














Testing
Get back to basics with testing data pipelines: two orthogonal planes

When I started learning about data pipelines, although there were lots of resources explaining how to get up and running with development, there was little on the subject from a testing and quality assurance perspective. This was a shame, because building a quality data pipeline requires rigorous testing and various checkpoints to ensure that your code — and, by extension your data projects — work as intended. Getting it right is important to the overall success of your data pipelines, however they are being used.
However, over time, I have found that shifting testing left (ie. doing it earlier) when building a data pipeline can really help detect problems quickly. By moving quality checks upstream — to a point before data is loaded to the data repository — you are much better placed to overcome any issues that may be lurking inside data sources or in the existing ingestion and transformation logic.
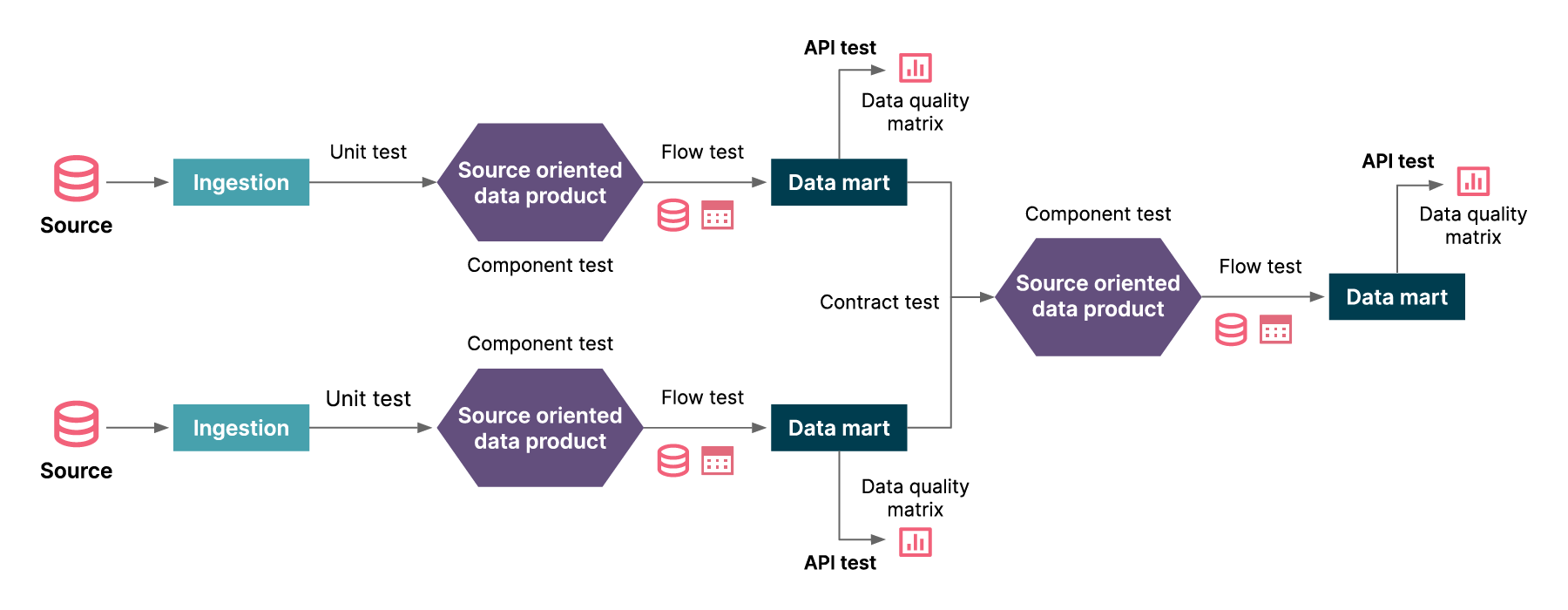
Doing this effectively requires a testing strategy. Simply going ahead and writing tests and attempting validation aren’t going to help; it’s important to identify what to test and where.
