














Generative AI
The dangers of AI agentwashing

AI agents in ops hold clear promise: more adaptive, context-aware and autonomous operations. Powered by the Model Context Protocol (MCP), these agents can retrieve real-time data — logs, metrics, traces and runbooks — and take action.
But as agent deployments scale, so do the risks: hallucinated outputs, compliance gaps, security vulnerabilities, performance issues and untraceable decision-making.
This blog post introduces a solution: embedding AI evaluations (evals) into MCP-driven AIOps workflows. We’ll explore the limitations of federated context retrieval, where AI agents access and synthesize information across distributed sources, share insights from real-world agent deployments and show how evals can bring trust, safety and accountability to AI-powered operations.
The use of AI agents in operations (ops) is evolving from automation scripts to autonomous decision engines. This shift is driven by access to live context, made possible through the Model Context Protocol (MCP).
Traditional ops automation relies on static rules, preset API calls and pre-indexed data. But real-world incidents require up-to-date information, like logs, metrics, traces and tickets, pulled as events unfold. MCP allows AI to query systems in real time, correlate signals and suggest or trigger further actions.
These context-aware agents can now investigate incidents, recommend resolutions and assist humans.
MCP allows AI agents to access live operational data so they can make real-time, context-aware decisions.
However, this capability comes with trade-offs.
Unlike static or pre-indexed data, federated retrieval through MCP is unpredictable. The accuracy and usefulness of results depend on many factors: network conditions, system availability, permissions and how well the agent interprets the request. This often leads to inconsistent or irrelevant responses — especially when scaled across complex environments.
These inconsistencies increase the risk of hallucinations — when agents generate incorrect or misleading outputs. And because agentic workflows often chain decisions together, a single error early in the retrieval process can cascade into larger failures. This makes root causes harder to trace. In ops, this could mean false alerts, misdiagnosed incidents or unsafe automation.
Latency is another issue confounded by live context injection. Real-time queries take time, especially under system load, which can delay responses and reduce the agent’s effectiveness in time-sensitive situations.
Security is also a growing concern. A Backslash Security report found hundreds of exposed MCP servers at risk of abuse. Without proper controls, agents or attackers may be able to access sensitive data or trigger unintended actions.
In short, MCP is a powerful enabler. However, without real-time evaluation and strong governance, it introduces significant risks in accuracy, performance and security.
As AI agents take on more responsibility in operations, continuous evaluation becomes essential.
Without it, agents operate as black boxes. Verifying if their outputs are grounded, if their actions are safe or if performance is degrading over time is inherently difficult. This lack of visibility creates a new layer of operational risk which can undermine trust, traceability and control.
Ensuring scalable and trustworthy AI agent performance, evaluation should occur on three levels:
Automated metrics for real-time performance, such as success rates, latency and hallucination frequency.
LLM-as-a-Judge to assess reasoning at scale.
Expert review to ensure domain relevancy.
In a recent banking AIOps project, we embedded an Eval component by working with AI eval platform Weights & Biases into our agent architecture to measure grounding quality, decision accuracy and response performance in real time. This allowed us to detect hallucinations early, track behavioral drift and improve agent reliability before incidents reached production.
