













Dados revelados em pesquisa realizada pela consultoria americana McKinsey em 2017 mostravam que, à época, as 500 maiores empresas no ranking da Fortune realizavam em torno de 400 milhões de decisões por dia. Muitas são estratégicas e requerem algum envolvimento direto, mas outras são mais rápidas e relacionadas à dinâmica do negócio, consumindo um tempo desnecessário dos gestores: um desperdício médio de 530.000 dias por ano em tomada de decisão. Do ponto de vista tático, a solução para evitar esse desperdício é a automação de grande parte das decisões com o uso de Inteligência Artificial - IA, certo?
Entretanto, mesmo com sua popularização na indústria, criar um processo organizado para desenvolver, lançar em produção e manter modelos de IA de forma contínua se revela mais desafiador que o desenvolvimento tradicional de um software. Isso porque as mudanças que envolvem a recriação de modelos se baseiam em três grandes eixos: código-fonte, processo de treinamento e dados utilizados (Figura 1).
Soma-se a isso um quarto esforço bastante atrelado aos desafios estruturais das organizações, envolvendo integração com sistemas existentes para que as predições desses modelos possam gerar valor ao negócio.

Figura 1: os três eixos de mudança em uma aplicação de Machine Learning — dados, modelo e código — e algumas razões para que sofram mudanças. Fonte: https://martinfowler.com/articles/cd4ml.html
Tais desafios já são abordados no âmbito do software através da disciplina de Integração e Entrega Contínua (CI/CD), com foco na automação dos passos necessários para que uma aplicação percorra essas etapas, conhecidas como esteiras de lançamento.
A mudança cultural necessária para resolver esses desafios originou a cultura DevOps, que reforça a necessidade de criar uma relação próxima e colaborativa entre todos os envolvidos no fluxo de entrega.
Mas como superar os desafios e alcançar essa transformação?
O desafio dos modelos de IA
Estudos recentes realizados pela Gartner mostram, na prática, o tamanho do desafio: somente 54% dos modelos de IA desenvolvidos pelas organizações chegam à produção. Os desafios que justificam os resultados são vários e podem ser classificados em três grandes categorias:
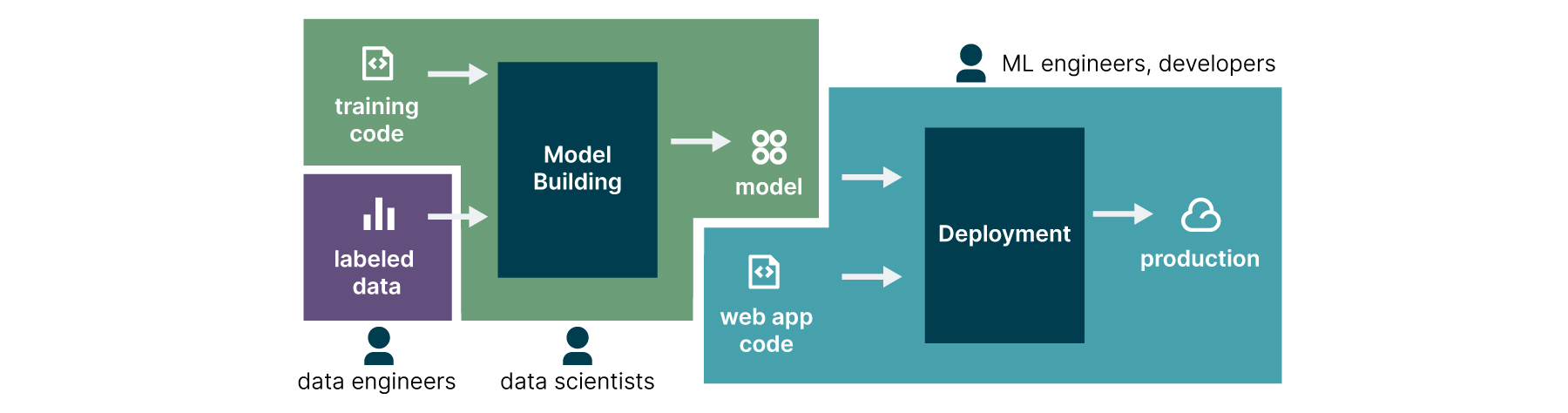
O primeiro desafio diz respeito ao modelo organizacional das empresas, que não considera o cientista de dados como parte do time de desenvolvimento, fazendo com que seu trabalho seja realizado de forma isolada, usualmente não integrada à infraestrutura de software das organizações (Figura 2).
