













Los datos revelados en una investigación realizada por la consultora estadounidense McKinsey en 2017 mostraban que, en ese momento, las 500 principales empresas en el ranking de Fortune tomaban alrededor de 400 millones de decisiones al día. Muchas son estratégicas y requieren cierta participación directa, pero otras son más rápidas y están relacionadas con la dinámica del negocio, consumiendo un tiempo innecesario de los gerentes: un desperdicio promedio de 530,000 días al año en la toma de decisiones. Desde el punto de vista táctico, la solución para evitar este desperdicio es la automatización de gran parte de las decisiones mediante el uso de Inteligencia Artificial (IA), ¿verdad?
Sin embargo, incluso con su popularización en la industria, crear un proceso organizado para desarrollar, implementar en producción y mantener modelos de IA de manera continua resulta más desafiante que el desarrollo tradicional de software. Esto se debe a que los cambios que implican la recreación de modelos se basan en tres grandes ejes: código fuente, proceso de entrenamiento y datos utilizados (Figura 1).
A esto se suma un cuarto esfuerzo bastante vinculado a los desafíos estructurales de las organizaciones, que implica la integración con sistemas existentes para que las predicciones de estos modelos puedan generar valor para el negocio.

Estos desafíos ya se abordan en el ámbito del software a través de la disciplina de Integración y Entrega Continua (CI/CD), con un enfoque en la automatización de los pasos necesarios para que una aplicación pase por estas etapas, conocidas como líneas de lanzamiento.
La transformación cultural necesaria para resolver estos desafíos dio origen a la cultura DevOps, que refuerza la necesidad de crear una relación cercana y colaborativa entre todos los involucrados en el flujo de entrega.
Pero, ¿cómo superar los desafíos y lograr esta transformación?
El desafío de los modelos de IA
Estudios recientes realizados por Gartner muestran, en la práctica, la magnitud del desafío: solo el 54% de los modelos de IA desarrollados por las organizaciones llegan a la producción. Los desafíos que justifican estos resultados son diversos y se pueden clasificar en tres grandes categorías:
- El primer desafío se refiere al modelo organizacional de las empresas, que no considera al científico de datos como parte del equipo de desarrollo, lo que hace que su trabajo se realice de manera aislada, generalmente sin integrarse a la infraestructura de software de las organizaciones (Figura 2).
- El segundo desafío es técnico, ya que las estructuras existentes para el lanzamiento de software no tienen en cuenta los procesos necesarios para el entrenamiento de modelos y su posterior integración en las aplicaciones, lo que hace que se vean forzados a ser "empujados" a la producción. Incluso llegando a la etapa de producción, es difícil monitorear su comportamiento y garantizar que los resultados obtenidos en la etapa de entrenamiento se mantengan con los datos reales.
- El tercer y último desafío se refiere a la gobernanza y su integración con la capa de negocios. Muchas organizaciones no pueden demostrar el valor adecuado del retorno de la inversión realizada y su alineación con los objetivos comerciales. También no hay una visión clara de roles y responsabilidades, así como del impacto de los resultados para todas las personas involucradas, ya sean positivos o negativos.