This strategy requires input from all stakeholders in the process, and will ultimately need common understanding and alignment to work properly. Ultimately, it should bridge the gap between high level objectives to the practical implementation of actual test activities.
A good way of conceptualizing a testing strategy is with what’s called the testing diamond. It outlines the tests that need to be done, while also highlighting the size of the respective tests and the amount of time and cost required to do them.
Here are the list of things that comprise a testing strategy:
Data quality matrix
Functional test
Source test
Flow test
Contract test
Component test
Unit test
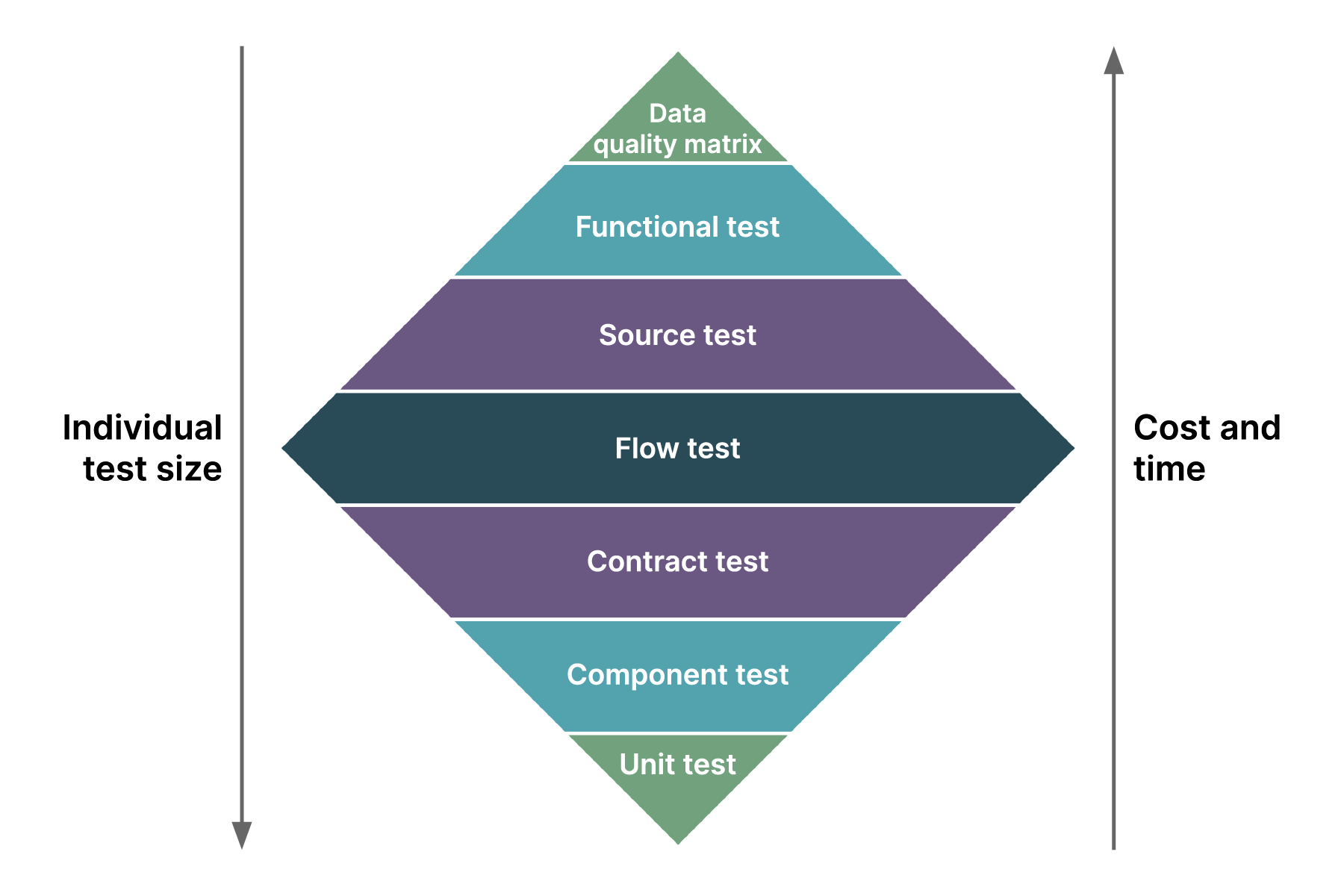
In the context of testing data pipelines, we should understand each type of test like this:
Data unit tests help build confidence in the local codebase and queries
Component tests help validate the schema of the table before it is built
Flow tests make up the maximum volume and coverage and help build confidence.
