














AI and ML
Effective machine learning (Part I)

Realestate.com.au (REA) is Australia's number one address for property with over 12.6 million Australians visiting the site each month. Along with more properties for sale than anywhere else, REA also provides detailed market information, including automated valuations, for a significant proportion of residential properties in Australia. To achieve this, we worked with REA and used machine learning — such as automated valuation models (AVMs) — to deliver customer value.
AVMs harness the power of data and machine learning to provide estimated valuations for any given residential property. This helps buyers and sellers understand the estimated price range for a given property and enables lenders and valuers to make better business and strategic decisions.
As we know, machine learning projects inherently involve many components and moving parts:
Data
Data pipelines that compose data from myriad sources, with assumptions (implicit or explicit) on data quality and coverage along the way
Data pipelines that provide data to machine learning models at high-throughput during training, and at low-latency during inference, while ensuring batch-live symmetry.
Code
Ways of working
When these moving parts are not managed intentionally, we see Gestalt-esque complexity. Points of friction can accumulate to make development, testing and delivery more tedious, and ultimately costlier, than it needs to be.
While developing and evolving our AVMs, we put on the continuous improvement (Kaizen) mindset to reflect on how we can reduce friction and improve flow. We looked at the successes of the DevOps, Accelerate and machine learning operations (MLOps) movements, and set out to cultivate an MLOps culture to help us deliver machine learning solutions effectively.
There are many principles and practices that make up an MLOps culture (see Figure 1). In this short-format article, we will share three practices that have helped us to trade friction for flow.
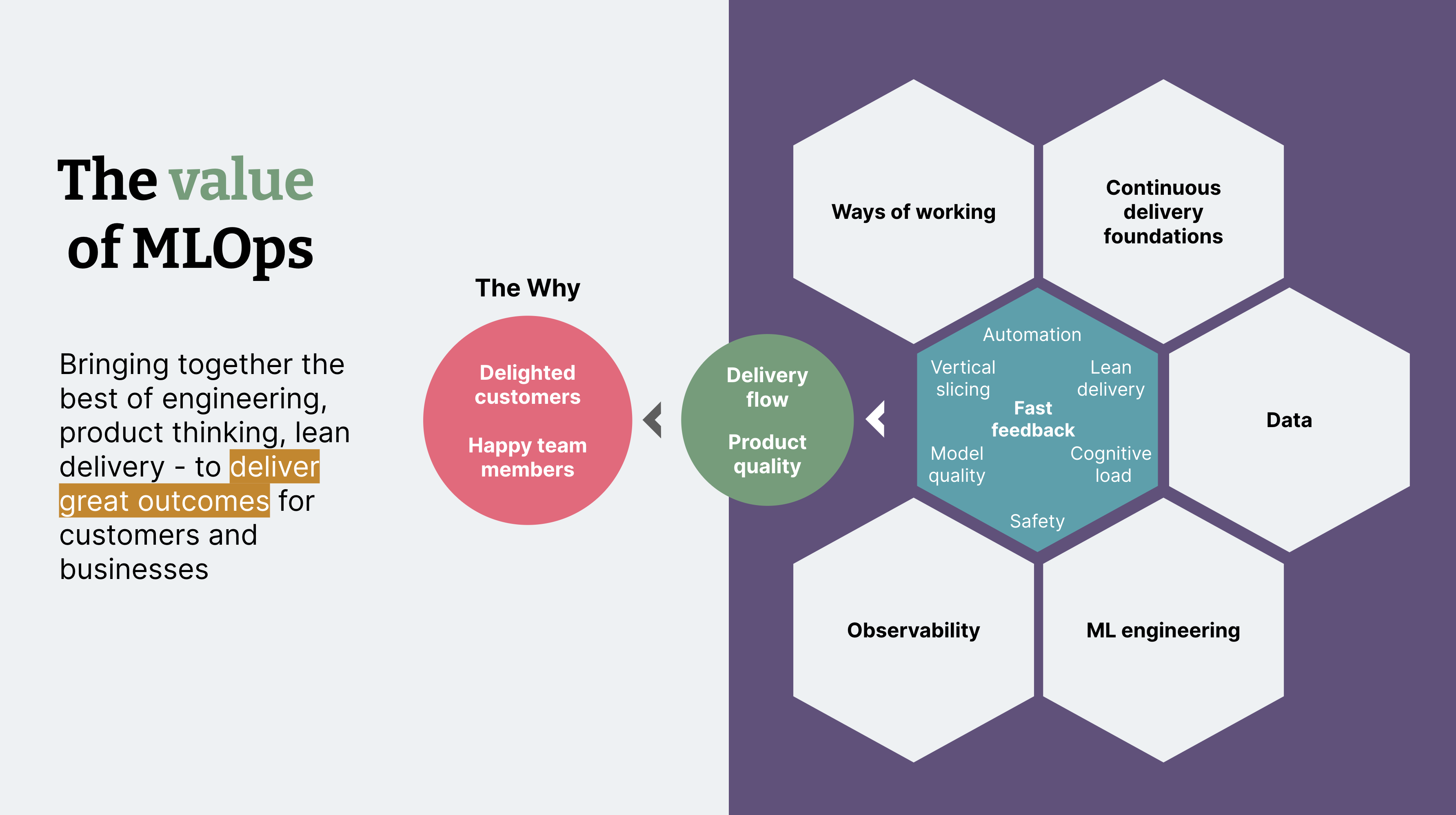
Figure 1: MLOps culture brings together the best of engineering, product thinking, lean delivery to deliver great outcomes for customers and businesses
