














AI and ML
ChatGPT: A useful tool buried beneath the hype

Picture a corporate conference room with an executive leadership team gathered around the board table — some in person, some on screen. Amidst the usual chatter, there’s an agenda item mysteriously titled “ChatGPT”.
Taking the lead, the CEO notes that key competitors have once again got the jump on them with press releases proclaiming their adoption of the new artificial intelligence-based chatbot for customer service, software development, marketing, legal advice and sales — with the implication being that they’re making substantive cost savings. Market analysts have greeted this news well by upgrading their stocks across the board.
The CTO plugs her laptop into the screen and begins her presentation with Mitch Ratcliffe’s famous quote from Technology Review in 1992: “A computer lets you make more mistakes faster than any other invention with the possible exceptions of handguns and Tequila.”
There are several puzzled and disappointed faces around the boardroom table…
___
OpenAI’s ChatGPT has received significant attention since its launch in November 2022. The response has been varied. Many people have been amazed by its ability to rapidly complete time-consuming tasks like crafting professional prose, academic essays and even product strategies. On the other hand, as interest groups and professionals collectively stress-tested ChatGPT, its limitations became clear. From producing middle-of-the-road positions, making stuff up, writing code that has a high rate of being incorrect, and even producing unethical content, for every enthusiastic tale of ChatGPT’s capabilities, there are just as many that emphasize a need for restraint and caution.
In this two-part series, we draw on Thoughtworks’ experience in delivering AI systems to demystify the technology behind ChatGPT. We’ll cover its possible applications, its limitations and corollary implications for organizations that are thinking of building business capabilities around generative language models. But first, let’s take a closer look at how it actually works.
ChatGPT is a type of large language model (LLM for short, or sometimes referred to as generative language model). Before discussing the strengths and limitations of LLMs, it helps to briefly describe how they work.
Much of the razzle-dazzle of LLMs boils down to next “token” (i.e. word) prediction. LLMs are trained on large amounts of text data (what’s commonly called a “corpus”). Through this training process, the model builds up an internal numerical representation of words or “embeddings” so it can predict the next most probable word for any given word or phrase.
For example, if we give a trained language model a prompt, “Mary had a”, and ask it to complete the sentence, we are essentially asking it: what words are most likely to follow the sequence, “Mary had a…”? Anyone with even the slightest familiarity with nursery rhymes will know that the answer is “little lamb”.
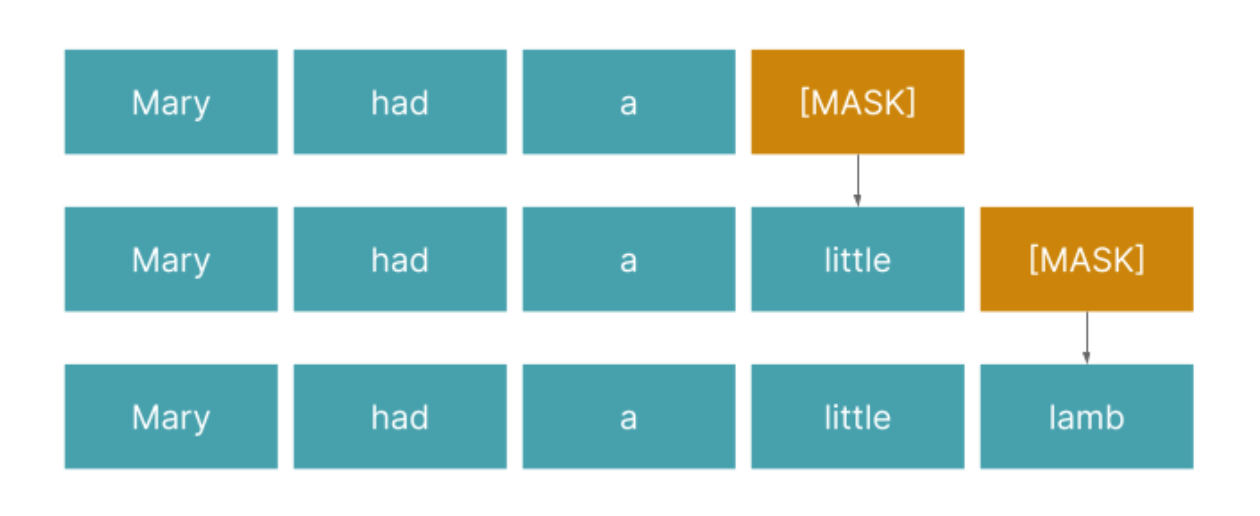
Figure 1: LLMs are able to generate sentences and whole essays through its ability to predict the next highest-probability candidate word for any given word or phrase. It learns to do so through techniques such as masked language modeling.