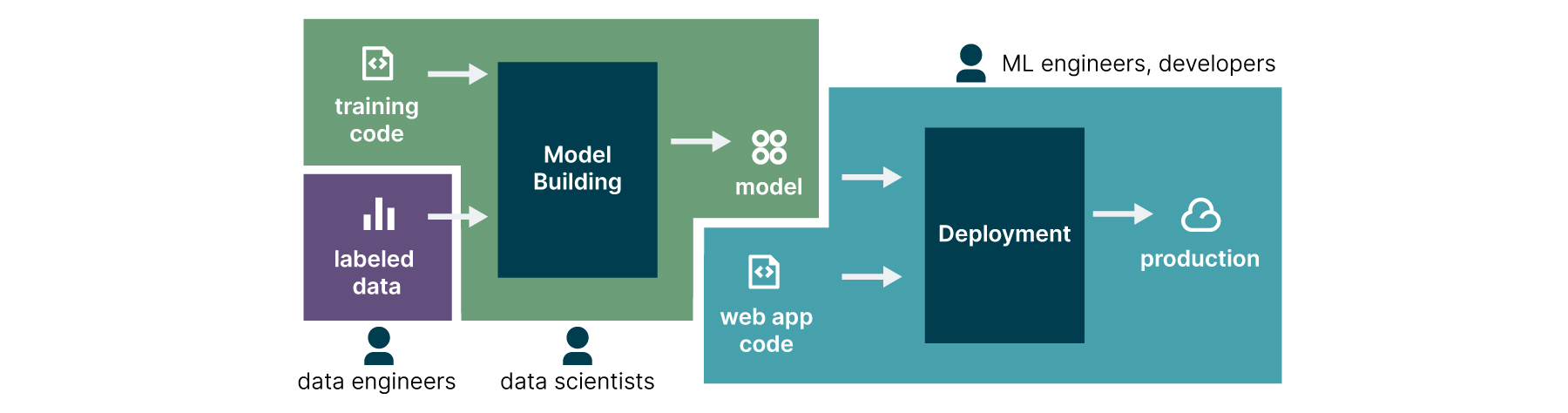
Figura 2: problema del aislamiento de responsabilidades en grandes organizaciones puede crear barreras, sofocando la capacidad de automatizar el proceso completo de lanzamiento de los modelos en producción. Fuente: https://martinfowler.com/articles/cd4ml.html
La metodología CD4ML
Extendiendo la idea de DevOps al Aprendizaje Automático (Machine Learning) surge el término MLOps, u Operaciones en Aprendizaje Automático (Machine Learning Operations), un proceso que ayuda a las organizaciones a generar valor a largo plazo reduciendo los riesgos asociados con la ciencia de datos, el aprendizaje automático y las iniciativas de inteligencia artificial, formalizado a través de la metodología CD4ML, que adapta los procesos y prácticas de la integración y entrega continua para facilitar la adopción de una cultura MLOps en las organizaciones.
CD4ML - Continuous Delivery for Machine Learning (acrónimo para el término en inglés Continuous Delivery for Machine Learning, en portugués entrega continua para Aprendizaje de Máquina) es un enfoque de ingeniería de software donde equipos multifuncionales producen aplicaciones de aprendizaje de máquina basadas en código, datos y modelos en incrementos pequeños y seguros, que se pueden reproducir y lanzar en producción de manera confiable en cualquier momento, en ciclos de adaptación cortos. La definición incluye todos los principios básicos:
- Abordaje de ingeniería de software: al igual que en la entrega de software, los modelos entregados en producción deben seguir un proceso que garantice calidad y seguridad en los artefactos producidos de manera eficiente.
- Equipos multifuncionales: expertos con un conjunto diferente de habilidades y competencias que abarcan los campos de la ingeniería de datos, la ciencia de datos, la ingeniería de machine learning, el desarrollo, las operaciones y otras áreas de conocimiento involucradas trabajan juntos y de manera colaborativa, reforzando las virtudes unos de otros.
- Software producido basado en código, datos y modelos binarios: todos los artefactos involucrados en el proceso de lanzamiento de un modelo en producción necesitan diferentes herramientas y flujos de trabajo que deben ser versionados y gestionados adecuadamente.
- Incrementos pequeños y seguros: aunque las salidas de los modelos pueden no ser determinísticas ni fáciles de reproducir, el proceso de lanzar el modelo en producción debe ser confiable y reproducible, utilizando la mayor automatización posible.
- Lanzamiento extemporáneo: es importante que los artefactos de software involucrados con el modelo de ML puedan entregarse en producción en cualquier momento. Aunque no sea del interés de la organización realizar lanzamientos frecuentes, la infraestructura debe estar siempre lista para hacerlo. Lanzar un modelo en producción se convierte entonces en una decisión comercial y no técnica.
- Ciclos cortos de adaptación: ciclos cortos significan que los cambios pueden hacerse en pocos días o, idealmente, en pocas horas. Esto solo es posible mediante la automatización y la calidad intrínseca agregada al proceso de lanzamiento de modelos en producción. Así es posible acelerar el ciclo de retroalimentación y facilitar la adaptabilidad del modelo para maximizar sus resultados con datos de producción.
Para implementar la metodología, es necesario aprovechar una serie de componentes técnicos que posibiliten la trazabilidad y el versionamiento de los artefactos generados desde la construcción de un experimento de datos hasta su empaquetado como un producto de software. La orquestación de las tecnologías necesarias para implementar cada uno de los componentes conforma el modelo completo para una arquitectura CD4ML. Se puede explorar cada uno de ellos discutiendo la jornada de un experimento de datos y su camino hasta la producción.
