














AI and ML
How to use prompt engineering with large language models

Creating test cases is a critical but time-consuming and skill-intensive activity. However, the emergence of large language models (LLMs) has opened up an opportunity to automate this highly manual process done by QA engineers. Yet while there are reasons to be optimistic about LLMs’ ability to help us generate test cases, their true effectiveness has been largely unexplored in controlled experimental settings.
The primary challenge we want to address is determining whether AI tools can effectively assist QA professionals in creating comprehensive, accurate test cases while maintaining quality standards and reducing development time.
More specifically, there are a few questions we want to try and answer:
Can AI-generated test cases achieve comparable accuracy to manually created test cases?
What impact does AI assistance have on test case creation time and coverage?
How does prompt optimization affect the quality of AI-generated test cases?
What are the limitations of current AI tools in complex testing scenarios?
We hypothesized that using AI to generate test cases would result in:
Reduced test case creation time.
Improved test coverage, particularly for edge cases and complex scenarios.
Better consistency in test case structure compared to manual creation.
Three experienced QA engineers participated in this study, each with three to five years of professional testing experience. All participants had prior experience with manual test case creation and familiarity with standard testing methodologies. The tools we used were GitHub Copilot (which was the primary AI tool) and ChatGPT (as a secondary comparison).
This was our user story format:
Title: Concise summary
Description: Detailed user requirements
Acceptance criteria (AC): Clear completion rules
Edge cases and constraints: Special scenarios
We also used a standardized test case template:
Test case title/scenario
Preconditions
Test Steps
Expected results
Environment specification
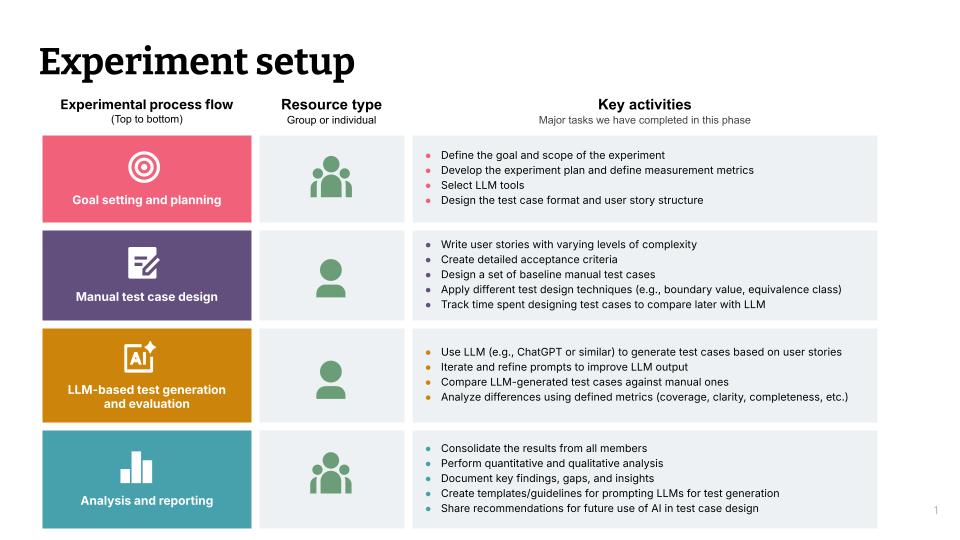
The experiment followed a controlled comparison methodology:
Baseline creation: QA engineers manually created test cases for nine user stories of varying complexity (simple, medium, hard).
AI generation: The same user stories were processed using AI tools with systematically refined prompts.
Comparative analysis: Results were evaluated using eight defined metrics.
Prompt optimization: An iterative process of prompt refinement based on initial results.
Final evaluation: Comprehensive scoring across all metrics using optimized prompts.
