














Infrastructure as Code, 3rd Edition

After some years working on Infrastructure automation, it became evident to me that automation with Terraform isn't as simple as writing some .tf files, running terraform apply and walking away. As your system grows, you start to crave sensible patterns, a neat project structure and quick feedback for devs when they tweak things.
Fortunately, Kief Morris's book Infrastructure as Code gives us a vocabulary for these patterns. This is thoroughly discussed in Chapters 7 and 8. In this post I borrow a number of terms from him, sketch out the common stack patterns he describes and show how Terraform's partial backend configuration can help you build the recommended pattern he has pointed out. Along the way I point to concrete examples from my repo terraform-infra-automation.
Key terminology
First up, here are few terms I will be using throughout the blog:
Infrastructure stack. Kief Morris defines infrastructure stack as the smallest independently deployable unit of infrastructure, a self-contained bundle of servers, databases, networks and policies you can build, test and release as one. From Terraform's perspective, it's the root module where you have .tf files and you run terraform commands.
Stack instance. This refers to a deployed copy of the infrastructure stack; there’s usually one per environment or team.
Product team. These teams are cross-functional teams; they’re responsible for application and the underlying infrastructure. This is similar to a stream-aligned team, defined in another book, Team Topologies as a team aligned to a single, valuable stream of work which is empowered to deliver user value quickly and independently.
Platform team. Also defined in Team Topologies, platform teams create services that accelerate stream-aligned teams by removing complexity. They enable stream-aligned teams to deliver work with substantial autonomy. Some platform teams I worked for took responsibility for providing and maintaining infrastructure resources used by product teams.
Snowflake as code stack: Snowflakes in practice
The Snowflake stacks are very easy to spot. For product teams, they often look like:
infra/
dev/
main.tf
test/
main.tf
prod/
main.tf
modules/
ec2/
s3/
networking/
Each terraform root module has the remote backend configuration hardcoded (because it cannot be parameterized) and has modules (which call a child or published module) or resources definitions. In this pattern, updating a variable means touching every single folder or root module.
For platform teams which maintain a product team's infrastructure, this problem multiplies.
infra/
team1/
dev/
main.tf
test/
main.tf
prod/
main.tf
team2/
team3/
....
modules/
ec2/
s3/
This setup will provide state isolation between teams and their environments. But if they manage infrastructure for 10 product teams, each with dev/test/prod folders, a simple VPC patch becomes 30 updates. As Kief Morris warns, this level of code duplication breeds configuration drift and makes testing very challenging and mentions this as an antipattern.
Deployment wrapper stack: Cleaner, but not the best
The wrapper stacks tries to avoid code duplication. Each environment or root module gets its own thin project that imports shared modules with separate remote backend configuration:
infra/
dev/main.tf -> module dev_stack { source = "../common-module"}
test/main.tf -> module test_stack { source = "../common-module"}
prod/main.tf -> module prod_stack { source = "../common-module"}
common-module/
vpc.tf
ec2.tf
iam.tf
var.tf
This centralizes module logic. In some projects this also becomes a higher order child module, which then refers to other child modules that are created around specific resources.
root-module -> higher-order-module -> child-modules
However, these wrappers are still overhead. When the functionality of the centralized module isn’t defined, it can easily bloat and become hard to debug.
Separate project or root modules for each environment will still tempt devs to add custom configurations directly on the root module instead of the common-module. This can lead to configuration drift. In one old project we had to implement a quality gate using OPA/conftest to prohibit developers from adding any additional resources or module blocks in the root module other than the common-module definition.
Reusable stacks: The antidote
In this pattern we have one stack project and spin many stack instances from that. The differences (like environment name, region, or instance size) in stack instances come from parameters and not copy-pasted code.