Del experimento al producto
Para entender el camino que sigue un trabajo de datos, desde la elaboración del experimento hasta la integración con la capa de producción, es necesario pasar por los roles presentes en un equipo de datos y cómo se definen sus responsabilidades en la entrega del resultado:
- Persona ingeniera de datos: responsable de proporcionar las herramientas de acceso y consolidación de los productos de datos de la organización en una plataforma que habilite el Data Mesh en la organización.
- Persona científica de datos: responsable de identificar las oportunidades de negocio, mostrando cómo el trabajo de datos puede mejorar los resultados de la organización. Juega un papel fundamental desde el punto de vista técnico, elaborando la versión inicial de la solución del problema y ofreciendo también una perspectiva de negocios, identificando las métricas de éxito para la organización que servirán en el futuro para evaluar el resultado del modelo en producción.
- Persona ingeniera de Machine Learning: responsable de proporcionar los componentes técnicos capaces de habilitar los principios CD4ML en la organización, como herramientas de versionamiento de experimentos, repositorios de datos, pipelines de automatización y capas de integración con el entorno de producción de la organización. También puede ayudar a la persona científica de datos en la solución de problemas de escalabilidad y rendimiento del modelo propuesto.
Aunque cada persona del equipo tenga responsabilidades bien definidas, es importante recordar que se trata de un cambio cultural, donde todos deben entender que la responsabilidad de poner el modelo en producción es colectiva y no individual. También implica abordar problemas que puedan surgir utilizando los principios de blameless.
Una vez definidos los roles y responsabilidades de las personas involucradas, es posible detallar los componentes técnicos que participan en cada una de las etapas del viaje hacia la producción.
Datos accesibles y catalogados
El libro "Data Mesh: Delivering Data-Driven Value at Scale" de Zhamak Dehghani habla sobre los datos operativos y analíticos y sus fuentes en el entorno corporativo. Mientras que los datos operativos están organizados en fuentes transaccionales (OLTP), los datos analíticos están en fuentes consolidadas (OLAP). Aunque ambos pueden servir como fuente para un trabajo de datos, los modelos de ML normalmente utilizan datos analíticos. La persona ingeniera de datos debe trabajar en la plataforma de datos en conjunto con el equipo de producto para proporcionar capas de consulta accesibles, preferiblemente conectadas a un catálogo corporativo para explicar su valor de manera clara a todos los que necesitan consumirlo. Un ejemplo de cómo debería construirse esta etapa se presenta en la Figura 3.

Figura 3: catálogo de datos y etapas de extracción
CD4ML en la práctica
La implementación de la metodología CD4ML se basa en algunos principios básicos, similares a los que encontramos en las disciplinas de integración y entrega continua, como se aborda en el libro "Continuous delivery: reliable software releases through build, test, and deployment automation" de Jez Humble y Davi Farley:
- Automatizar casi todo: Depender de acciones y aprobaciones manuales siempre puede llevar a algún tipo de error o retraso. También es muy difícil recordar todas las decisiones necesarias para garantizar la entrega del artefacto con la misma calidad con la que fue construido inicialmente. La automatización ayuda a tener un patrón reproducible y garantizar la misma calidad para todas las entregas.
- Calidad es Intrínseca: Cuanto antes se capturen los defectos, más fácil será corregirlos. Todo el proceso de construir canalizaciones de lanzamiento descrito aquí está relacionado con el principio de "encontrar pronto los problemas", para evitar que los posibles problemas se propaguen hasta la producción o que la complejidad de los procesos solo se descubra cerca del lanzamiento. Esto también permite una reducción significativa en el impacto de costos de las correcciones, que deben hacerse lo antes posible en el proceso de desarrollo.
- Lanzamiento de incrementos pequeños y frecuentes: Si es importante para el desarrollo de software entregar una versión inicial para iniciar el ciclo de retroalimentación con el cliente, en el proceso de datos esta etapa es crucial. En general, los trabajos científicos relacionados con datos se realizan en entornos aislados o con un alcance reducido, y normalmente no es posible estar seguro de cómo se comportará el modelo con datos de producción. Así, lanzar y probar una versión inicial directamente con el mercado puede ser mucho más eficiente que perfeccionar el experimento en un entorno controlado.
