs. chaotic. The magic, when it comes to LLMs, lies in the middle. Striking this balance, however, isn't easy.
One solution is min-\(\rho\) sampling, a stochastic technique that varies its truncation threshold based on the model’s confidence, making the threshold context-sensitive. The thresholds are relative and depend on how certain the distribution is for that token.
Min-\(\rho\) sampling is a response to the limitations of existing sampling techniques. Before getting into the details of min-\(\rho\) sampling, let's take a look at established approaches and why they often fall short when it comes to LLMs.
Greedy decoding and beam search are independent and commonly used quasi-deterministic techniques designed to select the most likely next token at each step during text generation. Both techniques prioritize the highest-priority choices, which means they can miss more diverse and highly creative outputs.
Temperature is a kind of a risk controller. Low temperature makes the model play it safe, while high temperature encourages it to take risks and explore less likely words for more creativity.
Top-\(\kappa\)(stochastic) sampling is a family of techniques. Top- \(\kappa\) sampling selects the next token from the \(\kappa\) most probable candidates at each step of generation, but the technique doesn’t adapt to changing levels of model confidence — with low \(\kappa\) -values, the model becomes overly conservative, which limits its creativity. At high temperatures, it generates noisy and incoherent outputs.
Top-\(\rho\) (nucleus) sampling works by dynamically selecting the smallest set of tokens whose cumulative mass probability exceeds a pre-defined threshold: \(\rho\). However, the method can still produce repetitive and incoherent text, especially at high temperature settings. Lower “\(\rho\)” makes the output more conservative, whereas higher “\(\rho\)” invites the model to make riskier choices.
Dynamic threshold sampling adjusts the token threshold based on model confidence. This does, however, require careful tuning of model confidence. High temperatures (T>2) flatten the probability distribution, which means many tokens get similar (ie., low) probabilities, which can lead to degeneration, repetition or even nonsense — even with top\(\rho\)/top- \(\kappa\).
The graphic below provides a visual comparison of each of the above sampling methods:
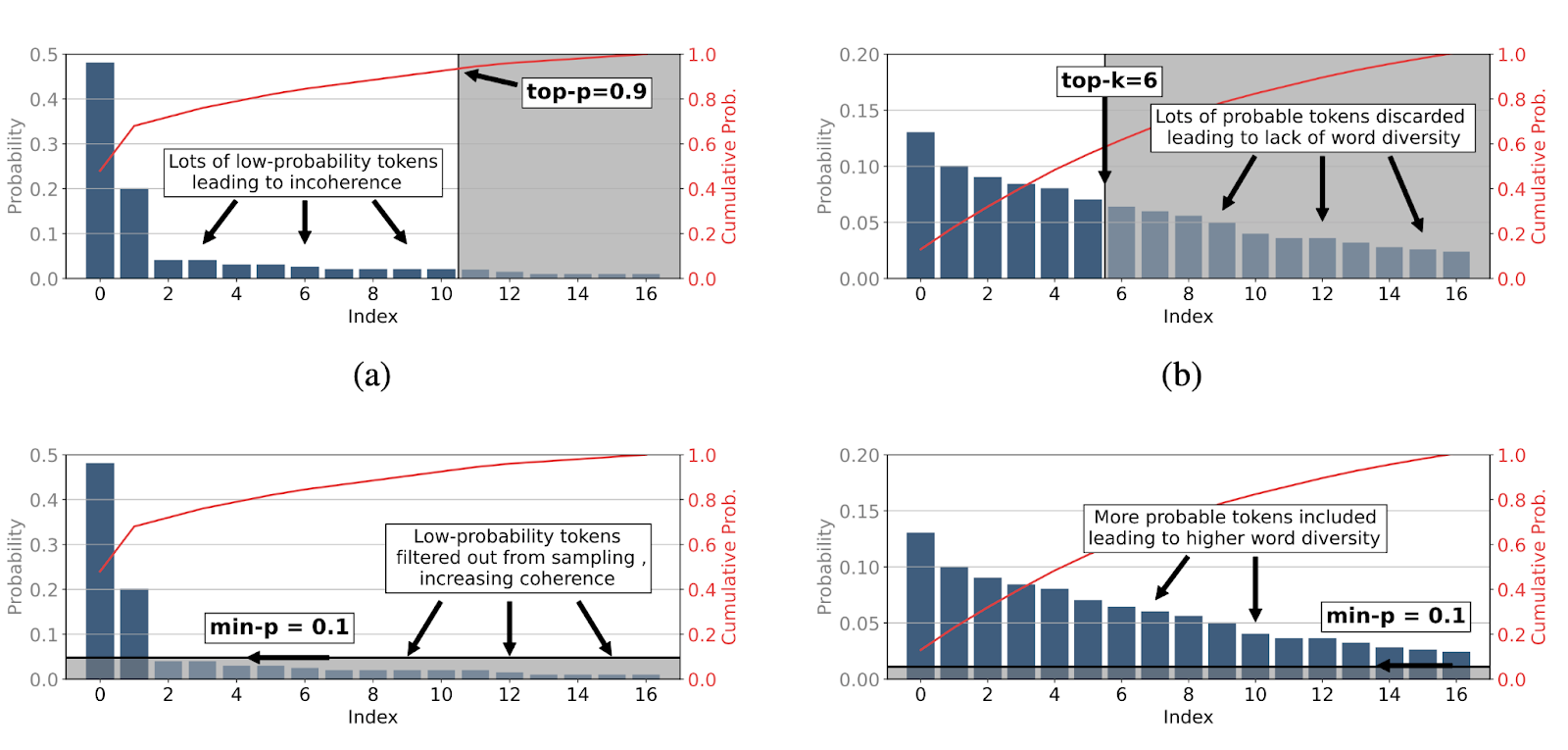
Figure (a) shows initial token distribution. Figure (b) shows top-\(\rho\) sampling. Figure (c) shows top- \(\kappa\) sampling. Figure(d) shows min-\(\rho\) sampling.
Considering all the drawbacks of sampling techniques discussed above, we want to introduce you to a new technique called “min-\(\rho\)” that dynamically adjusts the sampling threshold based on the model’s confidence at each step of decoding. Min-\(\rho\) sampling dynamically adjusts its threshold based on the model’s confidence focusing on likeliest tokens when confident and allows more diverse options when uncertain. This dynamic threshold balances coherence and diversity better than top-\(\rho\) and top-\(\kappa\) sampling.