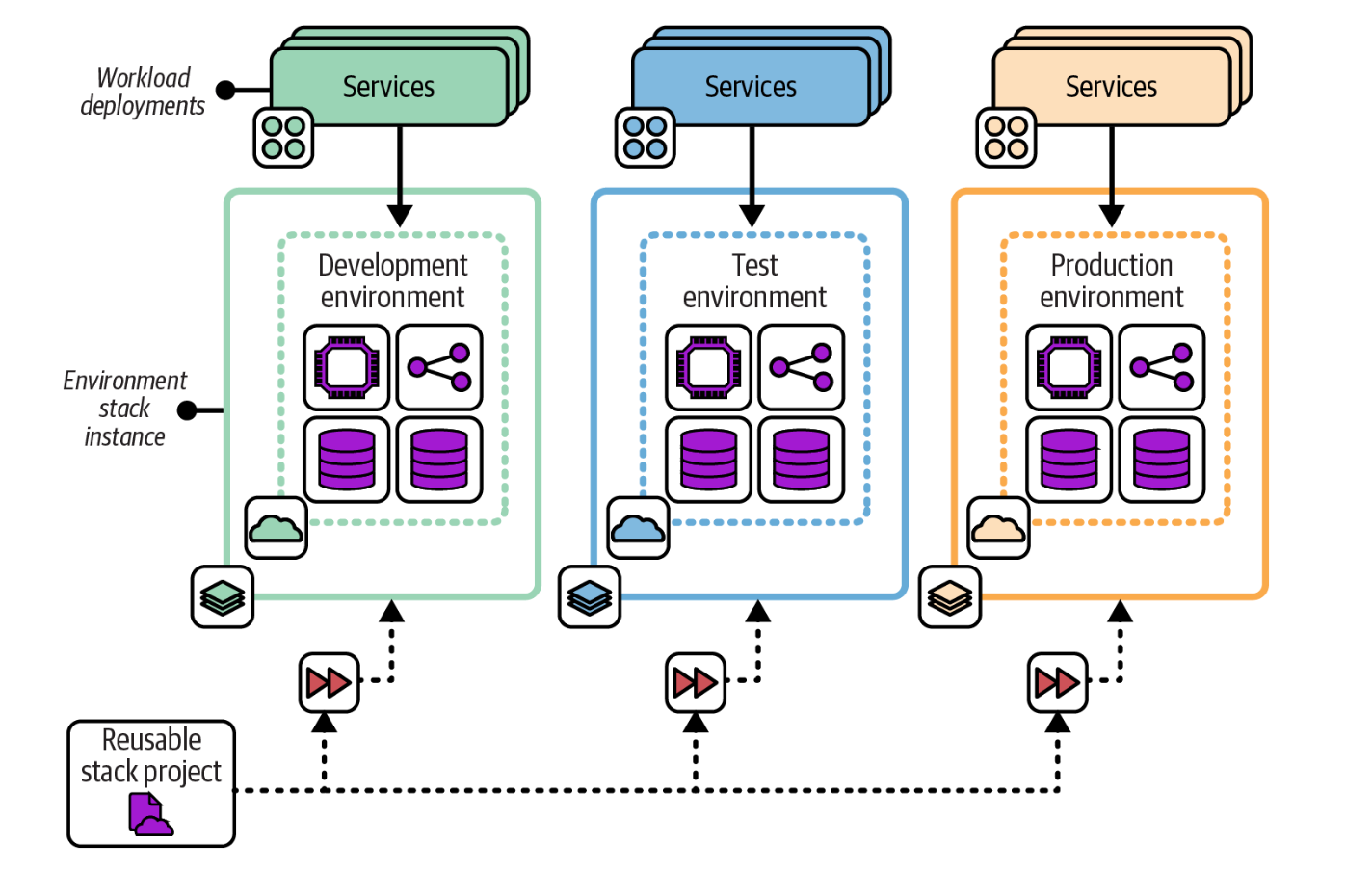
Picture courtesy: "Infrastructure as code, 3rd Edition , Chapter 7"
Snowflake and deployment wrapper patterns have their challenges but they reduce the blast radius because each Terraform project or root module will have its own remote state configuration.