O segundo desafio é técnico, já que as estruturas existentes para lançamento de software não levam em conta os processos necessários para treinamento de modelos e sua posterior integração às aplicações, fazendo que sejam forçadamente "empurrados" para a produção. Mesmo chegando à etapa de produção, é difícil monitorar seu comportamento e garantir que os resultados alcançados na etapa de treinamento se mantém com os dados reais.
O terceiro e último desafio diz respeito à governança e sua integração com a camada de negócios. Muitas organizações não conseguem comprovar o valor adequado de retorno sobre o investimento realizado e seu alinhamento com os objetivos de negócio. Também não há uma visão clara de papéis e responsabilidades, assim como o impacto dos resultados para todas as pessoas envolvidas, sejam estes positivos ou negativos.
A metodologia CD4ML
Estendendo a ideia de DevOps para a Aprendizagem de Máquina (Machine Learning) surge o termo MLOps, ou Operações em Aprendizagem de Máquina (em inglês, Machine Learning Operations), um processo que ajuda organizações a gerar valor no longo prazo reduzindo os riscos associados à ciência de dados, aprendizagem de máquina e iniciativas de inteligência artificial, formalizado por meio da metodologia CD4ML, que adapta os processos e práticas da integração e entrega contínua, para facilitar a adoção de uma cultura MLOps nas organizações.
O CD4ML - Continuous Delivery for Machine Learning (acrônimo para o termo em inglês Continuous Delivery for Machine Learning, em português entrega contínua para Aprendizado de Máquina) é uma abordagem da engenharia de software, onde times multifuncionais produzem aplicações de aprendizagem de máquina baseadas em código, dados, e modelos em pequenos e seguros incrementos, que podem ser reproduzidos e lançados em produção de forma confiável a qualquer momento, em ciclos de adaptação curtos. A definição inclui todos os princípios básicos:
Abordagem de engenharia de software: assim como na entrega de software, os modelos entregues em produção devem seguir um processo que garanta qualidade e segurança nos artefatos produzidos, de forma eficiente.
Times multifuncionais: especialistas com um conjunto diferente de habilidades e competências que permeiam os campos de engenharia de dados, ciência de dados, engenharia de machine learning, desenvolvimento, operações e outras áreas de conhecimento envolvidas trabalham juntos e de forma colaborativa reforçando as virtudes uns dos outros.
Software produzido com base no código, dados e binários dos modelos: todos os artefatos envolvidos no processo de lançamento de um modelo em produção necessitam de diferentes ferramentas e fluxos de trabalho que precisam ser versionados e gerenciados de forma adequada.
Incrementos pequenos e seguros: enquanto as saídas dos modelos podem não ser determinísticas nem fáceis de serem reproduzidas, o processo de lançar o modelo em produção deve ser confiável e reprodutível, utilizando-se do máximo de automação possível.
Lançamento extemporâneo: é importante que os artefatos de software envolvidos com o modelo ML possam ser entregues em produção a qualquer momento. Ainda que não seja do interesse da organização fazer lançamentos frequentes, a infraestrutura deve estar sempre pronta para fazê-lo. Lançar um modelo em produção torna-se então uma decisão de negócios e não técnica.
Curtos ciclos de adaptação: ciclos curtos significam que as alterações podem ser feitas em poucos dias ou, idealmente, poucas horas. Isso só é possível através da automação e a qualidade intrínseca adicionada ao processo de lançamento de modelos em produção. Assim é possível acelerar o ciclo de feedback e facilitar a adaptabilidade do modelo de forma a maximizar seus resultados com dados de produção.
Para que a metodologia seja implementada é necessário se valer de uma série de componentes técnicos que possibilitem a rastreabilidade e versionamento dos artefatos gerados desde a construção de um experimento de dados até seu empacotamento como um produto de software. A orquestração das tecnologias necessárias para implementar cada um dos componentes compõem o modelo completo para uma arquitetura CD4ML. É possível explorar cada um deles discutindo a jornada de um experimento de dados e seu caminho até a produção.