The core idea is simple: stop using fixed cutoffs. Min-\(\rho\) sampling is a stochastic technique that varies its truncation threshold based on the model’s confidence, making the threshold context-sensitive. The thresholds are relative and depend on how certain the distribution is for that token.
Confidence is measured using the probability of the single most likely token, \(\rho\)_max. If \(\rho\)_max is high, the model is confident — this means we need to be more conservative. If \(\rho\)_max is low, the model is uncertain, so we can afford to explore more options. This improves sensitivity to context and uncertainty. On top of that, the technique balances coherence and creativity even at high temperatures.
By addressing the longstanding diversity-quality tradeoff, the min-\(\rho\) sampling technique represents an advancement in generative language modeling. It can enhance applications that require both high-quality and diverse text generation.


Min-\(\rho\) requires minimal changes to standard LLM decoding pipelines.
Min-\(\rho\) sampling has been implemented as a logits processor. A logits processor is a small, modular component in a language model decoding pipeline that adjusts the raw logits (the model’s unnormalized prediction scores for each token) before sampling or selecting the next token. It's like a “filter” for the model’s raw outputs before the selection of the next token is decided.
After applying temperature scaling, the scaled threshold is computed and tokens with probabilities below this threshold are filtered out before sampling. These operations are efficiently implemented using vectorized computations, which adds only a negligible overhead to the decoding process.

Min-\(\rho\) sampling has been integrated with widely-used open-source frameworks such as Hugging Face Transformers, vLLMs, SGLand and many other repositories. The code implementation is available on github.
Min-\(\rho\) sampling has a number of distinct advantages when compared to some of the techniques discussed earlier.
It balances creativity and coherence. The min-\(\rho\) technique adjusts dynamically the sampling thresholds to different contexts within the same generated sequence based on the model’s confidence in its outputs. The other techniques allow either overly diverse (incoherent) or conservative (repetitive) token choices in the token sampling pool.
It’s robust at high temperatures. The min-\(\rho\) technique scales the truncation threshold proportional to the model’s confidence, preserving output coherence at higher temperatures. This is valuable for tasks that benefit from higher creativity, like storytelling or content creation.
It’s simple. The min-\(\rho\) technique requires minimal computations, so it can integrate with existing LLM inference pipelines easily without substantial overhead.
The real advantage of Min-\(\rho\) technique is where “coherence” under “high temperature” is expected from the model.