- Proceso reproducible y auditado: Cuando la construcción de un modelo se realiza de forma artesanal y fuera del proceso de software, es muy difícil reproducir el experimento y construir algo que funcione exactamente como se concibió. Esto puede ser crítico para las empresas que basan muchos procesos de toma de decisiones en la salida de modelos de inteligencia artificial, especialmente teniendo en cuenta la rotación de profesionales que puede hacer que se pierda el conocimiento involucrado. Además, está la cuestión de la auditabilidad: dadas las necesidades para el cumplimiento de la legislación o el cumplimiento, puede ser necesario que la empresa explique cómo se construyó el modelo y/o está tomando decisiones.
La implementación de la metodología CD4ML en las empresas hace que el lanzamiento de modelos de ML sea una decisión de negocios vinculada a la arquitectura de software empresarial, y no una decisión técnica dependiente del equipo de datos.
Proceso de entrenamiento reproducible
En el proceso CD4ML, la transición entre el trabajo realizado por el científico de datos y un modelo basado en tuberías para su publicación debe seguir los mismos principios de integración y entrega continua: automatización, pruebas y monitoreo para todas las etapas.
Así, desde una capa típica de experimentación, que puede ocurrir en un cuaderno Jupyter local o remoto, es necesario registrar no solo el código utilizado para generar el modelo, sino también el proceso de generación de características. Todo esto se registra en un sistema de versionamiento de experimentos capaz de registrar los cambios realizados en cada una de las etapas, además de almacenar las diferentes versiones de modelos generados.
Cuando el código esté listo, se enviará a una capa de pruebas y registro de los modelos generados, sus métricas de rendimiento y comparación con otros experimentos realizados, como se ilustra en la figura 4. Es importante destacar que un modelo destinado a la producción no debe construirse en el entorno de experimentación, normalmente bajo el control del científico de datos, sino en un entorno corporativo, integrado en la arquitectura de software de la institución, que puede activarse sin la intervención del científico de datos si es necesario.
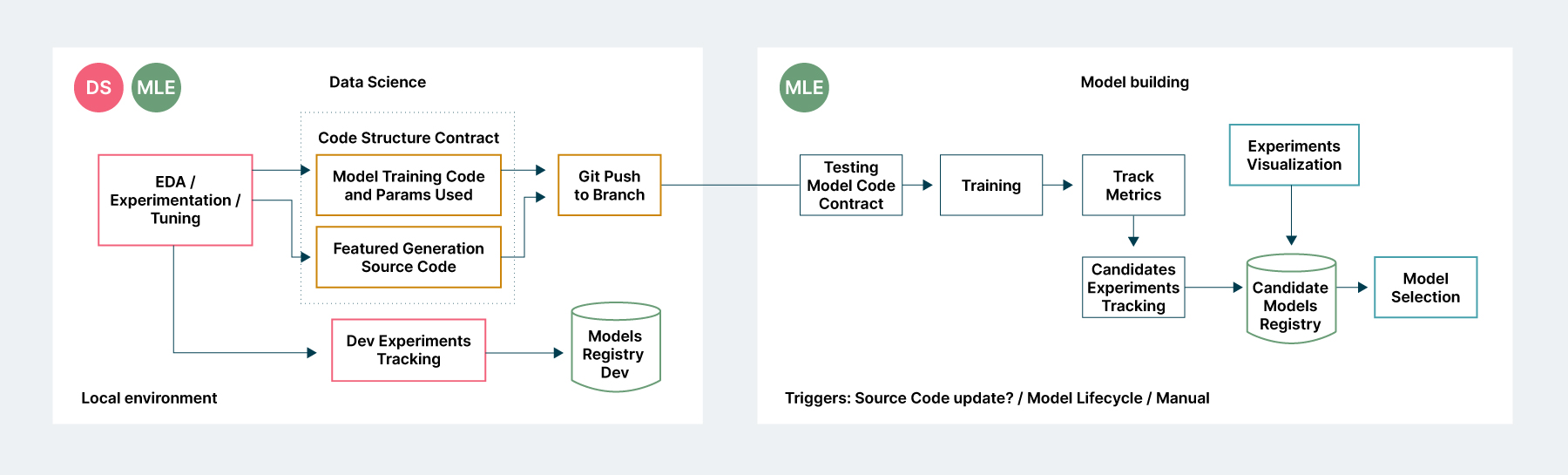
Figura 4: Capas de generación de experimentos y creación de modelos a través del entorno corporativo
Publicación del modelo como producto:
Un modelo de ML no debe ser visto como un artefacto ajeno a la arquitectura de software corporativo de la organización. Crear un modelo de datos desde una perspectiva de producto garantiza principios básicos de entrega de software, como la reproducibilidad y el versionamiento de todos los elementos involucrados en su creación (código + datos).