It’s an empirical fact that handoffs and backlog coupling increase waste and reduce flow. For example, in an informal study of hundreds of tasks passing through a delivery centre, tasks that had to wait for another team took 10–12 times longer than tasks that could be completed by a single empowered team without dependency.
To address this, we restructured our teams to be cross-functional, comprising multiple roles, such as: data science, data engineering, ML engineering, API, QA and product. The result was a team that is empowered with the required capabilities and context to develop, test and deploy machine learning model enhancements to production, without the need to wait on (and be blocked by) another team.
Research has found that optimal information flow is a key ingredient in high-performing software organizations, and vertically slicing our teams allowed us to optimize information flow. We traded waiting for days and weeks (waiting on another team) for fast feedback (through pair programming and tech huddles).
A common source of friction in any machine learning (and even software) project is manual regression testing. Without test automation, waste can manifest at multiple points: during development; during testing before declaring that a card is done; and during production incidents, when we might spend hours and days triaging and fixing a defect that slipped through the cracks of manual testing.
Instead, we developed a series of automated quality gates on our CI pipeline. These tests include unit tests, model training tests, API tests and model quality tests (left to right on CI, from fast-running tests to slow-running tests).
This gave us fast feedback on our changes and prevented production incidents by catching defects early in the pipeline. We improved our flow thanks to the reduction in manual testing needed for each card.
These automated tests, together with metaflow (a tool that allows us to easily build and trigger large-scale training on the cloud) helped us avoid the antipattern of needing to push code to find out if something works. We can update our code, run tests locally, get fast feedback, iterate to our hearts’ content and make atomic git commits along the way.