Eight key metrics were established to evaluate AI performance:
| Metric | Description | Measurement method |
| Correctness (%) | Percentage of test cases correctly matching requirements | QA review and scoring: (Correct test cases / Total manual test cases) × 100 |
| Acceptance criteria coverage (%) | Coverage of acceptance criteria by LLM test cases | Requirement traceability matrix: (Covered AC / Total AC) × 100 |
| Duplication rate (%) |
Percentage of redundant test cases | Manual review: (Duplicate test cases / Total LLM test cases) × 100 |
| Incorrect test cases (%) | Percentage of incomplete or irrelevant test cases | Review flagging: (Incorrect test Cases / Total LLM test cases) × 100 |
| Ambiguity score (%) | Percentage of test cases with unclear steps | QA ambiguity review: (Ambiguous test cases / Total LLM test cases) × 100 |
| Consistency score (%) | Adherence to structured format templates | Structure analysis: (Well-Forfmatted test cases / Total LLM test cases) × 100 |
| Prompt optimization Impact (%) | Improvement after prompt refinement | Comparative scoring: [(Improved score - Initial score) / Initial score] × 100 |
| Time efficiency (%) | Time reduction versus manual creation | Time tracking: [(Manual ttime - LLM time) / Manual time] × 100 |
The iterative prompt refinement process demonstrated a significant impact on the quality of outputs. Initial basic prompts produced rapid but incomplete results, while systematically enhanced prompts that incorporated specific instructions, format requirements, and testing methodologies yielded substantially improved outcomes.
Example prompt evolution:
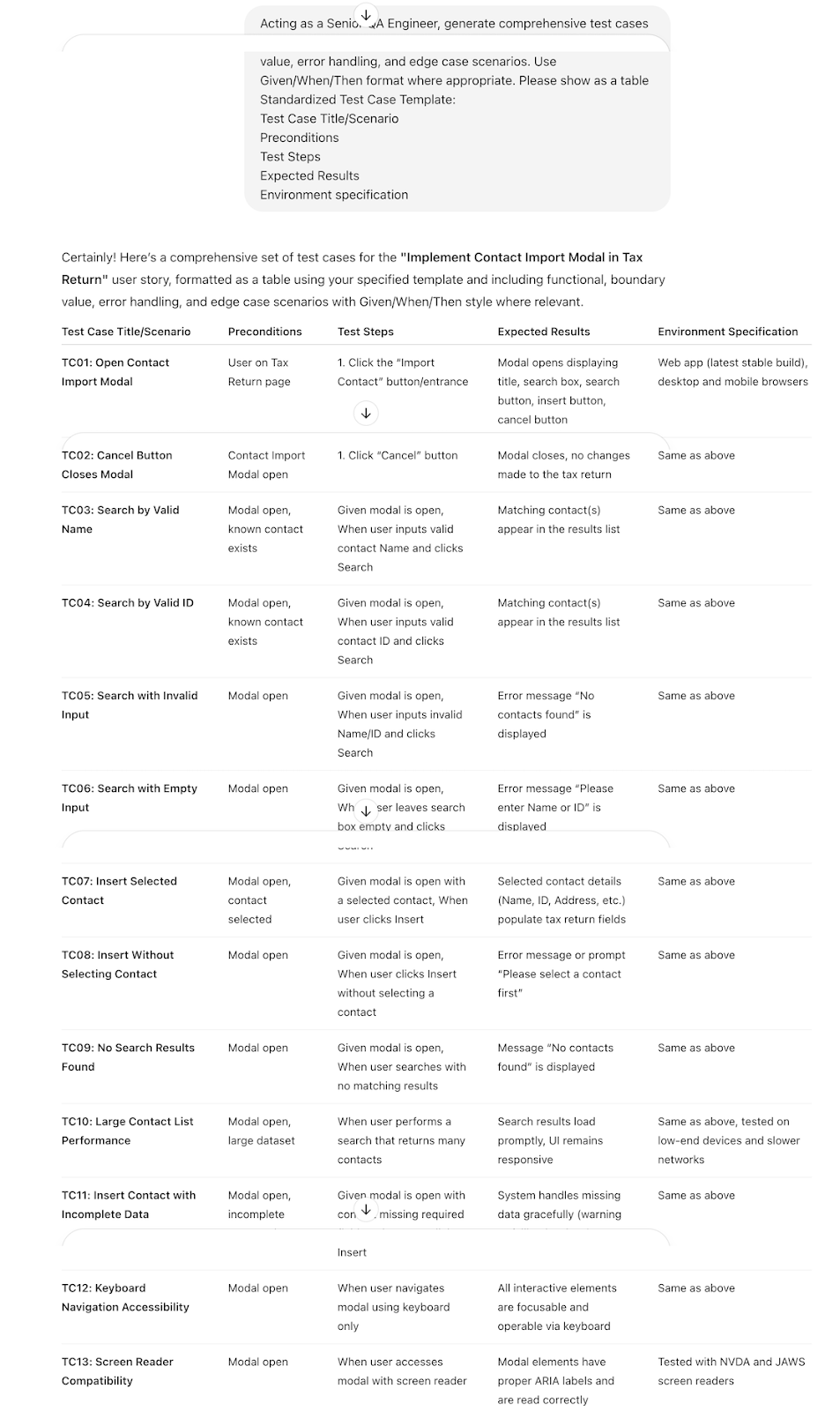
Initial prompt: "Generate test cases for this user story."