When we say that there’s going to be one terraform project or root module, by now your Spidey senses should be tingling: are you really going to have one remote backend configuration for every stack instance? It can’t be parameterized! Well, yes it can't be parameterized — but we can at least partially define it...
Enter Terraform's partial backend configuration: instead of hardcoding all backend settings, you just leave some open (like bucket, key, region) and pass them at terraform init time:
terraform {
backend "s3" {}
}
You then initialize with the right state location:
terraform init \
-backend-config="bucket=<BUCKET-NAME>" \
-backend-config="region=<REGION>" \
-backend-config="key=stack_1/<STATE-FILE>" \This allows the stack project/root module to be fully customizable including the remote backend configuration. This means we can have one project and many isolated stack instances with isolated state. So, whenever we or the pipeline performs any Terraform operation we must first initialize with proper backend configuration and then proceed to run, plan or apply.
Lets see this in action with an example…
Example 1: Product team: Reusable stack pattern
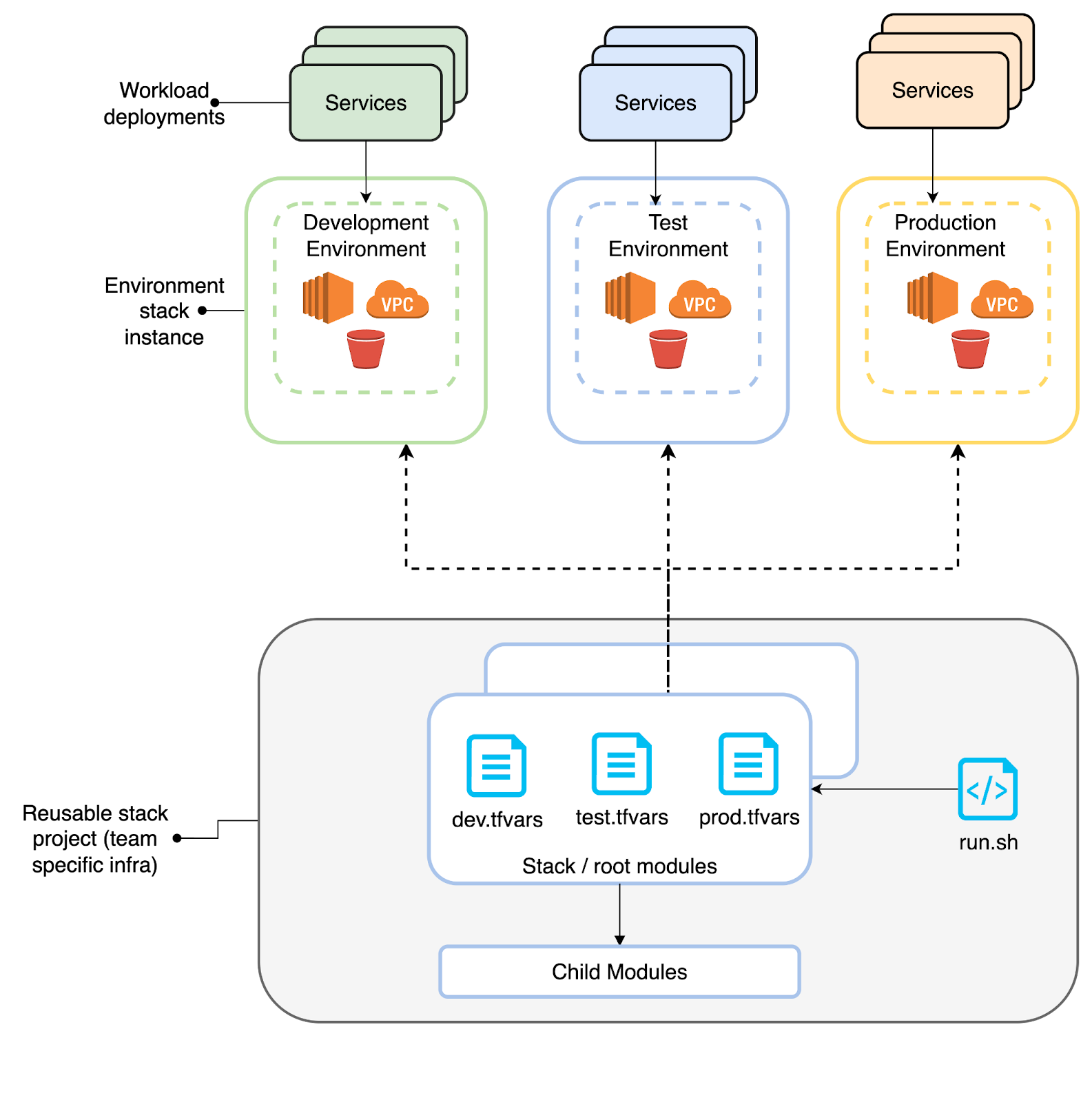
In this example codebase lets assume the product team only has one stack (stack_1) which is deployed across multiple environments. In real time they can have more than one, based on the complexity of their application, or they may be responsible for another product (they could, for example, be maintaining a data product infrastructure in another stack).
