














“Most people, when they first hear about continuous deployment, think I’m advocating low-quality code or an undisciplined cowboy-coding development process. On the contrary, I believe that continuous deployment requires tremendous discipline and can greatly enhance software quality, by applying a rigorous set of standards to every change to prevent regressions, outages, or harm to key business metrics.”
- Eric Ries, bestselling business author of The Lean Startup
What is CD?
Continuous Delivery is a software development discipline where you build software in such a way that the software can be released to production at any time. You’re doing continuous delivery when:
- Your software is deployable throughout its lifecycle
- Your team prioritizes keeping the software deployable over working on new features
- Anybody can get fast, automated feedback on the production readiness of their systems any time somebody makes a change to them
- You can perform push-button deployments of any version of the software to any environment on demand
Definition developed by the Continuous Delivery group at Thoughtworks
This definition probably sounds less “scary” than what many of you thought Continuous Delivery meant. It does not say every change that passes automated checks for production readiness will go to production. It just says the software is always in a state where you can deploy it to production. So what’s there to fear? Let’s examine a few...
Scheduling and Status Fears
It may be difficult for the business to understand some of the early work on deployability but it leads to a very different and easy to understand business metric - true feature completeness. Continuous Deliver has an unequivocal definition of done --“a feature is only done when it is delivering value to users.” In order to for a feature to deliver value, it must be released. The product doesn’t just need to work, but it needs to provide enough performance, security, and reliability to serve its users. If you do not adequately address those characteristics then sometimes an otherwise working feature needs to be thrown away and rewritten. This is why we say “unreleased changes are risk; released changes provide value.”
If you are not tracking your project with this unequivocal definition of done, then somewhere between done and “done done” you need to cross the “last mile”:

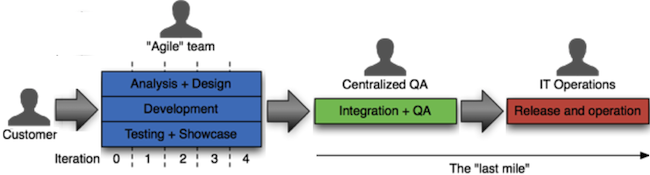
The problem with the last mile is we rarely know how long it will take to cross. If you have delivered 100 features at this point, you may have a very good idea of your development velocity. That doesn’t tell you anything about how long final QA, security hardening, and performance testing will take. If you’re doing continuous delivery you cross this last mile frequently (and with smaller, safer changes), and so have a much better idea of how long it can take, and how it could be improved.
This exercise is an application of the principal “if it hurts, do it more often; bring the pain forward.” This may seem counterintuitive, but it is much like physical exercise. It is painful to start, but soon a previously painful activity will be mundane, and you’ll be ready to take it to the next level. What are the Continuous Delivery “muscles” that need to be developed? Pace and consistency. A quick pace means the last mile will be completed often, and consistency ensures similar result on every attempt. Whenever possible the best way to achieve consistency is by automating. Automated integration testing, automated deployments, automated auditing and change tracking are all important aspects of continuous delivery. Implementing them, including feedback mechanisms for developers, and reporting mechanisms to keep stakeholders in the loop, will result in significant reductions in human errors, miscommunication, and time spent waiting for a certain person. The result will be an efficient, reliable last mile.
You can choose to hold back changes for business reasons, but this enables you to say we are willing to risk delaying the feedback from users for business reasons; rather than being forced to take the risk for technical ones.
Incomplete feedback fears
Organizations may believe that they cannot do continuous delivery unless they can replace all manual testing with a fully automated and reliable test suite. This is not true. Continuous delivery requires that you can get “fast automated feedback on the production readiness of the system”, and that you can perform “push-button deployments.” This means the goal is to automate “almost everything” so you can get the fastest feedback and the most protection from human errors, but this goal can be achieved incrementally.
Since you cannot automate an ad-hoc process, automation has a nice side-effect in addition to making processes faster and more reliable - standardization. In fact, the only thing that truly needs to be automated upfront is a system to track and report progress through the phases of the delivery process. A valid intermediate step towards continuous delivery is a release process that still contains many manual steps, but which are standardized (the QA lead or admin being on vacation does not change the process) and visible to the team. Once this happens, you can incrementally automate the portions of the process that will grant the biggest benefit. A good order is to automate portions that give developers the fastest feedback on the most likely problems, then activities with the highest chances of human errors, and finally things that give developers additional feedback on unlikely problems.
Standardizing and automating these processes provides a nice system of checks and balances to agile development. Agile methods are adaptive and people-oriented to maximize the ability to respond to business change. Continuous delivery provides a predictive and process-oriented validation of those changes so you can consistently know what quality checks have been done before a change goes to production, and often have a good idea of exactly how long the deployment will take (from deploying the same change in the exact same manner to other environments as well as deploying many previous changes to production).
Operations Schedule Fears
Operations can be an extremely unforgiving job. Other roles may experience unpleasant “crunchtime” where they need to work extra hours to push through the last mile, but operations can experience these unpleasant periods anytime there is instability. They are often expected to work nights and weekends, both for deployments that are scheduled to minimize outages during normal business hours, and because they are on-call to deal with unplanned outages. So when we say “if it hurts do it more often” the operations team have no reason to choose to punish themselves more, unless they believe we will increase stability once we get through the growing pains.
Fortunately there are a few reasons for operations teams to be hopeful. “Bring the pain forward” could also be interpreted as “share the pain.” Since the team has prioritized deployability and production-readiness over new features, developers and QAs will be ready to help operations solve difficult problems. This is why Continuous delivery is closely associated with a DevOps culture, which promotes closer collaboration between all roles involved in delivering a change (primarily developers, QAs, and operations). Sometimes this means developers start sharing on-call rotations at companies where that had previously been only for operations. At a minimum, it means developers and QAs can collaborate on things that will make operations easier, like better monitoring or faster deployments.
Studies1,2,3 have shown that this assistance is causing a major turnaround for operations. The benefits also have a compound effect, because these improvements are freeing up operations time, operations is able to make further beneficial changes. They are shifting from reactive to preventive maintenance. Studies1,2,3 have also shown that this DevOps culture (as required for continuous delivery to be successful) results in:
- Higher deployment rates.
- Faster change lead times.
- Lower change failure rate.
- Faster mean-time-to-recover.
- More time spent on productivity boosting activities like automating repetitive tasks, infrastructure improvements, and self-improvement.
- Less time spent on other activities like firefighting, support, communication (meetings, emails and release planning), infrastructure management, and deploying changes.
These results may seem unbelievable at first. How can a team release more often yet spend less time in release planning meetings and deploying changes? Release planning is actually very simple on a Continuous Delivery team. Continuous Delivery aims to ensure the product is always releasable, which means releasing is always a business decision. A regular cadence (like once per day) and techniques that allow you to decide about releasing each feature independently (like feature toggles) make this even easier. The release meeting is just about “Which of these features do you want to go to into production today?”
In conclusion
We have only begun to discuss the possibilities of Continuous delivery. The discipline opens up many options that can greatly improve quality assurance, reduce production failures, avoid after-hours deployments, and allow the business to rapidly pivot to improve key business metrics. Although we did not have the space to discuss these advanced techniques, we hope we showed that getting started with continuous delivery should not be a scary proposition. Continuous delivery is not the cowboy coding you may have feared; it is the disciplined and beneficial process Eric Ries described.
1 https://puppetlabs.com/2013-state-of-devops-infographic
3 http://www.zdnet.com/devops-really-does-speed-things-up-study-shows-7000020783/
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.