














Article
Data Mesh in practice: Getting off to the right start (Part I)

This is the fourth article in a series exploring the key practices and principles of successful Data Mesh implementations. You can read part one, two and three here. The practical learnings explored herein have all come from our recent Data Mesh implementation engagement with Roche. However, the use cases and models shared have been simplified for the purposes of this article, and do not reflect the final artifacts delivered as part of that engagement.
In our last two articles, we’ve looked at the operating model and product streams of our Data Mesh discovery process. Now it’s time to turn our attention toward the technical stream, and look at the architectural decisions that organizations need to make along their journey to Data Mesh success.
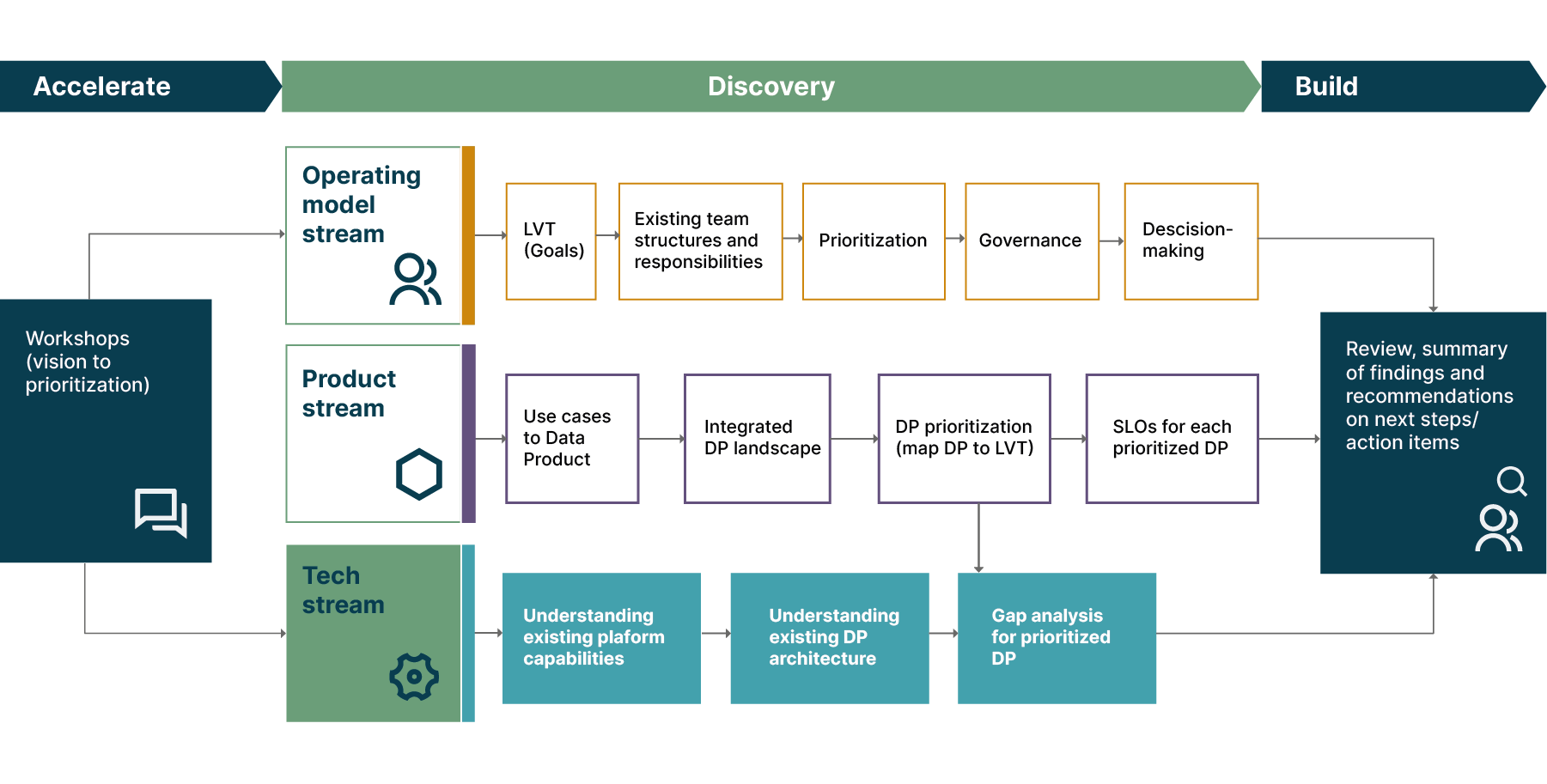
Much like the operating model and product streams, the technical stream also has a very important output asset — a Data Mesh logical architecture, as shown above. This logical architecture maps out each domain’s data products across the Data Mesh, and provides a clear overview of:
Which domain owns and is responsible for which data products
Which use cases are served by data products, including how different data products come together to support further use cases
The users of each data product, showing how they consume data products using polyglot output ports
How data products are consumed and what value-creating actions are taken based on the insights from consumer data products
The operational systems that are the sources or system of records for data ingested into the data products
The capabilities that make up the self-service platform that provides the foundation for the Data Mesh model.