Diverse reasoning paths. It can facilitate problem solving and brainstorming by creating varied output paths via adaptive temperature. By encouraging diverse reasoning paths, it can improve problem solving and brainstorming. Results show that min-\(\rho\) sampling at higher temperatures can outperform greedy decoding, achieving a better balance between diversity and accuracy than traditional deterministic methods.
Agent training and exploration. Recent research in reinforcement learning is using the min-\(\rho\) sampling technique to generate high-quality and diverse training data for curious agents. It was implemented with a temperature of 1.5 and a min-\(\rho\) parameter of 0.3 for the Llama 3.1-8B Instruct model. This demonstrates min-\(\rho\) ’s potential for improving reinforcement learning for agent exploration.
Red-teaming. It can generate diverse samples to help identify vulnerabilities.
Advanced reasoning models. Min-\(\rho\) sampling settings are recommended for DeepSeek-R1 implementations. The document by Unsloth (2025) specifies that a min-p value of 0.05 “helps counteract very rare predictions” particularly beneficial for their quantized 1.58-bit model. This demonstrates how min-\(\rho\) effectively balances token selection in both high-temperature creative settings and reasoning-intensive applications.
Today, min-\(\rho\) stands as one of the most reliable sampling techniques where high-temperature incoherence is a bottleneck. However, there are still many challenges that still need to be addressed:
Min-z and top-N techniques
While min-\(\rho\) shows considerable promise as an adaptive alternative to fixed top-\(\kappa\) or top-\(\rho\) sampling, it nevertheless has certain limitations. For instance, it relies on the mean logit value that makes it sensitive to skewed or heavy-tailed distributions. This means a small number of extreme logits can distort the threshold and lead to either over-truncation or under-truncation. Also, the thresholding mechanism in min-\(\rho\) provides only a rough balance between precision and diversity; it may lack the adaptivity needed for fine-grained control in dynamic settings. Recent extensions such as top-Nσ and min-z highlight promising directions: incorporating distributional spread and median-centered normalization yields more robust and information-efficient truncation, particularly in the presence of heavy-tailed logits.
Human evaluation scope
The min-\(\rho\) technique has gained popularity within the open-source community for creative writing tasks, where its value emerges most strongly in interactive, exploratory settings rather than static one-shot evaluations. This distinction suggests evaluation on dynamic platforms such as Chatbot - where users iteratively interact with models — may provide a more faithful measure of its practical utility.
Combining uncertainty and CoT decoding methods
Recent work on combining uncertainty with chain-of-thought (CoT) decoding highlights a complementary perspective: high-certainty token choices are most effective for producing accurate final answers, whereas more diverse, lower-probability tokens enhance the intermediate reasoning process. This distinction suggests a natural extension for future research — integrating min-\(\rho\) (and its variants such as min-z) with CoT-inspired decoding strategies.
Applicability to other domains
Extending min-\(\rho\) to other generative tasks, such as code generation or multimodal models, could reveal broader applicability and benefits across different domains.
High temperature regimes
High-temperature regimes remain comparatively underexplored, yet min-\(\rho\) sampling offers a pathway to unlock new opportunities for exploration, experimentation and application. Recent reinforcement learning research has begun employing min-\(\rho\) for trajectory data generation, highlighting its effectiveness in producing training data that’s both diverse and high-quality.
AI safety and interpretability. Follow-up research is required applying min-\(\rho\) technique to mechanistic interpretability for AI safety and alignment. Specifically, its use in uncertainty-aware generation, neuron activation filtering and structured latent selection to enhance model robustness.
Min-\(\rho\) sampling technique aims to improve the diversity and coherence of text generated by large language models. We acknowledge the following “ethical” considerations:
• Potential misuse. Min-\(\rho\) could potentially enhance the fluency of misleading or harmful content. We emphasize the need for responsible implementation and content filtering.
• Safety risks. Normally, increasing temperature makes text generation more random and diverse. A concern is that too much randomness could let the model “slip past” its safety fine-tuning, i.e., generate unsafe or restricted content it was trained to avoid. There’s currently no evidence that using Min-\(\rho\) technique creates this problem.
• Transparency. To ensure reproducibility and enable further research, we have open-sourced our implementation and provided extensive details on the experimental setup and results. Refer the Github link in the Code repository section above.
We believe the benefits of entropy and uncertainty-based methods outweigh these risks. We strongly encourage safety and alignment research leveraging uncertainty and entropy, as this can clearly benefit robustness, truthfulness, and reduced hallucinations
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