Para que sea posible acceder al modelo, utilizamos la misma perspectiva que la entrega de productos comerciales desde la perspectiva del Diseño Dirigido por Dominio (DDD): proporcionar un servicio capaz de brindar acceso a sus predicciones. La capa de pruebas asegura que los cambios en el modelo entregado no afecten la continuidad del servicio comercial, mientras que la creación de un contenedor reduce los riesgos, permitiendo que el mismo modelo viaje por todos los entornos hasta llegar a la producción. La capa de versionamiento permite la recuperación en caso de fallo y facilita el seguimiento de la evolución del producto de datos integrado en la plataforma corporativa. La Figura 5 describe las capas de integración de este proceso.

Figura 5: Proceso para integrar el modelo en la arquitectura corporativa como producto
Pruebas y monitoreo en producción:
Muchos modelos pueden tener un buen rendimiento cuando se entrenan, pero no logran garantizar el mismo rendimiento con el tiempo. Tener métricas comerciales vinculadas a la entrega del modelo ayuda a garantizar la continuidad de los resultados comerciales, desestimando nuevos modelos que no mejoren los resultados.
Para cumplir con la premisa de lanzamientos extemporáneos de modelos, se pueden agregar técnicas de implementación Blue-Green a la canalización de lanzamiento y activarse automáticamente por la presencia de nuevos modelos. Si es necesario garantizar que la métrica comercial esté siendo superada por la nueva versión, se puede conectar una estrategia de lanzamiento Canary a la canalización de lanzamiento.
El monitoreo puede involucrar, además de componentes simples como datos sobre la disponibilidad del servicio, la detección de desviaciones de concepto de los modelos en producción, como se aborda en el artículo Métodos para Investigar el Cambio de Concepto en Flujos de Datos Masivos de Nidhi, Mangat, V., Gupta, V., y Vig, R.
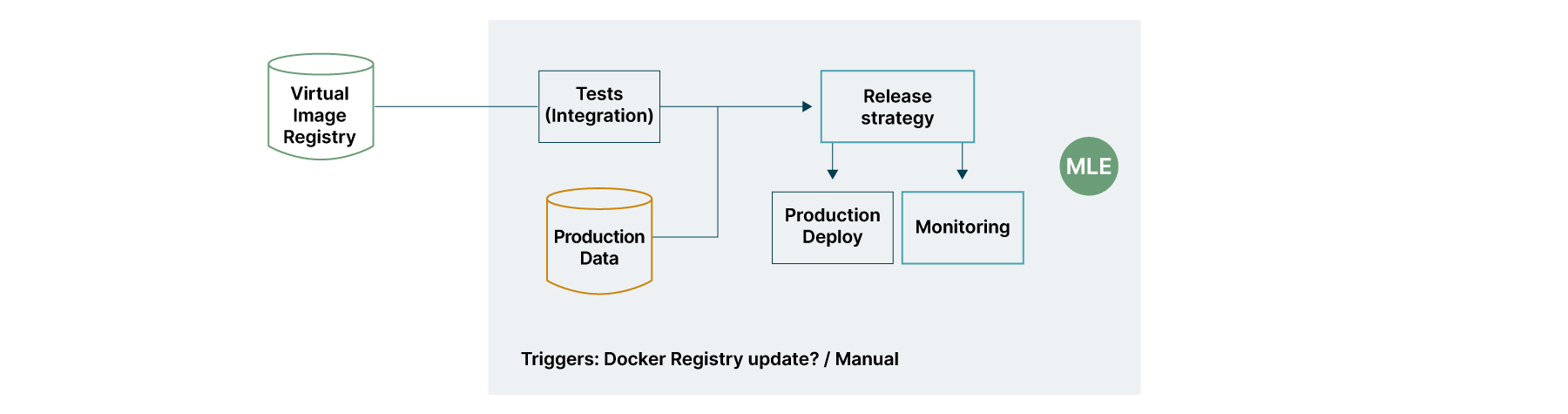
Figura 6: Capas de pruebas de integración y monitoreo en producción
Proceso completo
Al abordar cada uno de los desafíos técnicos de forma incremental a través del conjunto de herramientas y tecnologías que sean más adecuadas para la arquitectura de la organización, es posible obtener el proceso completo descrito en la Figura 7. Los artefactos generados en cada etapa se describen en los tres ejes: código, modelo y datos.