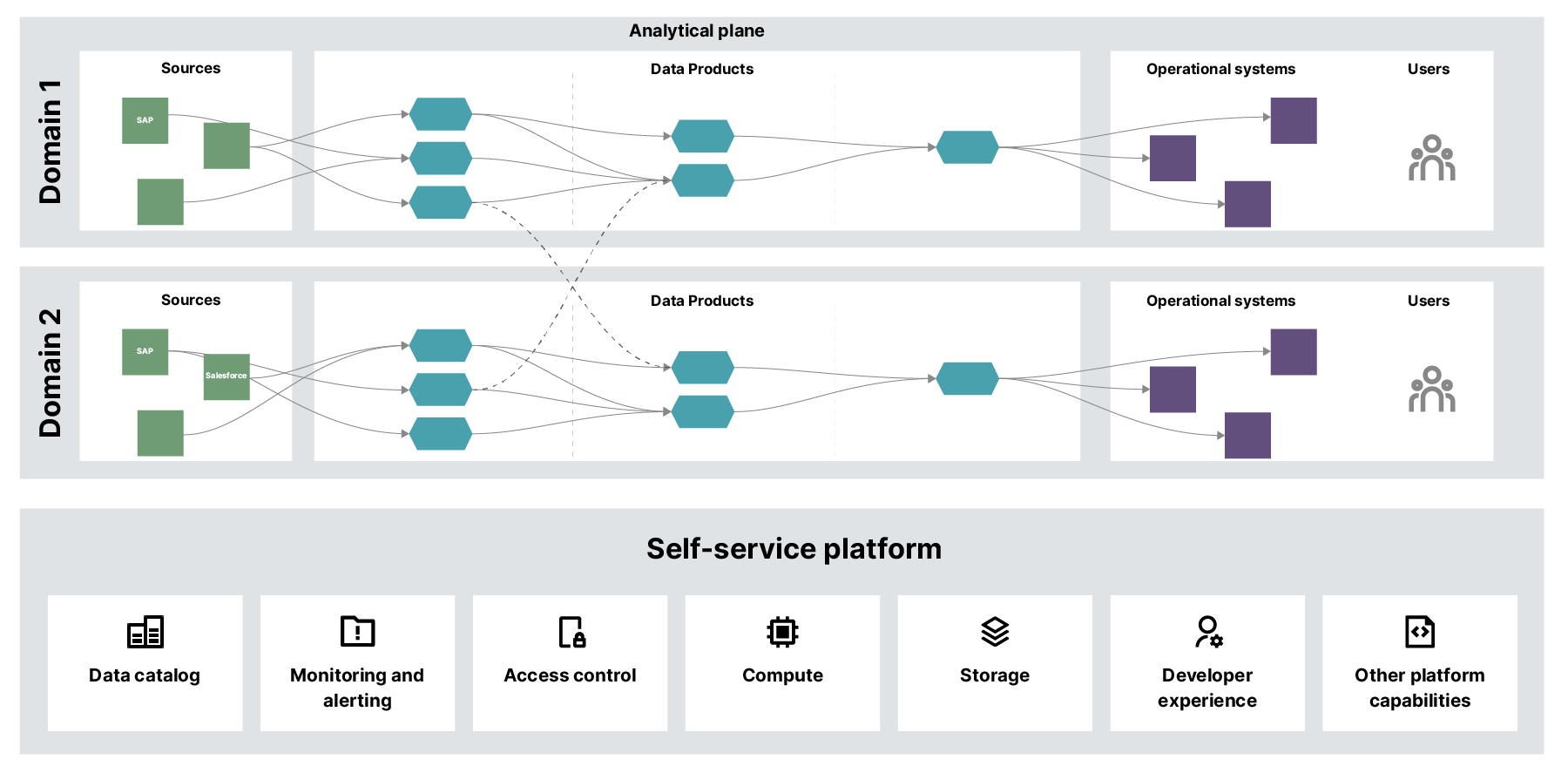
Across the technical discovery stream, we work to define those points and build up that logical architecture in greater detail.