Source tests help validate data values meet expectations after transformation
Functional tests help validate the business use cases
Let’s now take a look at what these tests look like in practice.
Once the data is available in the data platform, you can then run queries to transform columns that will then generate the expected output as a data product.
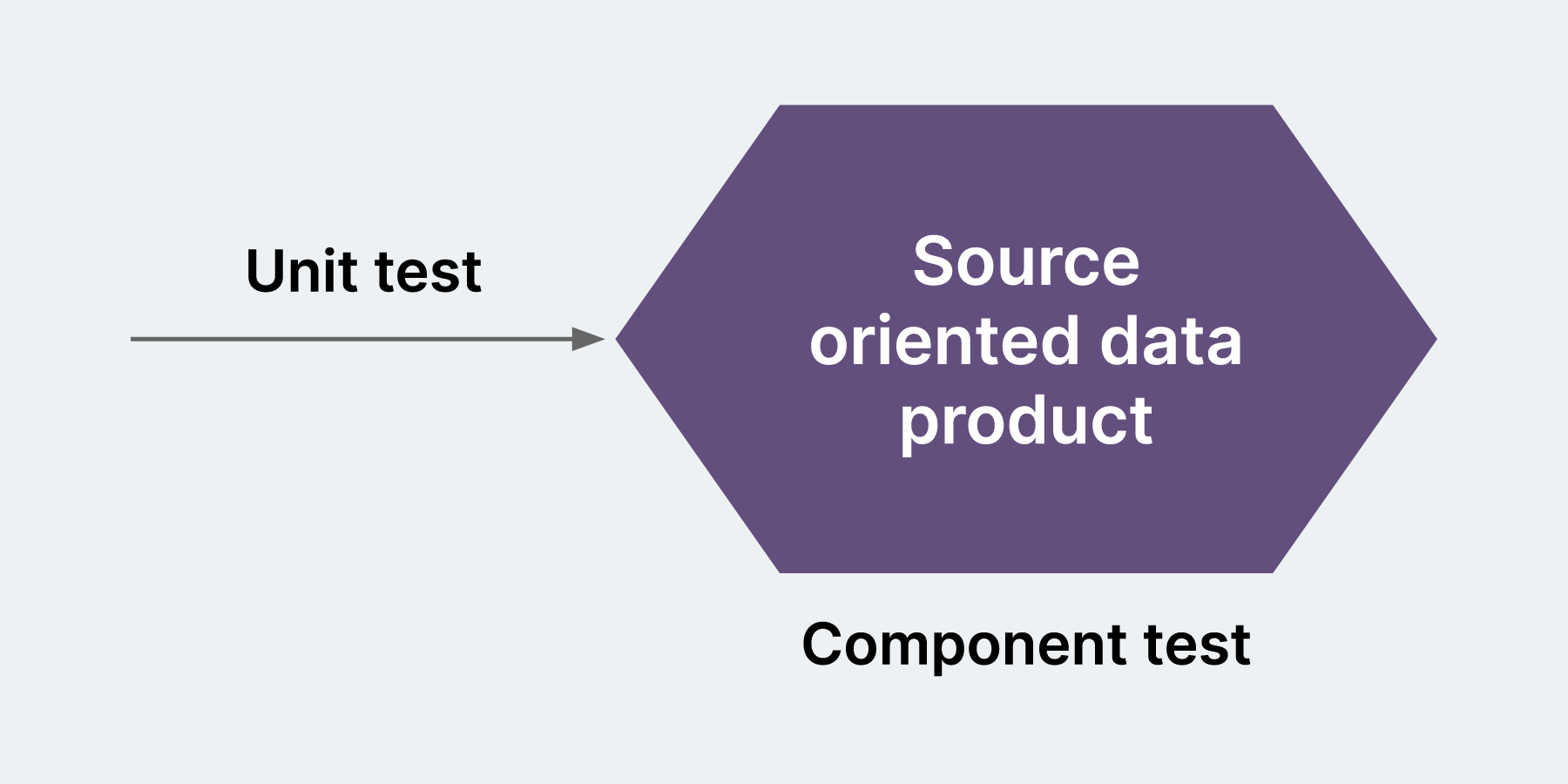
To validate transformations, each logical unit of code can be tested with a data unit test. A data unit test will use a different possible combination of data values with positive and negative scenarios in a .csv file to be used as dummy data for the test. It will test whether each logical unit of the code is executable and performs expected task or function (e.g. SQL query)
Component tests provide schema validation of every row and column to verify that data has been correctly transformed according to business rules. It checks integrity across columns.
