














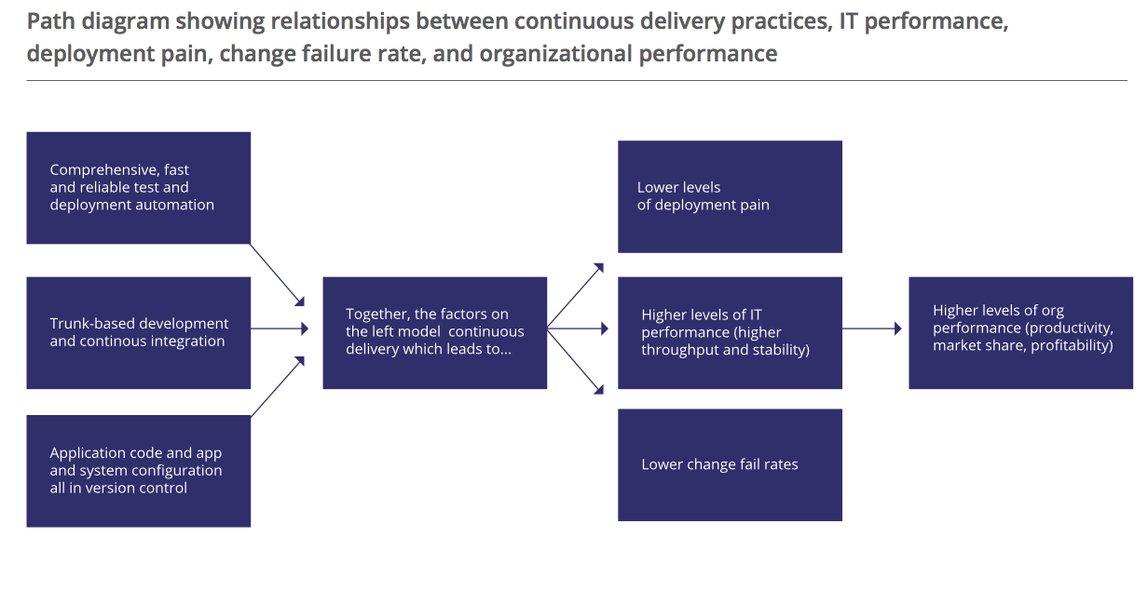
Puppet Labs’ recently published State of DevOps report talks about how Continuous Delivery (CD) practices affect team performance, and specifically calls out trunk-based development as a leading indicator of high performance.
(Image below via Puppet Labs’ report)


The Continuous Delivery book also highlights the importance of it in chapter 14 where it implies that trunk- (or mainline-) based development is actually a necessary condition for practicing Continuous Integration:
Before we talk about TBD, let us look at some of the anti-patterns with branch-based workflows.
Of course, advanced CI features like automatic branch tracking can help to some extent by automatically picking up new branches and running builds.
Snap even goes further and runs a build if it is able to merge successfully with the master and this tells you whether the branch can be safely integrated to the master branch.