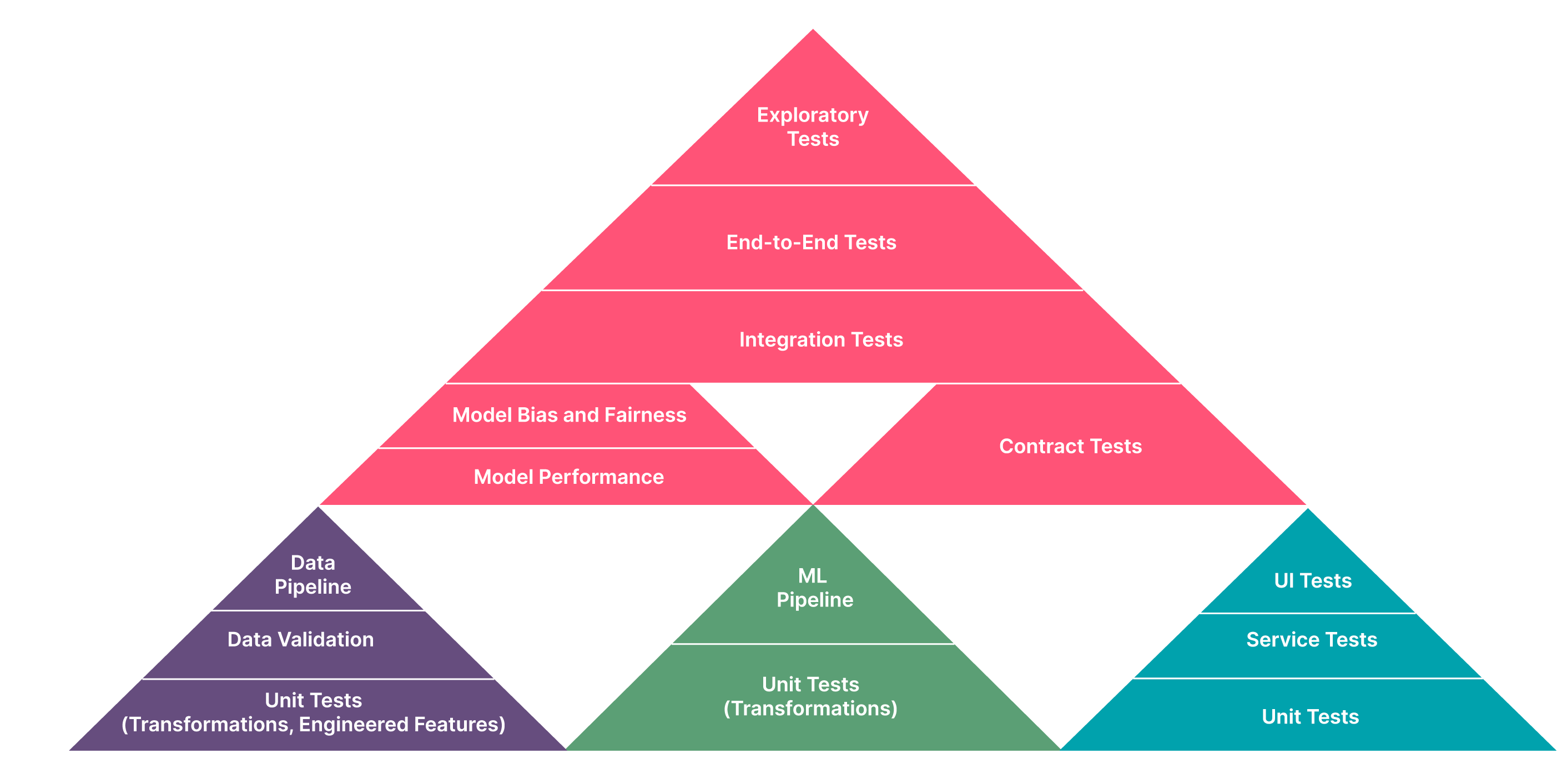
Figure 2: Testing pyramid for machine learning (source: https://martinfowler.com/articles/cd4ml.html)
Research has found that continuous delivery is the foundation of improving delivery performance and product quality. Continuous delivery practices also directly contribute to improving team culture and reducing burnout.
We took that and applied it to machine learning. We automated boring repetitive stuff (e.g. manual testing, software deployments), and freed up our team members for higher-value problem-solving work.
When a code change is committed and pushed, our CI pipeline automates the following:
run the series of tests described above
trigger large-scale training: along the way, training artefacts (data, configuration, models) from every training is stored using metaflow. Training configuration, metadata and model performance is also systematically tracked with every run. These are immutably accessible and help with model reproducibility.
run model quality tests
build and publish our model image to a docker image registry
automatically deploy the image to a staging environment
run post-deployment tests
When the entire CI pipeline is green, it means the trained model has passed all the fitness functions we defined, and we can confidently deploy changes to production.
To build our MLOps culture over time, we continuously reflected on what’s working and what’s not working. We needed to ensure that everyone feels safe to share their opinion and we needed to listen empathically to our teams:
What can we do to reduce the pain and friction?
What can we do to increase their flow and joy?
By combining the aforementioned time-tested delivery practices of high-performing software teams, we’ve kickstarted a culture that helps our team experience less friction, shorten feedback loops and accelerate machine learning and experimentation at REA.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