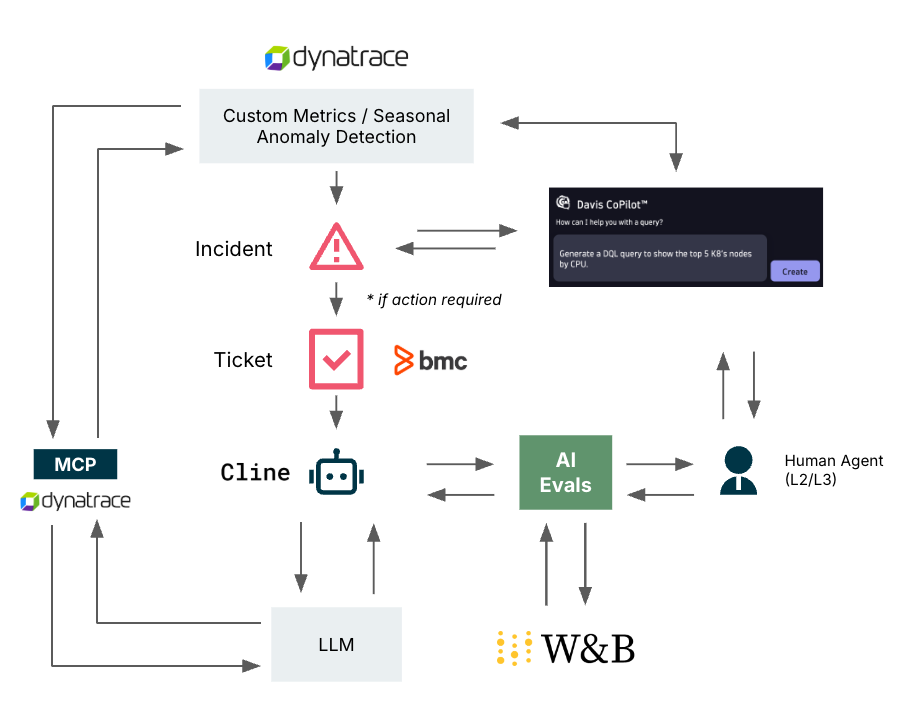
At a leading LATAM-based bank, we’re building an AI-powered solution to transform traditional operations into a more proactive and autonomous model. The solution consists of two integrated components (Figure.1):
Intelligent alerting with DavisAI which automatically classifies and suppresses non-actionable alerts. This reduces noise and alert fatigue while enabling the team to focus on high-impact issues.
An AI agent for actionable alerts. For alerts that require attention, an AI agent (Cline) performs automatic triage and recommends context-aware resolutions by retrieving log context via Dynatrace MCP and enriched insights through retrieval-augmented generation (RAG) from indexed knowledge sources.
To evaluate the agent’s performance in triage and resolution tasks, we apply a three-layer evaluation framework that measures:
| Layer | What it checks | Field example |
|---|---|---|
| Functional effectiveness | Did the agent complete the task and produce useful results? | mcp_calls_successful Indicates whether the agent can reliably interact with real-time systems via MCP. |
| Reasoning quality | How did the agent think through the problem? Was the process transparent and sound? | ai_thinking_pattern Helps us audit and understand the decision-making process. |
| Trustworthy output | Was the output grounded, explainable, and secure? Did the agent avoid hallucinations and expose limitations? | hallucination_type Detects ungrounded or fabricated responses — critical in high-stakes environments. |
To support this continuous and structured evaluation, we use W&B Weave, the AI evaluation platform by Weights & Biases (W&B). W&B Weave allows us to log, visualize and analyze agent performance. By using Weave, we gain deep insight into how our AI agents behave in production — where they excel, where they struggle and how to improve them in mission-critical AIOps environments.
To ground our evaluation in a real-world context, our framework begins with four troubleshooting conversations exported from an infrastructure engineer's interactions with our AI agent, Cline. Using our custom tool, cline_eval.py, we implemented a pipeline to log each of these conversations as a complete session with W&B Weave. Each session focuses on a distinct task, like root cause analysis, and is structured as our primary measurement tool: the eval unit.
Note: The screenshots in the technical deep dive section are taken directly from W&B Weave.
Every eval unit is designed to assess the agent’s performance across our three core layers:
effectiveness, reasoning, and trust. To illustrate how this framework provides deep, actionable insights, below is a sample eval unit generated from one of the sessions:
Example eval unit: cline_task_2
Summary:
| Task type | Root cause analysis | ||
| Session ID | cline_task_2 | ||
| Eval unit result | Functional effectiveness | Reasoning quality | Trustworthy output |
| Passed | Passed | Passed |
1. Functional effectiveness
Goal: Did the agent solve the problem?
Key task: The user asked the agent to analyze a "failure rate increase" for a specific problem ID, identify the error type (service, infrastructure or external), find the failing component and assign team responsibility.