In the technology stream of our discovery process, data engineers engage with the domain that’s being onboarded to understand their existing platform capabilities and the scope of any data products they already have in place. That helps them identify the Data Mesh delta that will need to be bridged with new technology and architecture, and what new data products should look like from a technical perspective.
Throughout the discovery process undertaken with Roche, we took steps to align the team and our planned actions with a set of architectural practices and principles that we use to help create a consistent ecosystem of interoperable data products and build a strong foundation to help the Data Mesh evolve within the organization.
Data products are the fundamental units that make up the Data Mesh. Each one has its own lifecycle, and can be deployed and maintained independently. During our engagements, we’ve created an individual git repository for every data product, containing:
Code for ingestion, transformation and publishing to output ports
Sample data, unit tests, and data quality tests
Infrastructure as code to provision data pipelines, CI/CD pipelines and other platform capabilities like storage, compute, monitoring configuration etc.
Access policies as code that specify who can access the data products and how
Each data product is an atomic and functionally cohesive unit which, in our case, exposes a single denormalized data set via one or more output ports. It may have additional intermediate tables as an implementation detail of their pipeline, but ultimately publish one data set through its output ports.
One may wonder if this rule is too stringent to be applied to all consumer-oriented data products, many of which have to read from multiple data sets to meet their objectives. However, our experience shows otherwise. If we find a need to expose multiple data sets via output ports, this is a good indication that we should create a new data product instead.
Building the mesh with data products as its architectural quantum — the smallest unit of the mesh that can be deployed independently, with high cohesion and includes all the structural elements required for its function — is what makes the Data Mesh so robust.
Any given data product can easily be replaced or removed without affecting the system as a whole. It also makes it easy to reassign ownership of the data products to a new team as required, helping the mesh scale horizontally and evolve organically.
Within the Data Mesh, the data platform has multiple planes. One common mistake that many organizations make is only focusing on the data infrastructure plane when devising and constructing a platform. But for a Data Mesh implementation to be successful, teams need to carefully assess and make the right decisions at two further levels: the data product developer experience level and the mesh supervision level.
The diagram below, taken from Zhamak’s original article shows the components that form each layer.
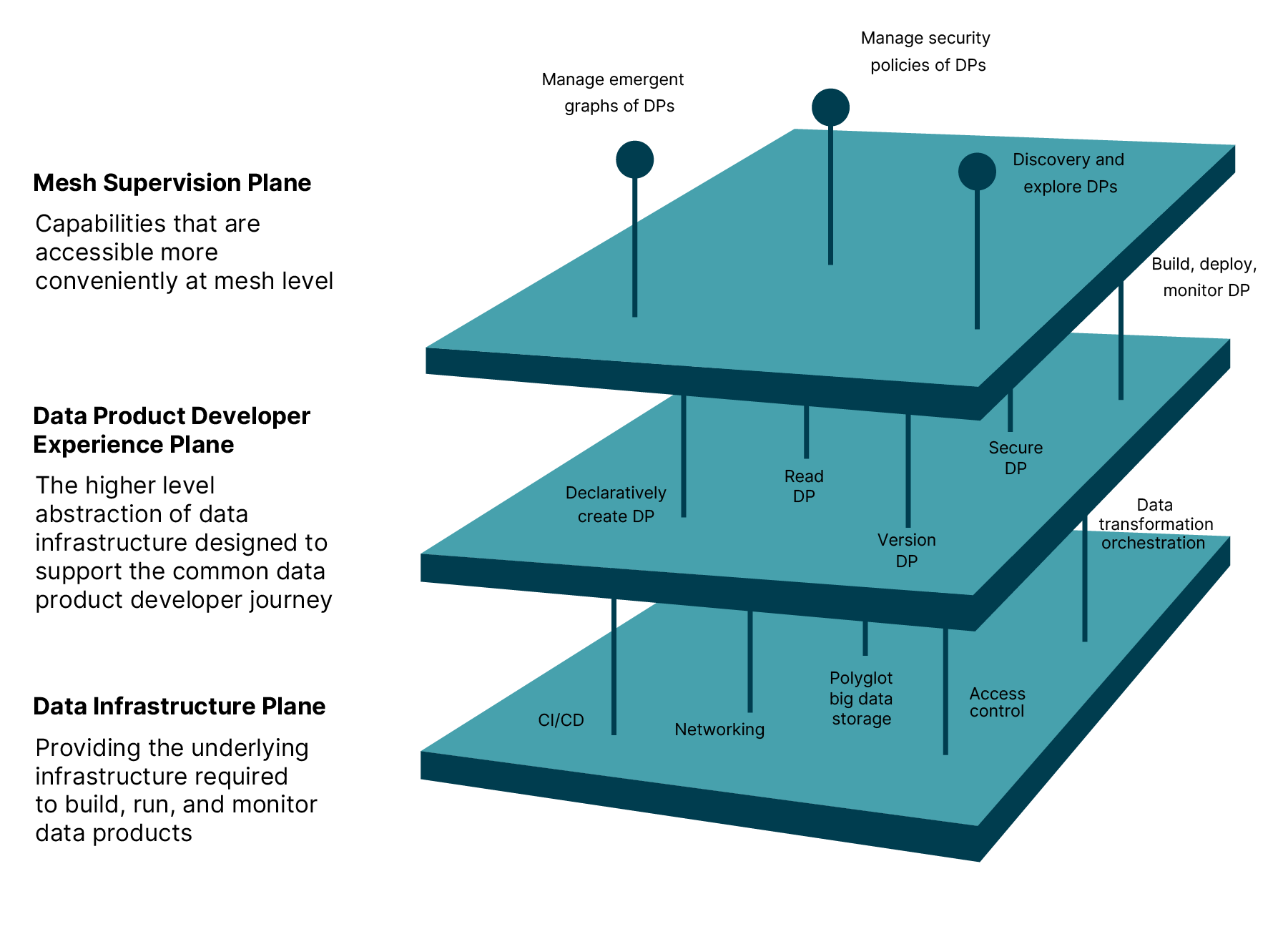
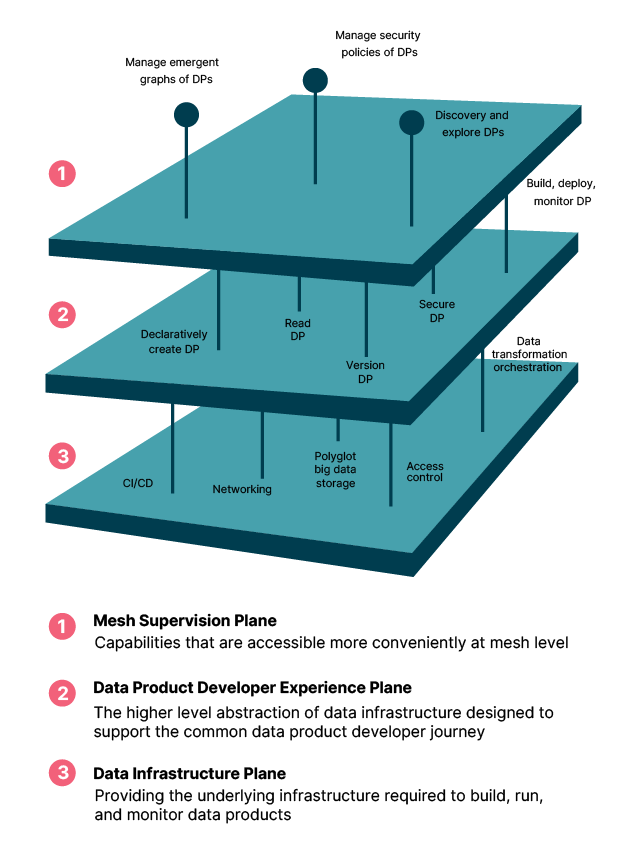
Removing friction around the creation and maintenance of data products is key to the success of Data Mesh. For the model to work, domains must be able to easily create their own data products. So, one of the top priorities when constructing platform architecture and defining how Data Mesh will be implemented is ensuring smooth and intuitive developer experiences.