This can be very useful feature for short-lived branches where you perhaps want to get your code reviewed by others before merging to the master or you are doing an experimental change and want to get feedback from CI.
But working on long-lived branches adds significant risk that cannot be fixed with tooling:
Firstly, the change-set in long-lived branches tends to be large. If someone else pushes a big change then it is going to be extremely difficult and risky to merge the code. We have all seen this at some point where we had to painstakingly merge lot of conflicts.
Secondly, this pain creates a tendency to hold back on refactoring on feature branches. Developers become wary of moving code between classes or even renaming methods because of the looming fear of having to resolve merge conflicts. Inevitably, this leads to piling up of technical debt.
Thirdly, working out of long lived branches does not give a chance for other developers on the team to pick up your changes quickly enough. This affects code reuse and can also result in duplicated efforts. For example, multiple developers upgrading to a new version of a library they need. Also, there is likely no visibility on changes happening in feature branches which eliminates any feedback loop from other developers in the project until the work is pushed to master, by which time it is too late to make changes to the design.
Fourthly, notice that the feedback loop with integration pipelines is long. If you have merge conflicts leading up-to master or test failures, it can be slow and painful to resolve.
Finally, feature branches promote the tendency of big bang feature releases — “Let me add one more thing before I merge to master” — which means not only delayed integration but also delay in delivering customer value and receiving early feedback. Also, the large change-set makes it difficult to troubleshoot issues or even rollback changes in Production if things go wrong.
In short, working out of long-lived branches adds risks and friction to the process of software delivery.
Apart from inheriting the problems associated with long lived feature branches, this workflow gives a false sense of security that the mainline or Production branch is pristine whereas if you look closely, it in fact introduces many new unknowns and risks.
For instance, even if you test your code exhaustively in a staging or a QA environment, there is no guarantee that the same revision is what is deployed to production. Because other changes can be made directly on any of the branches (e.g. Hot fixes for Production!) it means that what you verified on QA is not valid anymore. Merge conflicts while promoting to any of the upstream branches further reduce confidence.
In addition, because you rebuild the artifacts for every branch, there is even more risk because even small environment configuration changes can lead to differences in the binaries. For e.g. a package update or compiler version difference is enough to make the binary different from what was built previously.
The build promotion process with branch based workflow also doesn’t give enough visibility into what gets deployed and feels extremely complicated. Modeling the workflow for different scenarios like hot fixes required on Production, rollbacks etc. is extremely tricky.
Unfortunately, this anti-pattern is encouraged by many CI tools that do not provide a true deployment pipeline which we will talk about shortly.
The practice of checking in often means that merge conflicts if any are small and there is no reason to hold back on refactoring. Troubleshooting test failures or defects becomes easier when the change-set is small.
TBD also implies deploying code from the mainline to production – which means that your mainline must always be in a state that it can be released to production.
But don’t worry. Even the browser that you are most likely reading this on, was built using this practice.
While it is true that TBD expects a certain discipline from the developer, with the right practices, it can dramatically make your software development and deployment process much more reliable and lightweight.
The Continuous Delivery book mentions several best practices (below) to adopt TBD around the principle of keeping the mainline version releasable at all times:
Small, incremental changes over big bang changes
Frequent small changes are less risky, easier to integrate with and easier to rollback. Use branch by abstraction(not to be confused with version control branching!) to make even large-scale changes incrementally.
Hide unfinished functionality with feature toggles
Hide features that aren’t finished yet from users. Feature toggles are an effective way to hide new features before you are confident about releasing them to users.
Comprehensive automated tests to give confidence
With a comprehensive automated test suite designed to give fast feedback, you have high confidence about the changes you are making. If you are always checking in small incremental changes, test failures are easy to fix.
Continuous Delivery tools that implement the Deployment pipeline as first class concept can enable highly effective workflows with Trunk-based development.
A deployment pipeline modeled in Snap CI:

The pipeline status page in Snap CI:

You can see the list of commits and each commit has triggered a series of stages that lead all the way to Production. With each passing stage, you get higher confidence with that revision of the code. If something fails, the pipeline stops and you have to fix the build OR revert the commit that caused the failure. (Yes, this is inspired from Lean principles). Thus, the deployment pipeline thus affords a high degree of visibility into the build and the deployment process.
The pipeline can have any number of custom stages — including manually triggered stages — to deploy to intermediate environments like a QA or a Pre-Production (staging) environment. This way, a QA (for example) can decide to manually promote a revision to a QA environment and after verification, promote it to a production or staging environment as is the process.
This eliminates the need to have a branch per environment and enables a highly visualized and reliable workflow with trunk-based development.
Also, because there is no friction that comes with intermediate branches, this workflow promotes the practice of pushing small incremental changes that the customer benefits from continuously – which is the whole point.
There are cases, of course, where directly checking in to trunk might not be suitable. For example, if you are developing an open source project you might not be willing to give access to third-party developers to commit to your mainline. Or if in an organization, you don’t want to give other teams the access to directly make changes without going through review by the core team. In such cases, Pull Requests and Integration pipelines can be suitable options and can be used in conjunction with TBD.
This article was originally published on Snap CI's The Pipeline blog.
Thanks to Zabil C. M. and Marco Valtas for reviewing and suggesting improvements to this article.
(Image below via Puppet Labs’ report)
The Continuous Delivery book also highlights the importance of it in chapter 14 where it implies that trunk- (or mainline-) based development is actually a necessary condition for practicing Continuous Integration:
(Mainline development) is an extremely effective way of developing, and the only one which enables you to perform continuous integration.
At Snap, we practice trunk-based development (TBD) to develop our hosted CI product and so do most consulting projects at Thoughtworks where we work.Before we talk about TBD, let us look at some of the anti-patterns with branch-based workflows.
Common anti-patterns with branch based workflows
Anti-pattern #1 - Long-lived feature branches
The core principle of Continuous Integration is that of integrating code frequently. So, if you are doing development on long-lived feature branches then you are no longer integrating code with everybody else frequently enough. This means delayed feedback, big bang merges that can be risky and time consuming to resolve, reduced visibility and reduced confidence.Of course, advanced CI features like automatic branch tracking can help to some extent by automatically picking up new branches and running builds.
Snap even goes further and runs a build if it is able to merge successfully with the master and this tells you whether the branch can be safely integrated to the master branch.