team-specific-infra/
├── modules/
├── scripts/
├── stacks/stack_1/
│ ├── dev.tfvars
│ ├── main.tf
│ ├── prod.tfvars
│ ├── qa.tfvars
│ ├── variables.tf
│ └── README.md
└── run.sh
Modules/: Contains terraform child modules.
Stacks/: Infrastructure stack code (stack_1/main.tf, variables.tf).
Env tfvars: contains values for the variables defined in the root module and also has values to set up the remote backend for every environment (dev.tfvars, qa.tfvars, prod.tfvars).
Let's take a look at the tfvars file:
# Backend configuration
backend_bucket = "my-terraform-state-dev"
backend_key = "stack_1/terraform.tfstate"
backend_region = "us-east-1"
# Resource-specific variables
environment = "dev"
bucket_name = "my-dev-bucket"
instance_type = "t3.micro"
ami_id = "ami-12345678"
key_name = "dev-key"
Scripts: run.sh and scripts/terraform-runner.sh automate Terraform operations for individual stacks and environments. They:
Parse arguments to select the stack and environment.
Extract backend configuration from environment-specific .tfvars files.
Run terraform init with remote backend settings for state storage.
Execute Terraform commands to provision, update, or destroy resources as defined for each team’s environment.
Command flow:
./run.sh stack=stack_1 env=dev command=init
./run.sh stack=stack_1 env=dev command=applyThanks to the partial backend configuration, each environment now gets its own state without duplicating stacks or Terraform projects. This reduces the overhead of maintaining multiple terraform projects and avoids code duplication.