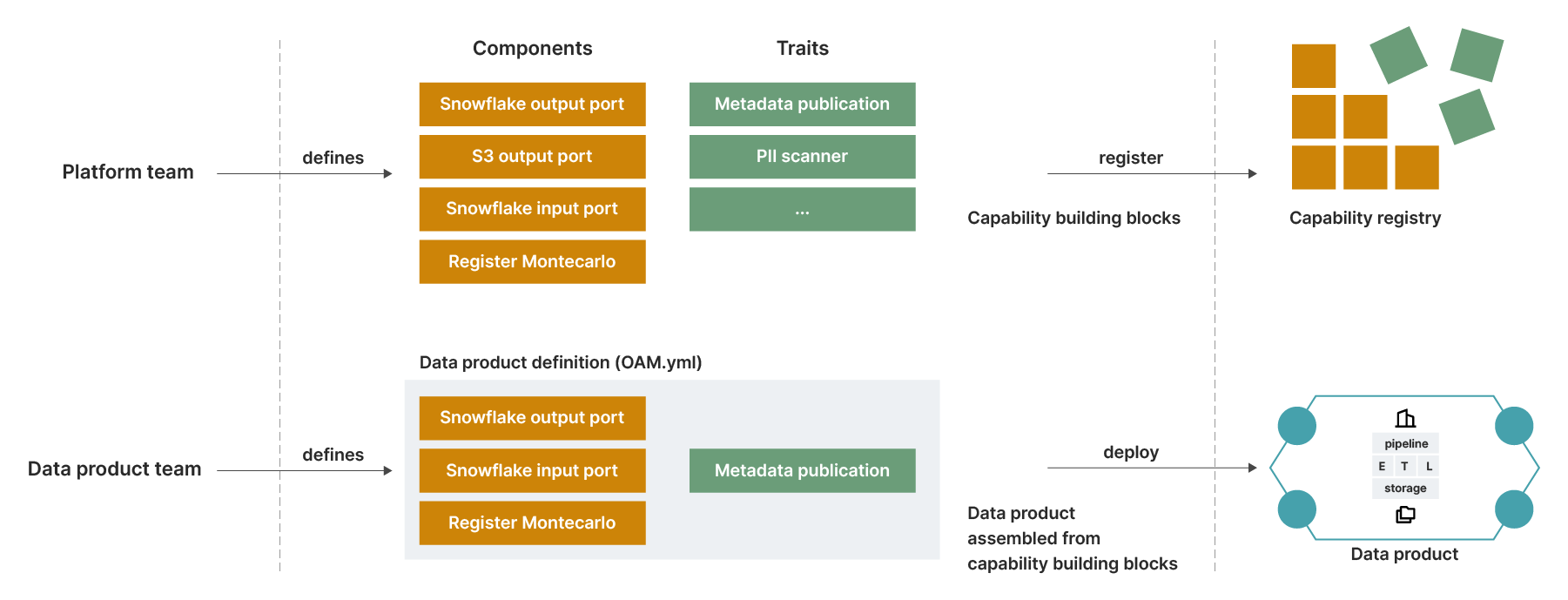
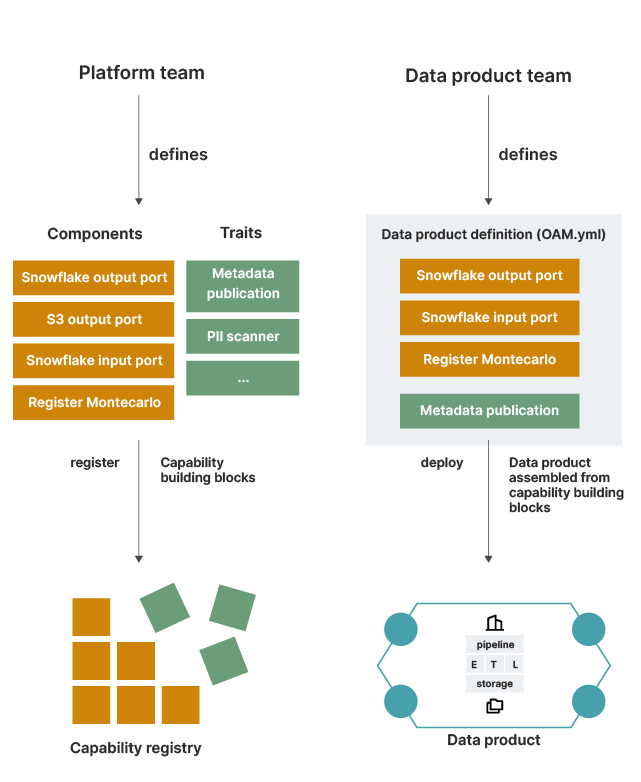
To help, we’ve:
Developed an OAM-inspired specification language that the product teams use to declaratively to specify their data products
Enabled domains to build their own products using this domain-specific language. The platform provides the framework and tools which can read the data product specification and take appropriate actions via CI/CD pipelines.
Developed and maintained a registry of capabilities to help everyone see what’s available to them
Done right, the platform cuts lead time to create new data products, empowering developers across domains to focus on creation and maintenance of data products to add business value, rather than solving the same data engineering problems again and again. It also helps to codify blueprints and patterns for implementing standard functionality, making data products more consistent and interoperable.
To ensure all data products are easily searchable and tracked so that they can be adequately maintained, we have also established a cataloging process for them. All data products are published to a common catalog (Collibra in our case) that’s accessible across the organization. We created a consistent metamodel of a data product so that it means the same thing no matter which domain they are owned by. This is key for interoperability between data products.
The metamodel enforced certain mandatory attributes for data products like
Name (unique within the data domain)
Description of the data product
Owner/ Steward (first point of contact for the data product, approver of access)
Data Sharing Agreement
“Open Access” or “Access Approval Required” (approval granted by DP owner)
Published Data Access Policy: Define who is/isn’t allowed access to the data,
Data classification (public, internal, secret etc)
Distribution rights: Whether modified (aggregated, filtered, merged) or unmodified data can be distributed to third parties by the consumer.