Do experimento ao produto
Para entender o caminho que um trabalho de dados percorre, da elaboração do experimento até a integração com a camada de produção, é necessário passar pelos papéis que estão presentes em um time de dados e como se definem suas responsabilidades na entrega do resultado:
Pessoa engenheira de dados: responsável por fornecer as ferramentas de acesso e consolidação dos produtos de dados da organização, em uma plataforma que habilita o Data Mesh na organização.
Pessoa cientista de dados: responsável por identificar as oportunidades de negócio, mostrando como o trabalho de dados pode melhorar os resultados da organização. Tem um papel fundamental do ponto de vista técnico, elaborando a versão inicial da solução do problema, oferecendo também uma perspectiva de negócios, identificando as métricas de sucesso para a organização que servirão no futuro para avaliar o resultado do modelo em produção.
Pessoa Engenheira de Machine Learning: responsável por fornecer os componentes técnicos capazes de habilitar os princípios CD4ML na organização, tais quais ferramentas de versionamento de experimentos, repositórios de dados, esteiras de automação e camadas de integração com o ambiente de produção da organização. Também é capaz de auxiliar a pessoa cientista de dados na solução de problemas de escalabilidade e performance do modelo proposto.
Ainda que cada pessoa do time possua responsabilidades bem definidas, é importante lembrar que trata-se de uma mudança cultural, onde todas devem entender que a responsabilidade de colocar o modelo em produção é coletiva, e não individual. Assim como atuar na solução de problemas que venham a acontecer, utilizando os princípios de blameless.
Uma vez definidos os papéis e responsabilidades das pessoas envolvidas, é possível detalhar os componentes técnicos que estão envolvidos em cada uma das etapas da jornada até a produção.
Dados acessíveis e catalogados
O livro Data Mesh: Delivering Data-Driven Value at Scale de Zhamak Dehghani discorre sobre os dados operacionais e analíticos e suas fontes no ambiente corporativo. Enquanto os dados operacionais estão organizados nas fontes transacionais (OLTP), os dados analíticos estão nas fontes consolidadas (OLAP). Ainda que ambas possam servir de fonte para um trabalho de dados, os modelos de ML normalmente se utilizam de dados analíticos. A Pessoa Engenheira de Dados deve então trabalhar na plataforma de dados em conjunto com a equipe de produto para fornecer camadas de consulta acessíveis, preferencialmente conectadas a um catálogo corporativo de forma a explicar seu valor de forma clara para todos os que precisam consumi-lo. Um exemplo de como essa etapa deve ser construída está apresentado na Figura 3.

CD4ML na prática
A implementação da metodologia CD4ML se baseia em alguns princípios básicos, similares àqueles que encontramos nas disciplinas de integração e entrega contínua, como abordado por Jez Humble e Davi Farley no livro Continuous delivery: reliable software releases through build, test, and deployment automation:
Automatizar quase tudo: depender de ações e aprovações manuais sempre pode levar a algum tipo de erro ou atraso. Também é muito difícil lembrar todas as escolhas que são necessárias para garantir a entrega do artefato com a mesma qualidade que foi inicialmente construído. A automação ajuda a ter um padrão reprodutível e garantir a mesma qualidade para todas as entregas.
Qualidade é intrínseca: quanto mais cedo os defeitos são capturados, mais fácil será corrigi-los. Todo o processo de construção de esteiras de lançamento descrito aqui está relacionado ao princípio de “encontrar logo as dores”, para não permitir que os possíveis problemas se propaguem até a produção ou que a complexidade dos processos só sejam descobertas próximas do lançamento. Isso também permite uma redução de custo significativa do impacto das correções, que devem ser feitas o mais cedo possível no processo de desenvolvimento.
Lançamento de pequenos e frequentes incrementos: se é importante para o desenvolvimento de software entregar uma versão inicial para iniciar o ciclo de feedback com a cliente, no processo de dados esta etapa é crucial. Em geral os trabalhos científicos relacionados a dados são realizados em ambientes isolados ou com escopo reduzido, e normalmente não é possível ter certeza de como o modelo vai se comportar com dados de produção. Assim, lançar e testar uma versão inicial diretamente com o mercado pode ser muito mais eficiente do que refinar o experimento no ambiente controlado.
