














Privacy
Design thinking to increase information security and data privacy


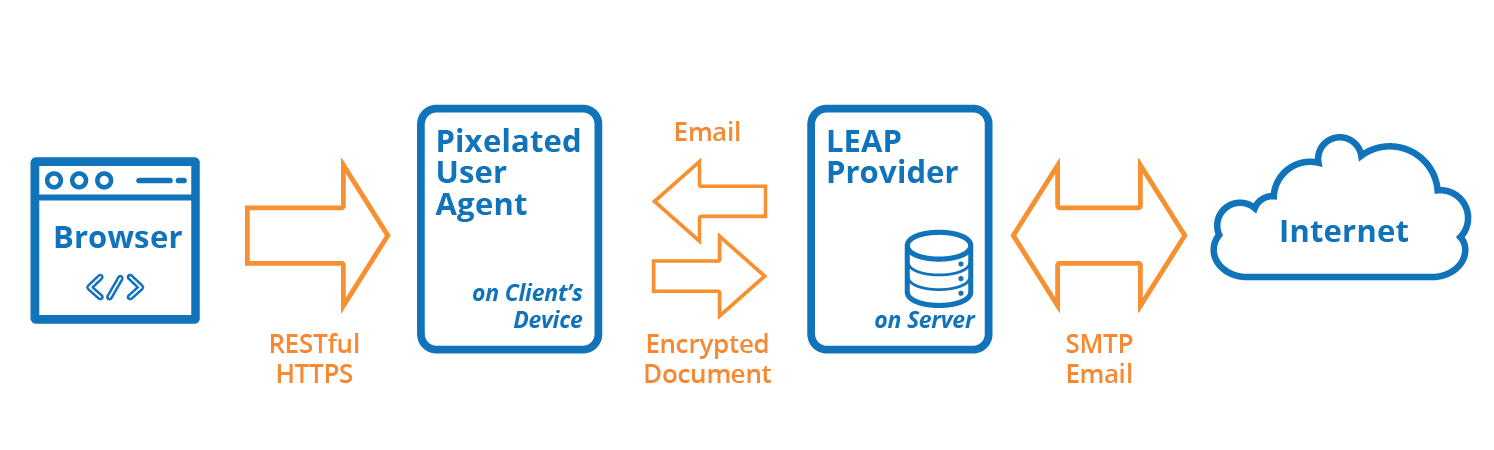 Figure 1: Client-side encryption
Figure 1: Client-side encryptionDisclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