ChatGPT is different from earlier LLMs (e.g. GPT-2) in that it introduced an additional mechanism – Reinforcement Learning from Human Feedback (RLHF). This means human annotators further train the LLM to mitigate the biases present in its training data.
ChatGPT’s uncanny text generation abilities have no doubt sparked the imagination of many: how can I leverage or recreate a tool like ChatGPT for creating value in my business?However, the recent missteps of Google Bard and Microsoft’s ChatGPT-powered Bing highlights the limitations of LLMs; these need to be properly understood in order to set expectations and avoid disappointment when we invest money and time in generative AI projects. With that in mind, let’s look at three key limitations of LLMs.
1. They are sophisticated but probabilistic auto-complete machines
LLMs are essentially an “auto-complete” machine that operates using sophisticated pattern recognition methods. It parrots and reconstructs prose that it has been trained on, but it does so probabilistically; that’s why it will often make mistakes and even invent “facts” or produce made-up references. These so-called “hallucinations” are not an aberration — it’s a behavior that’s inherent to any generative system.
As our colleague David Johnston explained on LinkedIn, it cannot, and should not be expected to, complete tasks that require logical reasoning. Would you use a tool that can’t do math to provide financial advice?
2. Their text generation abilities are unsuitable in contexts with low fault tolerance
The corollary of the first limitation is that LLMs’ text generation capabilities are less suitable for tasks with low “fault tolerance.” For example, legal writing and tax advice have low fault tolerance and are highly specific use cases that warrant expertise, accountability and trust – not just words on pages. Furthermore, such scenarios typically warrant factually accurate, not probabilistically composed, prose.
On the other hand, tasks such as creative writing may in some cases have high fault tolerance, and the high variance of LLMs may actually be a feature rather than a bug in that it can help generate creative and valuable options that humans hadn’t considered before. Even then, human moderation is absolutely necessary to avoid exposing your customers to uninhibited and potentially hallucinatory chatbot responses.
Having said that, LLMs have other useful capabilities beyond the free-form, prompt-based text generation capability that ChatGPT is known for. These include classification, sentiment analysis, summarization, question-answering, translation, among others. Since 2018, LLMs such as BERT and GPT-2 could already achieve state-of-the-art results on these Natural Language Processing (NLP) tasks. These capabilities are narrower, more testable, and can be applied to solve business problems such as knowledge management, document classification, and customer support to name just a few.
3. Data security and privacy risks
There are likely to be legal and regulatory constraints on the movement and storage of your organization’s and your customer’s data. The widespread use of ChatGPT among knowledge workers introduces a serious risk of exposing confidential data to a third-party system. This data will be used to train future releases of OpenAI models which means it could potentially be regurgitated to the public.
ChatGPT’s limitations doesn’t mean that we should write off the potential of generative AI in solving important problems. However, by being aware of these limitations we can ensure we have realistic expectations about what it can actually deliver. Here are some high-level guidelines when considering using generative language models to solve business problems:
Start with business use cases with a high fault tolerance
Fine-tune pre-trained LLMs on domain-specific data (what’s also known as transfer learning). Do this using a secure cloud infrastructure or approved PaaS or MLaaS technologies with the necessary data security and privacy controls to create models that are relevant to your business domain
Ensure that LLMs are always monitored by a human who can verify and moderate its content (even though it seems not everyone will remember to do that)
Even with those guidelines in mind, it’s important to remember that training high-quality generative language models is costly and challenging in terms of compute, testing, deployment and governance. For that reason we should be careful not to fall into the trap of a tech-first approach — we have a shiny hammer, what can we hit with it? Instead, organizations need to zoom out and (i) start with finding a high-value problem worth solving, and (ii) find safe, lightweight, cost-effective ways to solve them iteratively.
In our experience, the delivery of AI solutions must be undergirded by foundational practices in agile engineering, Lean delivery and product thinking, in order to deliver value rapidly, reliably and responsibly. Without those elements in place, organizations are likely to get trapped in tedious AI development and delivery risks, or even releasing products that users didn’t want or need. The result is frustration, disappointment and botched investments.
We’ll explore that in part two of this blog, where we share five recommendations that we’ve distilled from our experience delivering AI solutions at industry-leading clients.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