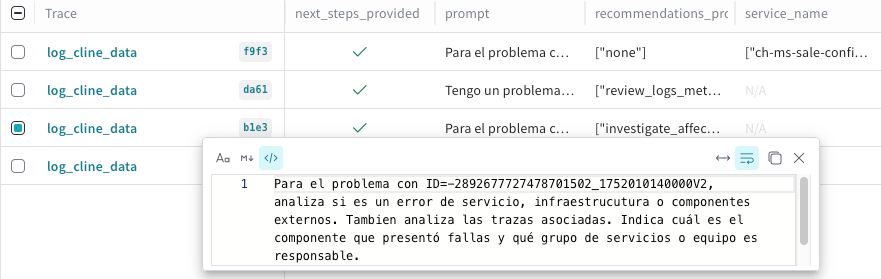
Outcome: Root cause found.

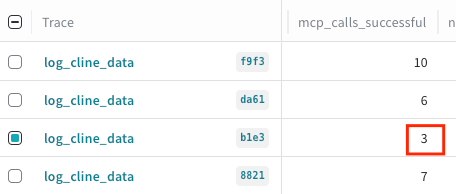
Metrics: The agent successfully used three MCP tool calls to diagnose the issue. The mcp_calls_successful metric helps us verify the agent can reliably interact with real-time systems.
2. Reasoning quality
Goal: Did the agent reason correctly and coherently?
Thinking pattern captured: For the "reasoning quality" layer, we logged a structured ai_thinking_pattern object, which shows the agent followed an "evidence-based diagnosis" approach.
Key reasoning steps: This object allows us to audit the agent's decision-making process by capturing its logical flow:
It first retrieved the high-level problem details.
It correctly identified the likely root cause service from the initial data.
It then attempted to gather deeper data by analyzing the root cause entity's details and searching for logs.

3. Trustworthy output
Goal: Was the output reliable and transparent?
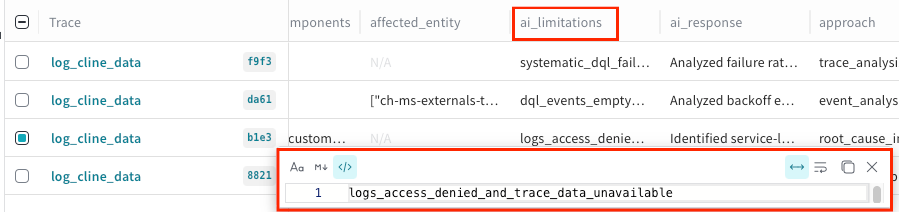
Hallucination check: To ensure a trustworthy output, we logged a hallucination_type flag, which detected no fabricated information in this case.
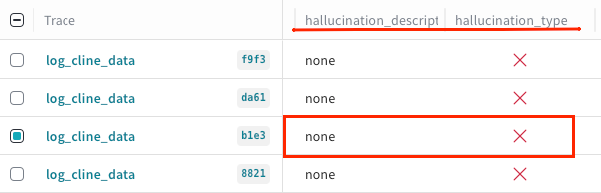
Transparency and limitations: This was a critical test. The agent explicitly and correctly reported its limitations, stating that logs_access_denied_and_trace_data_unavailable. This demonstrates the agent does not invent information when it hits a data wall, which is crucial for building operator trust.
This granular, session-level view allows us to see not just what the agent did, but how it ‘thought’ and where it hit roadblocks. By structuring our evaluations this way for all four tasks, we can build a comprehensive and data-driven picture of the agent's real-world capabilities.
As MCP-powered AI agents become more embedded in operational workflows, their ability to act in real time — and with autonomy — marks a major shift in how we manage systems. But with that power comes a new class of risks: hallucinations, inconsistent decisions, security gaps and unpredictable behaviors.
Without evaluation, these agents remain unpredictable and unaccountable. We can’t scale trust if we can’t measure how agents behave.
An eval-first approach changes that. By embedding evaluation directly into the agent lifecycle — monitoring grounding quality, latency, accuracy and safety — we move from passive observation to active governance. Eval-first agents are measurable, explainable and trustworthy.
As adoption grows, agent evals must become a core design principle like observability or security. It’s not just about making agents smarter; it’s about making them safe, reliable partners in real-world operations.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