Processo reprodutível e auditável: quando o trabalho de construção de um modelo é feito de forma artesanal e fora do processo de software, é muito difícil reproduzir o experimento e construir algo que funcione exatamente da maneira como foi concebido. Isso pode ser muito crítico para empresas que baseiam muitos processos decisórios na saída de modelos de inteligência artificial, principalmente levando em conta a rotatividade de profissionais que pode fazer com que o conhecimento envolvido se perca. Além disso, há ainda a questão da auditabilidade: dada às necessidades para o cumprimento da legislação ou compliance, pode ser necessário à empresa explicar como o modelo foi construído e/ou está tomando decisões.
A implementação da metodologia CD4ML nas empresas faz com que lançar modelos de ML se torne uma decisão de negócios vinculada à arquitetura de software empresarial, e não uma decisão técnica dependente do time de dados.
Processo de treinamento reprodutível
No processo CD4ML, a transição entre o trabalho feito pela pessoa cientista de dados e um modelo baseado em pipelines para a publicação deve observar os mesmos princípios da integração e entrega contínua: automação, testes e monitoramento para todas as etapas.
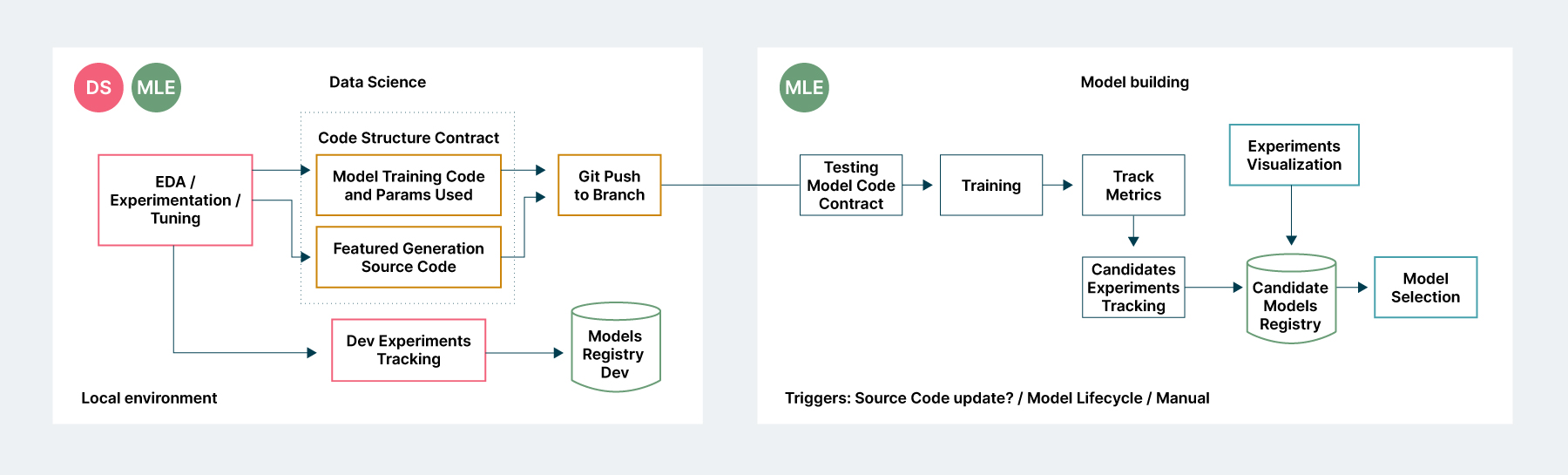
Assim, de uma típica camada de experimentação, que pode acontecer em um Jupyter Notebook no ambiente local ou remoto, é necessário registrar não somente o código utilizado para gerar o modelo, mas também o processo de geração das features. Tudo isso é registrado em um sistema de versionamento de experimentos capaz de registrar as mudanças realizadas em cada uma das etapas, além de armazenar as diferentes versões de modelos gerados.