It tests whether each logical running component (many units) is executable and gives an expected output (for example, if we create a table, it will validate the schema of the table) and follows naming conventions.
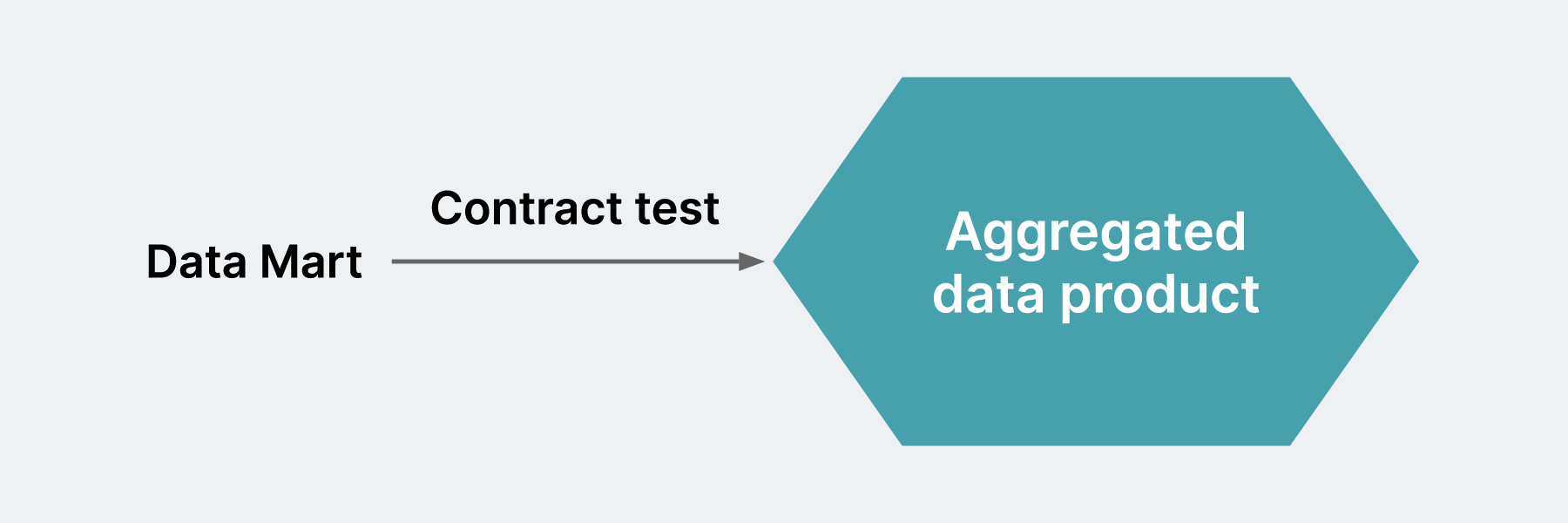
Once the table is deployed on the data platform’s data mart, a contract between the source table in the data mart layer and the aggregated table needs to be maintained for the columns to be consistent and available in the source table.