Example 2: Platform team: Reusable stack
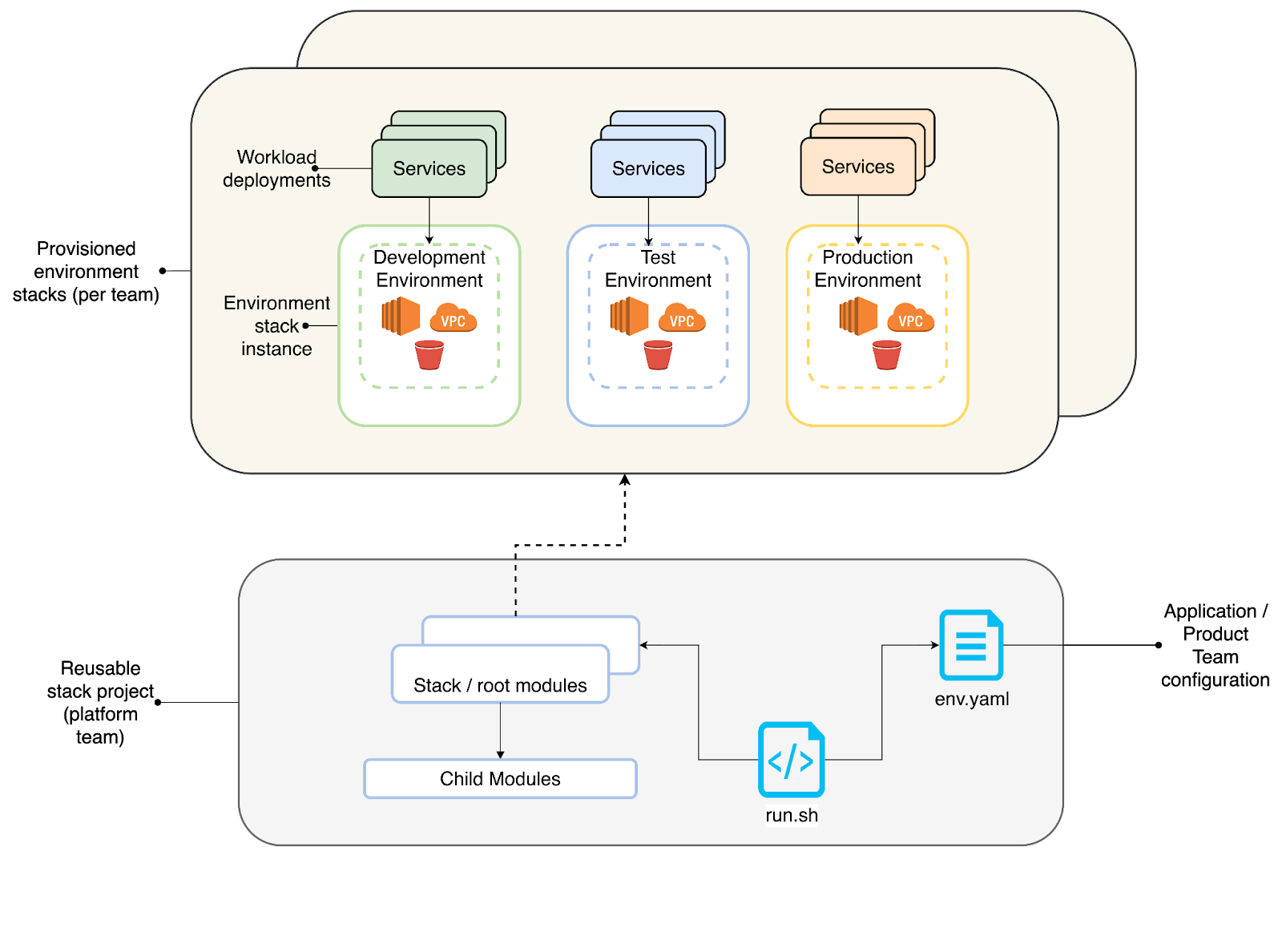
In this example, we assume that the platform team maintains one stack (stack_1) which is used by multiple teams across multiple environments. In reality they can have more than one stack — they might have multiple stacks to cater different product teams in their organisation which uses similar infrastructure components. e.g
stack_1 (website stack): Creates a container service for deploying front end applications with load balancer and WAF. Creates a backend service that runs inside a secure network.
stack_2 (data product stack): Creates infrastructure to create data products
platform-infra-manager/
├── modules/
├── scripts/
├── stacks/stack_1/
│ ├── main.tf
│ ├── variables.tf
│ └── README.md
├── env.yaml
└── run.sh
env.yaml: Provides a centralized configuration file for environment-specific and team-specific settings. By managing this file in a federated, platform-owned repository, platform teams can offer a self-service workflow where product teams propose configuration changes through pull requests for review and approval. It also defines variables and backend configuration for different stacks, teams and environments.
