















By Simon Aubury and Kunal Tiwary
Data is an integral part of every product delivery and customer engagement. When designing data systems you need to understand both data and technology, while appreciating the ultimate value a product will bring to customers. It doesn’t matter how big or small your data product is, establishing sensible defaults helps balance the trade-offs of particular technology decisions.
Assessing best practices around data management is a good starting point that can guide your data design choices. As data engineers, you should select technology tools that work well together for a project and are suitable for the broader needs of data across the organization. At its core, every technology decision needs to be driven by the value it will provide to the business.
In this chapter, we cover the baseline principles to get you started and some considerations for balancing the trade-offs of technology.
Default principles
Given today’s complex data and technological landscape, the notion that there can be a single best way of doing anything seems ambitious. But sensible default practices are a great starting point because they’re an effective way of building architecture on shared values. They also allow you to be technology agnostic, while focusing on the elements of good design. And for data projects, they can provide an initial set of baseline principles: effective practices and techniques to get you started.
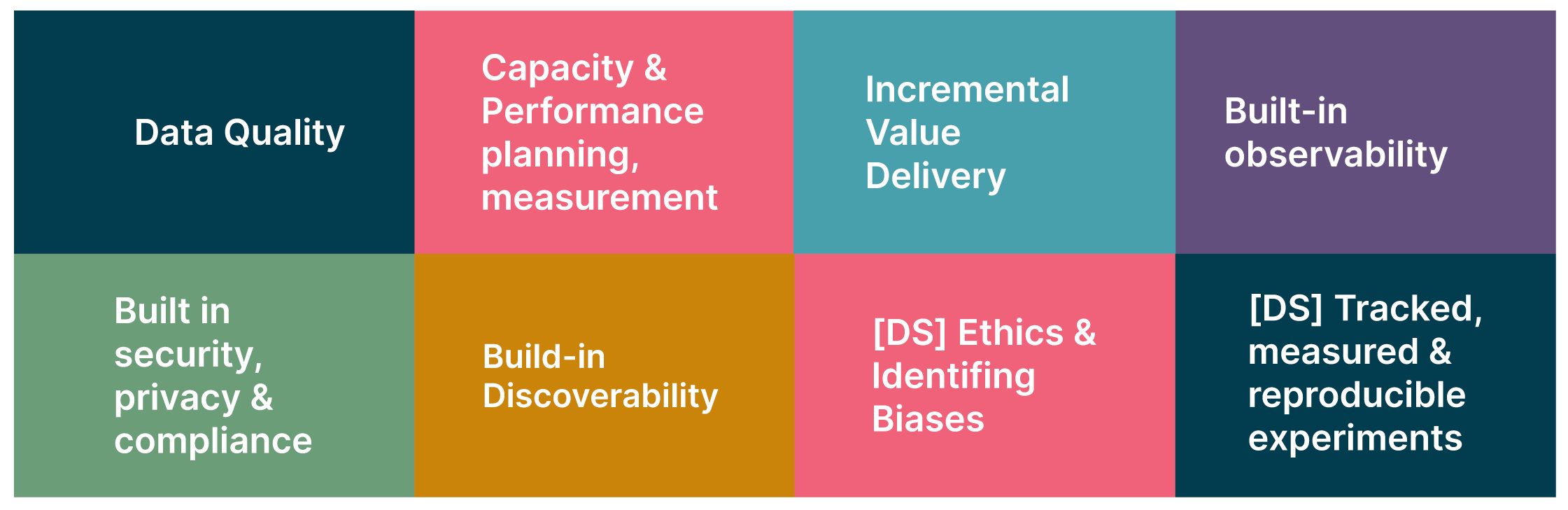
Figure 1: Data default practices (In addition to core engineering sensible defaults)
As with software projects, we believe it’s essential to establish best practices around data management for modern data platforms, including:
Capacity and performance planning and measurement
Incremental value delivery
Observability
Security and compliance
Discoverability
Ethics and bias
Tracked measured and reproducible experiments
Measuring architectural fitness
However, there may be circumstances which make the default choice invalid — or at least suboptimal. For example, if your product differentiation requires ultra low latency reads at the expense of consistency, you will need to use a specialized niche data store for your use case.
Measuring architectural fitness
Data architecture needs to grow and evolve with the needs of the organization. Evolutionary architecture is an approach that enables architecture to change incrementally – allowing your business to respond to new demands quickly. To make sure change doesn’t compromise quality or cause architectural issues, measure how the architecture meets the original use case over time. Fitness functions provide an objective measure, informing the development process as it happens, rather than after the fact.
Some fitness functions for data architecture to consider include:
Cost
Data latency
Data volume
Putting use cases before technology
There’s often a fixation on labelling a data problem as being a transactional or analytical workload, or a use-case as being a real-time or batch system. This often leads to characterizing a business problem as “suitable” for a technology. However, technology is there to support the business, not the other way around. Take data processing as an example.
Business processes are akin to a flow of events – and virtually all data you deal with is streaming in this flow. Data is almost always produced and updated continually at its source, and it is constantly arriving. Waiting until the end of the day to process data in a batch is a bit like buying a newspaper to find out what happened in the world yesterday. While for some use cases, such as billing and payroll systems, this is acceptable, others require more immediate streaming data processing.
When designing appropriate architecture, focus on developing solutions that process data to meet the business outcome you’re working towards. You need to step back and appreciate what the architecture is there to support. Are you building a system to facilitate “transactions” (think sales on an ecommerce website, or a payment processing system)? Or are you trying to “analyze” history to identify trends and use aggregated data to draw insights? Start with the problem you are trying to solve. Then look at the characteristics of the relevant business data, and consider how technology and project architecture might be able to better support those workloads.
While it’s crucial to use the right data store for the right use case, you want to solve the problem, not build to the constraints of the technology. The wrong technology choices can misdirect engineering effort and undermine the likelihood of future business success.
Balancing the trade-offs of technology
Technology changes fast; this is especially true for data systems. The technology you select needs to meet the increasing demands and expectations for data platforms, address a wide range of needs – from transactional and operational to analytical – and enable interactive data exploration in real time.
But finding the right technology can be time consuming. To speed up the process, Amazon founder, Jeff Bezos suggests you don’t deliberate over easily reversible, “two-way door” decisions. Simply walk through the door and see if you like it — if you don’t, go back. You can make these decisions fast and even automate them.
Few, if any, data decisions are hard to reverse. But those that are need to be made carefully. A data technology radar is a great way to balance risk in your technology portfolio and pollinate innovation across teams, experimenting accordingly. It allows you to work out what kind of technology organization you want to be – and objectively assess the data tools that are working and those that are not.
It’s also important to only invest in and use custom-built solutions where it is a differentiator to the business or provides a competitive advantage. Consider what’s important to your business:
Security, schemas, design and lineage – the non-negotiables for system design
An upfront tiring of latency, correctness and durability – deciding the ranking is still important
Batch, harmonise and consolidate delivery – because costs ebb and flow
Moving fast may lead to duplication, while consolidating effort on a centralized data platform will eliminate duplication but take longer. You need to understand the trade-offs and make data architecture decisions at the enterprise level quickly. Slow decisions can cause your data infrastructure to unnecessarily proliferate which can be difficult to reverse if you want to consolidate your infrastructure.
Optimizing for sensible data defaults can make it easier to select the right technology and make good architecture choices. It can also help you validate whether your investment is providing the business with the competitive advantage you expect it to – helping you make more informed decisions.
In the next chapter, we’ll share how you can implement an effective data strategy that provides the foundations for managing data quality.