This is done using a contract test; it will validate that the consumed columns are always present in the source table in the data mart.
This test will ensure that consumers of a data product can keep consuming the data product after changes are made. The contract is between a consumer and a provider of the data.
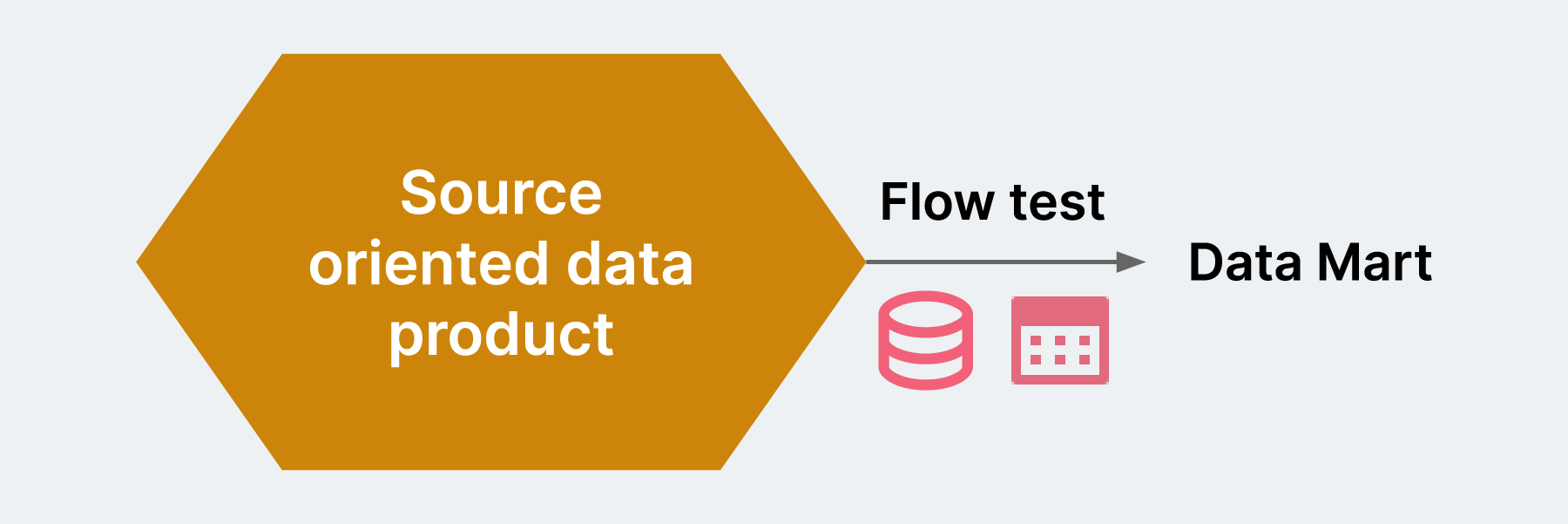
Once the data is transformed and is deployed into the data platform’s data mart layer, we need to validate the live data using flow tests; this validates completeness, accuracy and consistency of the data expected for the business scenario.
Testing one or many logical components with real data, with validation like 100% of the data is migrated, no data loss. Represented in the same way as in the source, Mappings are correct, Null, Duplicate, Precision check, Special chars are represented correctly.