SLOs and SLIs
Port (a delivery mechanism for the Data Product)
Data product type (Source/Consumer oriented)
Linked to Business Domain (Business Function)
To further improve the developer experience, we developed and innersourced client libraries which could publish the data products using a REST interface that implements the above definition. The data product teams could use these platform capabilities via a declarative DSL as shown above to publish data products with minimal effort via their CI/CD pipelines.
As part of the developer experience, data product teams should be able to programmatically specify both human and machine user access policy rules. They should be able to employ both role based access control or attribute based access control techniques to achieve this.
The platform should support a data sharing workflow and automated execution of these policies with seamless integration between the corporate identity management system ( system of records for roles) and the target data storage solution to grant appropriate permissions to the schema and tables.
Several commercial tools exist which promise this functionality for a polyglot set of data storages. We are currently experimenting with a few; however, we haven’t yet found one that’s a perfect fit. There doesn’t seem to be an out of the box solution available yet — commercial or otherwise — that meets the demands of programmatic policy authoring, federated ownership and polyglot storage of data products in a Data Mesh.
Most of the commercial tools we’ve seen seem to provide programmatic access (APIs) as an afterthought. It’s an area that appears ripe for innovation, and one we’ll be focusing on in the near future. Extending Open Policy Agent, with its Rego DSL to specify policies programmatically that supports common big data storage solutions, seems like the most promising direction forward that’s in the spirit of Data Mesh.
This problem becomes a lot easier to deal with if you don’t have to deal with polyglot storage across your organization. As an example, if your organization relies solely on AWS-native services, have a look at this detailed solution architecture to find out how this can be achieved using AWS lake formation.
The supervision plane dashboard - monitors the six characteristics of the data products
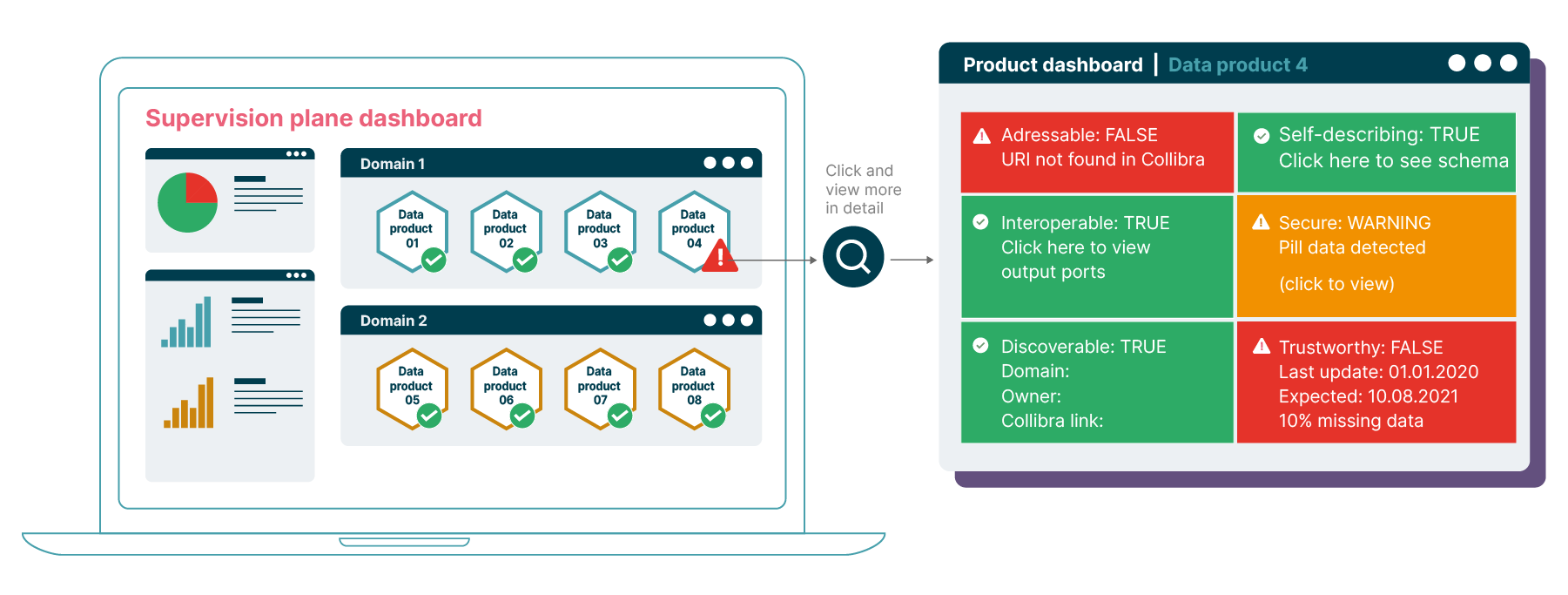
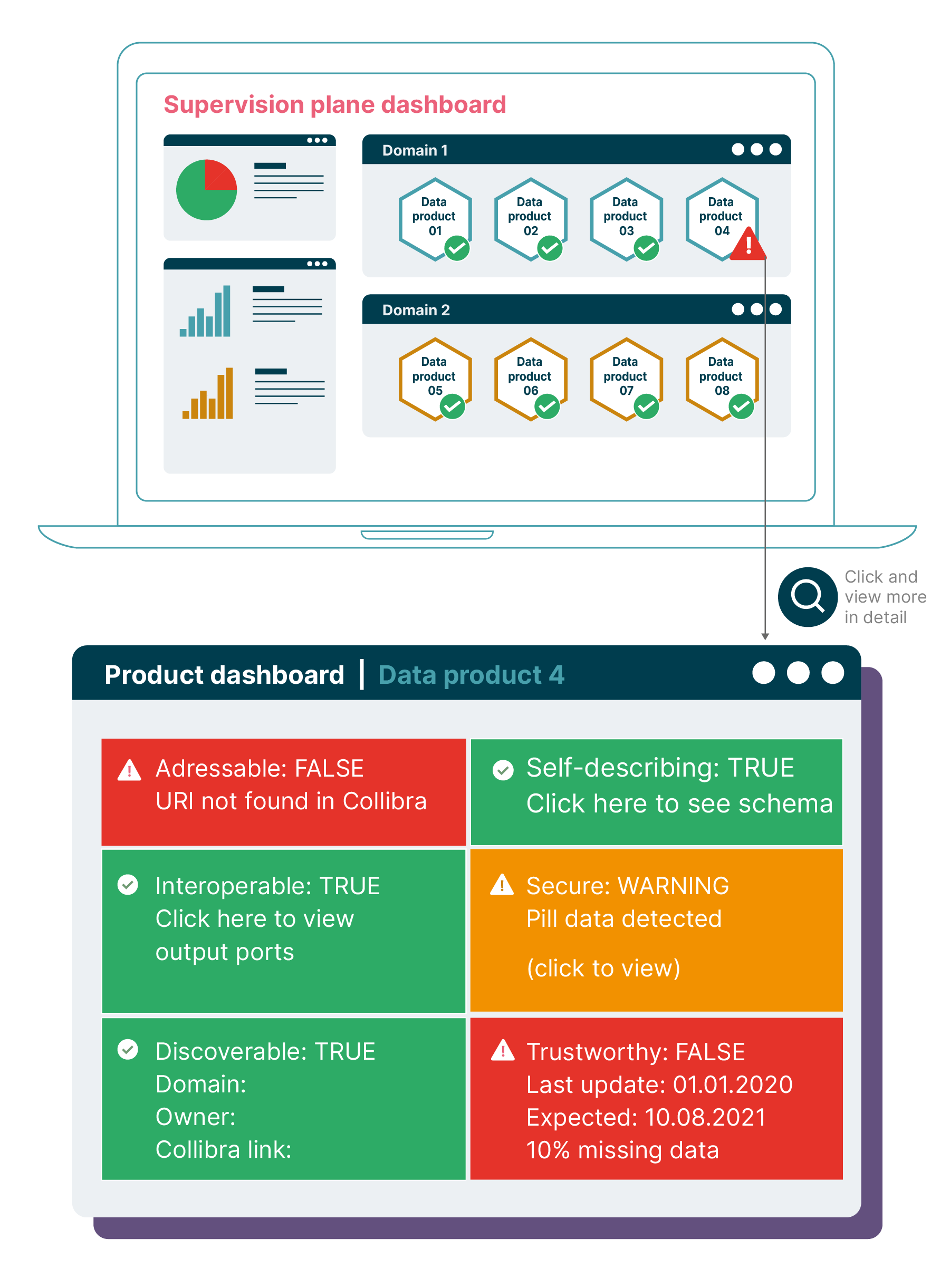
Within a Data Mesh, every team is empowered to build its own data products. But, with teams across domains all working on their own use cases, what can we do to guide the evolution of the Data Mesh, and ensure that as it grows, the products within it remain interoperable and valuable?