Quando o código estiver pronto, será enviado a uma camada de testes e registro dos modelos gerados, suas métricas de performance e comparação com os outros experimentos realizados, como ilustrado na figura 4. É importante ressaltar que um modelo que tem como objetivo chegar a produção não deve ser construído no ambiente de experimentação, normalmente sob controle da pessoa cientista de dados, mas sim num ambiente corporativo, integrado à arquitetura de software da instituição, que pode ser acionado sem a intervenção da pessoa cientista de dados, se necessário.
Publicação do modelo como produto
Um modelo de ML não deve ser encarado como um artefato estranho à arquitetura de software corporativa da organização. Criar um modelo de dados na visão de produto é garantir princípios básicos de entrega de software, como reprodutibilidade e versionamento de todos os elementos envolvidos na sua criação (código + dados).
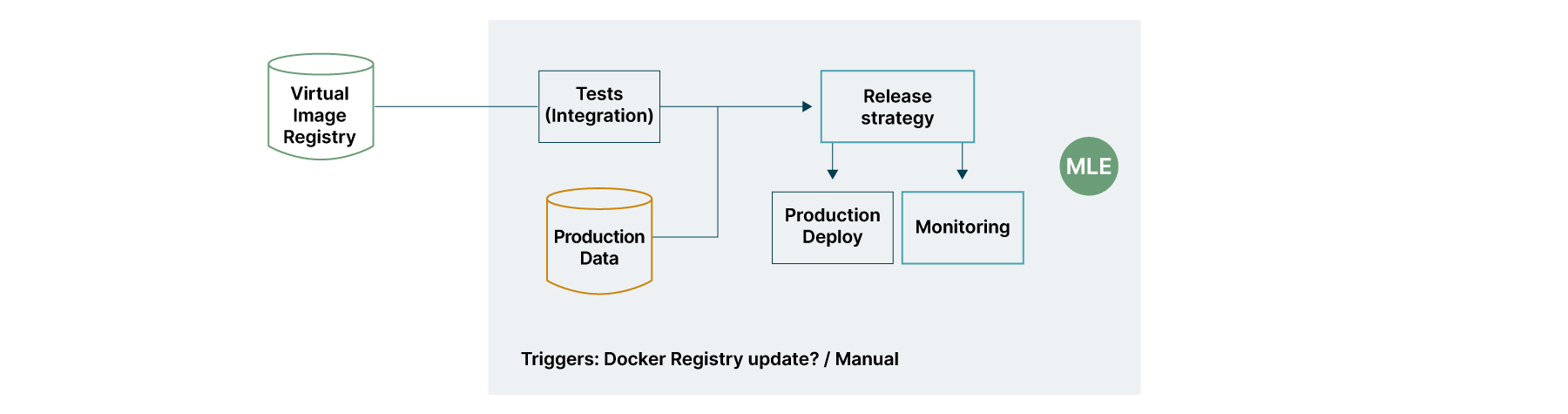
Para que seja possível acessar o modelo, utilizamos a mesma perspectiva da entrega de produtos de negócio sob a perspectiva do Domain-Driven Design - DDD: disponibilização de um serviço capaz de fornecer acesso às suas predições. A camada de testes garante que alterações no modelo entregue não afetem a continuidade do serviço de negócio, enquanto a criação de um container reduz os riscos, permitindo que o mesmo modelo trafegue em todos os ambientes até chegar à produção. A camada de versionamento permite a recuperação em caso de falha, além de facilitar o acompanhamento da evolução do produto de dados integrado à plataforma corporativa. A Figura 5 descreve as camadas de integração desse processo.

Testes e monitoramento em produção
Muitos modelos podem possuir boa performance quando são treinados, mas não conseguem garantir o mesmo desempenho ao longo do tempo. Possuir métricas de negócio atreladas à entrega do modelo auxilia na garantia de continuidade da entrega dos resultados do negócio, desprezando novos modelos que não melhorem os resultados.
Para atender à premissa de lançamento extemporâneo dos modelos, técnicas de Blue Green Deployment podem ser adicionadas na esteira de lançamento e acionadas automaticamente pela presença de novos modelos. Se for necessário garantir que a métrica de negócio está sendo superada pela nova versão, uma estratégia de Canary Release pode ser conectada à esteira de lançamento.