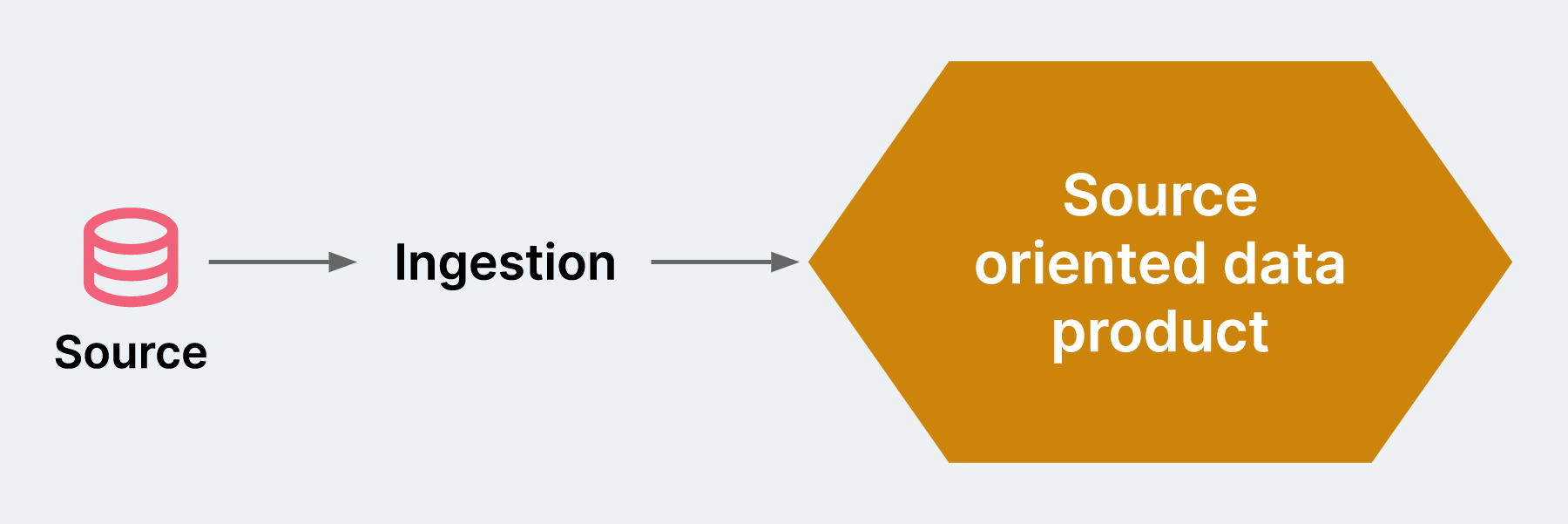
A source test, in the context of data pipeline testing, ensures ingested data is transported to the target platform without loss or truncation. It’s a useful step in protecting the integrity of data and making sure that what you get — after it is ingested — is what you expected.
Consider a scenario from the manufacturing industry. Here, we may need to represent the status of the inventory; to do this, we’d need inputs like:
Available material
Incoming material from the purchases order
Information about the plants
A source test would validate the dates — what we might consider the “freshness” — of all the source data. It would also help ensure columns are structured correctly, and that they are properly aligned with the row count.
Tests ensure projected data is added to the target data platform without loss or truncation, and that the data values meet expectations after transformation.
Once the webservice, data product (tables), visualization dashboard, reports or analytics are ready and have been deployed to an environment, we need to validate whether the integration of all the components perform as users would expect. As we have validated the components separately, including the happy paths and negative scenarios, it’s only expected that we validate the happy path of the user journey and highly probable business scenarios using the API endpoint or UI tests.