To help answer that question, we lean on the idea of architectural fitness functions. We define automated tests for six characteristics of a data product that could be run centrally against all data products in the data catalog. These tests ensured that the data products that were created by autonomous domain data product teams are up to the organization’s required standards:
Self-describable: Automated check for mandatory publication in the data catalog, well described semantics, product description and syntax of data, ideally accompanied with example datasets
Addressable: Check for a unique URI that represents the location of data set owned by the data product
Discoverable: Automated checks to ensure the data product is published and searchable in the catalog and the marketplace where discovery happens.
Secure: Check that access to data products is blocked by default. Checks to ensure PII has been sanitized.
Trustworthy: Check that the SLOs and SLIs are published in the catalog. Check for adherence of certain SLOs for. eg. refresh rate.
Interoperable: Automated checks to ensure that standard output ports and standard file formats are supported
These tests weren’t designed to be comprehensive, but rather a starting point for making these architectural characteristics visible and incentivizing teams to follow the required governance principles. The results of these checks were made available in an easily accessible organization-wide dashboard. This served as an important incentive for data product teams to play by the rules as no team likes to see their data products showing up as red.
The federated architecture of Data Mesh, and the polyglot storage used across it, makes enabling data sharing between teams one of the tricker and more nuanced challenges of building a high-value Data Mesh. Although data virtualization options are improving by the day, the technology isn’t quite there yet, with three significant problems persisting:
Virtual tables are leaky abstractions. In our experience, for most non trivial use cases, you still can’t get away without having to worry about source representation of the data.
They’re still generally very slow, with query performance bottlenecked to the speed of the slowest source.
They aren’t really built for programmatic usage. Workflows for creating, altering, governing the virtual tables remain heavily UI dependent, making them harder to test and enable continuous integration and continuous delivery with.
With that said, data virtualization is largely good enough for most reporting needs. However, If data locality is important to you — eg. If you're training a machine learning model over a massive data set — virtualization is not going to work.
Across our engagements, we apply the following guidance and patterns to help us define how data sharing is executed across an organization:
Data products can expose Virtual DB as an additional output port. For most simple reporting type use cases, this is sufficient and no further capabilities are needed.
For more advanced use cases, and when the producer and consumers are on similar storage platforms, always use the underlying native mechanism of the storage platform for sharing data. For example, Redshift data sharing or the native data sharing capability in snowflake.
If you need data locality and your producer and consumers are on different storage platforms, you probably can’t get away without copying over data. This is the least desirable option and should be avoided wherever possible. If you do need to do this however, consumers should exercise extra caution to ensure that governance and access control policies are preserved throughout.
Although Data Virtualization holds a lot of promise and there’s much to look forward to in this space, there is a dangerous tendency to equate data virtualization to Data Mesh. That’s at least partly due to some intense marketing from the data virtualization platforms who want to cash in while hype for Data Mesh is high.
Data virtualization is an interesting solution to a specific problem that arises in a federated architecture. The technology is still maturing, and we believe the increasing adoption of Data Mesh is going to expedite advances in this technology. However, there is still some way to go before it can be recommended as a default solution.
Around Thoughtworks, you’ll often hear Thoughtworkers saying, “Data Mesh is not all about the technology”. When the model was first gaining traction, that statement served an important purpose — it helped prevent Data Mesh being seen as just another data platform or architecture.
Today, with lots of practical implementation experience, our thinking has evolved a little. Data Mesh is about technology — but it also needs to involve a lot more. To successfully bring your vision for Data Mesh to life, you need to lead organizational change, embrace product thinking, make the right technology decisions, and ensure all three evolve in harmony.
For any Data Mesh implementation to be successful and deliver its intended value, it’s paramount that organizations begin by clearly defining their ‘Why’ and ‘What’ — the things they’re trying to achieve, and what they want to build to help achieve it. But defining those things alone isn’t enough. Teams also need to find ways to measure how effectively their efforts and hypotheses are achieving them — enabling the team to course correct on a regular basis, and experiment to find the best route towards their ‘how’.
By taking an iterative, value-based approach to the entire initiative — one that applies the EDGE operating model — teams can work back from their vision to the technology and architecture required. This approach ensures that whatever an organization’s Data Mesh and its underlying architecture end up looking like, what they deploy will deliver exactly what they want, and drive value in meaningful ways for multiple domains.
That’s the approach we take at Thoughtworks, and as we’ve explored across this article series, it’s been fundamental to our leading Data Mesh success stories.
It's a challenging undertaking, but the rewards for organizations that get it right are huge. Implemented correctly, Data Mesh has the potential to empower domains, improve data utilization, support future growth, and enable organizations to get new value from data.
If that’s something you’re interested in, and you’d like some expert help to bring your Data Mesh vision to life, talk to us today.