O monitoramento pode envolver, além de componentes simples como dados sobre disponibilidade do serviço, detecção de desvios de conceito dos modelos em produção, como abordado no artigo Methods to Investigate Concept Drift in Big Data Streams de Nidhi, Mangat, V., Gupta, V., e Vig, R.
Processo completo
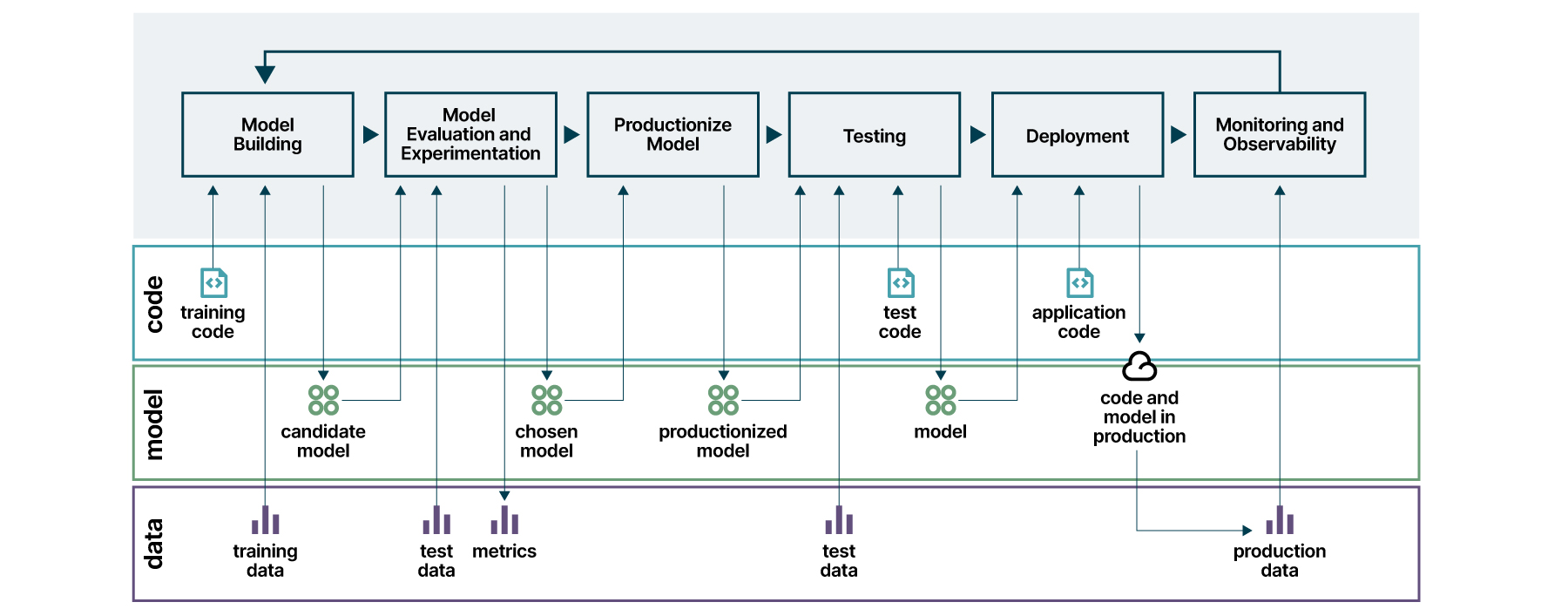
Ao atacar cada um dos desafios técnicos de forma incremental, por meio do conjunto de ferramentas e tecnologias que for mais adequado para a arquitetura da organização, é possível obter o processo completo descrito na Figura 7. Os artefatos gerados em cada etapa são descritos nos três eixos: código, modelo e dados.
Para implementar a esteira completa, é necessária a utilização de alguma ferramenta de integração e entrega contínua para orquestrar todas as etapas.
Trabalhos de dados são hipóteses, e por isso devem ser tratados como experimentos. O resultado final de uma esteira CD4ML é habilitar nas organizações uma plataforma de experimentação, aumentando a velocidade da entrega e, mais importante, garantindo a entrega dos resultados de negócio em escala.
Aviso: As afirmações e opiniões expressas neste artigo são de responsabilidade de quem o assina, e não necessariamente refletem as posições da Thoughtworks.