Optimized prompt: "Acting as a Senior QA Engineer, generate comprehensive test cases following the specified template format. Include functional, boundary value, error handling and edge case scenarios. Use Given/When/Then format where appropriate."
Here are the final average scores across nine user stories using optimized prompts:
| Metric | Average score (%) | Range |
| Correctness | 87.06 | 62.5- 130* |
| Acceptance criteria coverage | 98.67 | 93 - 100 |
| Duplication rate |
4.22 | 0 - 20 |
| Incorrect test cases | 6.44 | 0 - 20 |
| Ambiguity score | 27.22 | 9 - 80 |
| Consistency score | 96.11 | 90 - 100 |
| Prompt optimization impact | 67.78 | 0 - 80 |
| Time efficiency | 80.07 | 50 - 99 |
*Note: Scores above 100% indicate cases where AI generated more comprehensive test cases than the manual baseline.
In terms of the strengths of the AI, we found:
Rapid initial draft generation (seconds to minutes vs. hours).
High structural consistency across test cases.
Effective coverage of explicitly stated functional requirements.
Minimal redundancy in simple scenarios.
However, there were also considereable limitations.
There was a heavy dependence on input quality and specificity.
The AI had some difficulty interpreting complex business logic.
Advanced testing techniques weren't adequately applied.
There was limited non-functional testing coverage without explicit instruction.
Our hypothesis was partially validated. AI tools demonstrated clear advantages in efficiency and structural consistency, which supported the benefits we predicted. However, improved test coverage for complex scenarios required significant prompt engineering effort, and edge case identification remained challenging without explicit guidance.
The results suggest AI tools are most effective when positioned as assistive technologies rather than replacement solutions. The high time efficiency scores (80.07% average) indicate substantial productivity potential, while the moderate ambiguity scores (27.22% average) highlight continued need for human oversight.
ChatGPT demonstrated superior performance compared to GitHub Copilot in scenarios that required detailed prompt interpretation. This suggests tool selection may significantly impact the quality of results.
This study's limitations include:
Limited sample size (nine user stories).
A focus on specific AI tools and versions.
Subjective elements in qualitative assessment.
Lack of long-term productivity impact measurement.
Future research should explore:
Larger-scale validation across diverse project types.
Integration with existing QA toolchains.
The long-term effects on learning.
Cost-benefit analysis in production environments.
This experimental study suggests that AI tools have strong potential to improve the efficiency and structure of test case creation in QA workflows — particularly in generating initial drafts. With an average time saving of 80.07% and high consistency scores (96.11%), AI tools proved useful in accelerating routine tasks and ensuring format uniformity.
However, these benefits are not automatic. Achieving high-quality outputs depended heavily on prompt design: our prompt optimization process yielded a 67.78% average improvement across key metrics, highlighting the importance of clearly specifying format, scope and edge case expectations in the input prompts.
Rather than relying on general instructions, effective prompt engineering in practice involves iteratively refining prompts to include domain context, test objectives, and output structure.
Additionally, human oversight remains essential. Despite strong performance in basic scenarios, the AI-generated test cases exhibited ambiguity in 27.22% of instances. To mitigate these limitations, QA teams should implement structured review steps — such as manual validation against acceptance criteria, flagging unclear logic and verifying edge case coverage — before adopting AI-generated tests into production workflows.
In summary, LLMs are most effective when used as intelligent assistants that accelerate test case creation under human direction. Rather than replacing testers, they augment productivity - provided that teams invest in practical prompt design skills and maintain rigorous validation practices.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