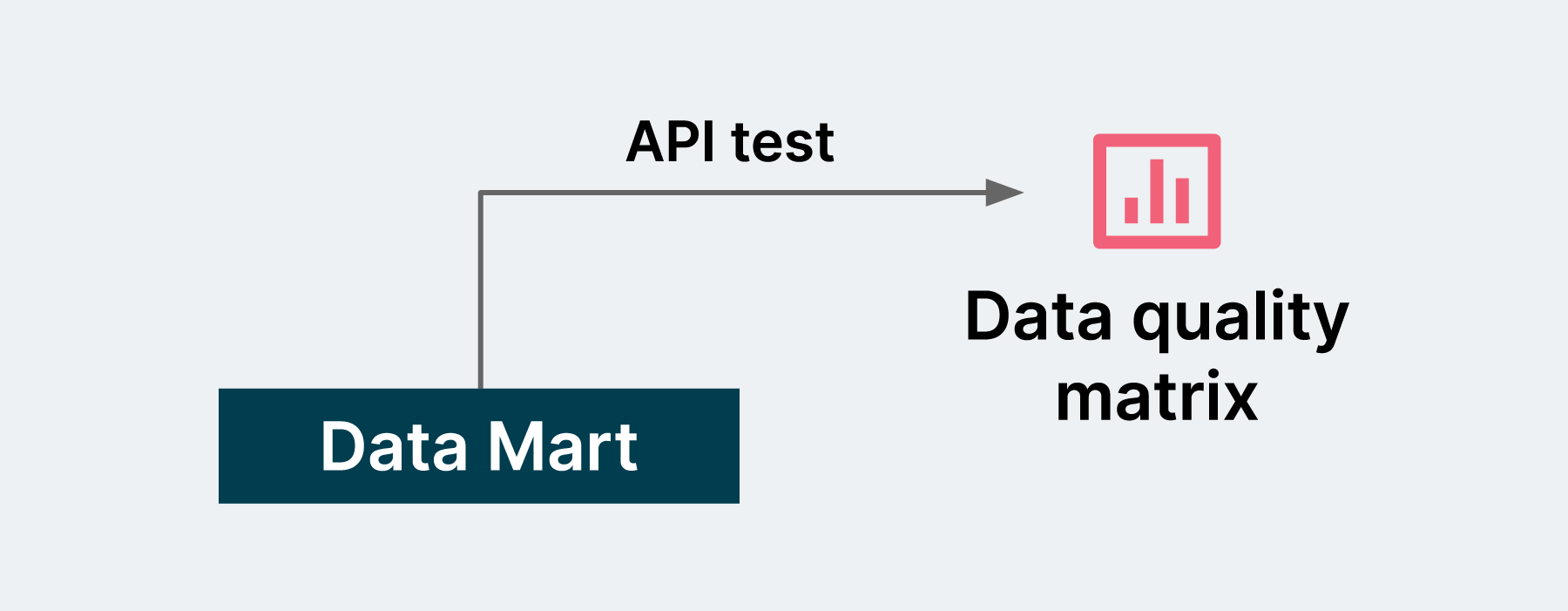
Data Quality Matrix helps to validate the degree to which data is accurate, complete, timely, and consistent with all requirements and business rules.
Following are a few example assertions:
Proportion of column values that are not NULL
Proportion of unique column values
Count of unique column values
True if all column values are unique
Minimum column value
Maximum column value
Average column value
Population standard deviation
Sample standard deviation
The Test Diamond validates business requirements and should ensure that any new changes won’t break production. However, there are a number of other requirements that aren’t addressed in the test diamond that are nevertheless very important. These are non-functional requirements — they help us to predict potential issues in the existing code in production that could break.
Managing and validating authentication, authorization, user control, and shared decision making (e.g. planning, monitoring, and enforcement) over the management of data assets become very important when it comes to data projects. As there are many laws around the governance of data and its use, no PII should be authorized or should be shared. Once the data products are live, distribution of the same needs to be regulated and monitored for enforcement of the governance rules.
The data that we are using creates dashboards and analytics that need to be profiled. Checkpoints of syntax validation like invalid characters, pattern, case order and reference validation like number, date, precision, null check to make sure the application rejects, accepts values, and reports invalid data. This also created historical data to measure the quality of the current data being processed.
Performance and scalability, reliability, availability, maintainability and usability of the application needs to be monitored.
Performance and scalability
How fast does the system return results?
How much will this performance change with higher workloads?
Reliability, availability, maintainability
How often does the system experience critical failures?
How much time is available to users against downtimes?
Usability
How easy is it for a customer to use the system?
The degree to which data is accurate, complete, timely, and consistent with all requirements and business rules.
All the layers we talked about make sense for many different possible domains and businesses. When building a quality strategy one should analyze which layers make sense and which don’t and review them after every release or every few iterations of a development cycle. As quality is relative in terms of data as one cannot write validation or checkpoint that has an actual outcome to an expected comparison. It is always what the data owner thinks is the best possible quality aspects that work for the data product and pipeline.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