Scripts: Scripts (run.sh and terraform-runner.sh) automate Terraform operations for platform-wide infrastructure across multiple teams. They:
Parse arguments to select the stack, team, and environment using yq.
Extract configuration from a centralised env.yaml file.
Run terraform init with backend settings for each team/environment.
Execute Terraform commands to provision, update, or destroy infrastructure resources as defined in the platform’s configuration.
Let's take a look at the env.yaml file:
common_backend_config:
region: "us-east-1"
stack_configs:
- name: "team1"
environment:
dev:
remote_backend:
bucket: "my-terraform-team1-dev"
key: "terraform.tfstate"
app_config:
instance_type: "t3.micro"
ami_id: "ami-12345678"
key_name: "team1-dev-key"
qa:
remote_backend:
bucket: "my-terraform-team1-qa"
key: "terraform.tfstate"
app_config:
instance_type: "t3.micro"
ami_id: "ami-12345678"
key_name: "team1-qa-key"
prod:
remote_backend:
bucket: "my-terraform-team1-prod"
key: "terraform.tfstate"
app_config:
instance_type: "t3.micro"
ami_id: "ami-12345678"
key_name: "team1-prod-key"Command flow:
./run.sh stack=stack_1 team=team1 env=dev command=init
./run.sh stack=stack_1 team=team1 env=dev command=applyThis lets a platform team provision infrastructure for multiple product teams from one project, while keeping states cleanly separated. Again, the partial backend config setup helps us avoid maintaining multiple terraform projects or root modules thereby avoiding code duplication.
What are the trade-offs of this solution?
As with any other solution, it doesn’t solve everything — there are some trade-offs you will need to weigh up.
- Script complexity. The shell scripts (terraform-runner.sh) are effective for this pattern, but as your logic grows, you'll inevitably face a "build vs. reuse" decision. One path is to evolve your custom script into a more robust internal CLI tool using Go or Python. This gives you maximum control and tailors the solution perfectly to your workflow. The other way is to use tools which support reusable stack patterns like terraspace and terragrunt. In my opinion, Terraspace is very close to the example you saw above using the script with a lean code structure. In addition, it also provides features to test the stack code using Ruby RSpec and can automatically create the backend container/bucket for storing the remote state file. To use it effectively some level of ruby knowledge is required — sometimes viewed as a downside.
- Multi-stack dependency. A key challenge arises when we have multiple smaller stacks with dependencies between them (e.g., a networking stack that must be applied before an application stack). In the long run, maintaining the correct execution order and managing outputs from one stack as inputs to another can become difficult. It's important to have a clear and compelling reason for splitting infrastructure into multiple stacks, because doing so adds complexity.
- Parameter overload. tfvars and YAML should stay lean. Too many knobs will lead the stacks to diverge.
- Parameter type complexity. Complex variable types require complex code to parse it. Keep it as simple as possible.
Conclusion
Terraform’s partial backend configuration gives you a flexible way to implement reusable stacks without sacrificing isolated state. By parameterizing backend settings at initialization time, you avoid hard‑coding environment‑specific values and eliminate the drift associated with copy‑paste or wrapper patterns. When combined with clear patterns for structuring your stacks, this approach can dramatically simplify infrastructure automation. While it’s not a silver bullet — do keep an eye on the trade offs — in most cases it provides a clean and scalable path forward.
I deliberately skipped mentioning Infrastructure testing. No matter the pattern you follow, if you don’t have a testing framework in place to help you get rapid feedback, you are doomed. However, there’s no need to worry — Kief Morris covers testing strategies for infrastructure in Chapter 18 of Infrastructure as Code.
Acknowledgements
I'd like to extend my gratitude to Kief Moris for the invaluable "Infrastructure as Code" book. My thanks also go to Ankit Wal for his thorough feedback and review, and to Fiona Coath for their careful read and comments.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