Para implementar la canalización completa, es necesario utilizar alguna herramienta de integración y entrega continua para orquestar todas las etapas.
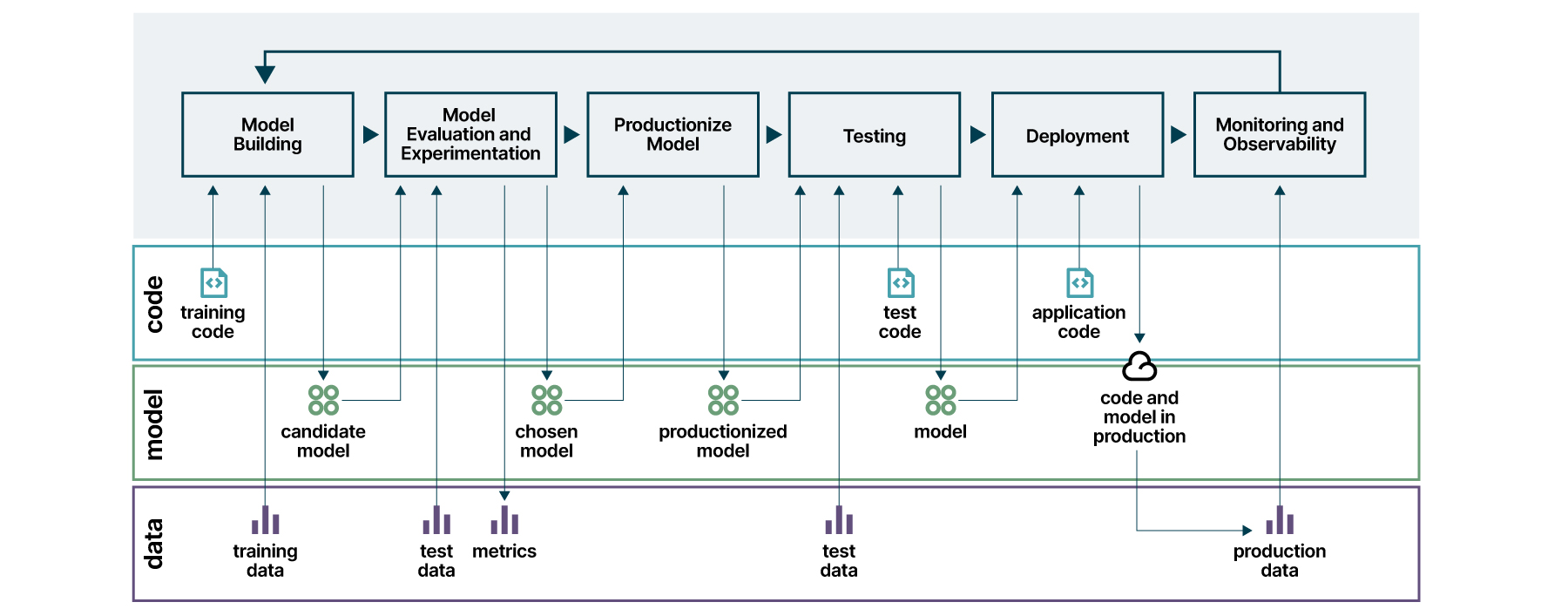
Figura 7: proceso completo de entrega continua para aprendizaje automático (CD4ML)
Los trabajos de datos son hipótesis y, por lo tanto, deben tratarse como experimentos. El resultado final de una canalización CD4ML es habilitar en las organizaciones una plataforma de experimentación, aumentando la velocidad de entrega y, lo que es más importante, garantizando la entrega de resultados comerciales a escala.
Aviso legal: Las declaraciones y opiniones expresadas en este artículo son las del autor/a o autores y no reflejan necesariamente las posiciones de Thoughtworks.