This can be very useful feature for short-lived branches where you perhaps want to get your code reviewed by others before merging to the master or you are doing an experimental change and want to get feedback from CI.
But working on long-lived branches adds significant risk that cannot be fixed with tooling:
Firstly, the change-set in long-lived branches tends to be large. If someone else pushes a big change then it is going to be extremely difficult and risky to merge the code. We have all seen this at some point where we had to painstakingly merge lot of conflicts.
Secondly, this pain creates a tendency to hold back on refactoring on feature branches. Developers become wary of moving code between classes or even renaming methods because of the looming fear of having to resolve merge conflicts. Inevitably, this leads to piling up of technical debt.
Thirdly, working out of long lived branches does not give a chance for other developers on the team to pick up your changes quickly enough. This affects code reuse and can also result in duplicated efforts. For example, multiple developers upgrading to a new version of a library they need. Also, there is likely no visibility on changes happening in feature branches which eliminates any feedback loop from other developers in the project until the work is pushed to master, by which time it is too late to make changes to the design.
Fourthly, notice that the feedback loop with integration pipelines is long. If you have merge conflicts leading up-to master or test failures, it can be slow and painful to resolve.
Finally, feature branches promote the tendency of big bang feature releases — “Let me add one more thing before I merge to master” — which means not only delayed integration but also delay in delivering customer value and receiving early feedback. Also, the large change-set makes it difficult to troubleshoot issues or even rollback changes in Production if things go wrong.
In short, working out of long-lived branches adds risks and friction to the process of software delivery.
Anti-pattern #2 - Branch per environment
One of other most common anti-patterns is to have supporting branches like Dev, QA, Staging and Production in addition to features branches. Developers work out of feature branches and merge to Dev branch when they are ready, and merge to upstream branches all the way to the Production branch. Each branch would then be configured on the CI server to run builds and deploy to a specific environment on which the feature is validated.Apart from inheriting the problems associated with long lived feature branches, this workflow gives a false sense of security that the mainline or Production branch is pristine whereas if you look closely, it in fact introduces many new unknowns and risks.
For instance, even if you test your code exhaustively in a staging or a QA environment, there is no guarantee that the same revision is what is deployed to production. Because other changes can be made directly on any of the branches (e.g. Hot fixes for Production!) it means that what you verified on QA is not valid anymore. Merge conflicts while promoting to any of the upstream branches further reduce confidence.
In addition, because you rebuild the artifacts for every branch, there is even more risk because even small environment configuration changes can lead to differences in the binaries. For e.g. a package update or compiler version difference is enough to make the binary different from what was built previously.
The build promotion process with branch based workflow also doesn’t give enough visibility into what gets deployed and feels extremely complicated. Modeling the workflow for different scenarios like hot fixes required on Production, rollbacks etc. is extremely tricky.
Unfortunately, this anti-pattern is encouraged by many CI tools that do not provide a true deployment pipeline which we will talk about shortly.
How trunk-based development helps
In trunk-based development (TBD), developers always check into one branch, typically the master branch also called the “mainline” or “trunk”. You almost never create long-lived branches and as developer, check in as frequently as possible to the master — at least few times a day.Every developer is touching mainline, so all features grow in the mainline… which acts as a communication point. With CI, the mainline must always be healthy, so in theory (and often in practice) you can safely release after any commit.
With everyone working out of the same branch, TBD increases visibility into what everyone is doing, increases collaboration and reduces duplicate effort.The practice of checking in often means that merge conflicts if any are small and there is no reason to hold back on refactoring. Troubleshooting test failures or defects becomes easier when the change-set is small.
TBD also implies deploying code from the mainline to production – which means that your mainline must always be in a state that it can be released to production.
But, isn’t it too risky to develop on the mainline?
This sounds like a scary idea and many people initially balk at the idea of checking in directly to the mainline in favor of using branches which in comparison feel safe and cozy.But don’t worry. Even the browser that you are most likely reading this on, was built using this practice.
While it is true that TBD expects a certain discipline from the developer, with the right practices, it can dramatically make your software development and deployment process much more reliable and lightweight.
The Continuous Delivery book mentions several best practices (below) to adopt TBD around the principle of keeping the mainline version releasable at all times:
Small, incremental changes over big bang changes
Frequent small changes are less risky, easier to integrate with and easier to rollback. Use branch by abstraction(not to be confused with version control branching!) to make even large-scale changes incrementally.
Hide unfinished functionality with feature toggles
Hide features that aren’t finished yet from users. Feature toggles are an effective way to hide new features before you are confident about releasing them to users.
Comprehensive automated tests to give confidence
With a comprehensive automated test suite designed to give fast feedback, you have high confidence about the changes you are making. If you are always checking in small incremental changes, test failures are easy to fix.
The deployment pipeline and trunk-based development
The deployment pipeline enables a trunk-based CD workflow. By modeling your application delivery as a pipeline of stages from the trunk all the way to Production, you get the visibility and reliability required to deploy continuously to Production.The deployment pipeline represents the path to production
The deployment pipeline is nothing but a concept that models your build and deployment workflow as a path to production. You model the pipeline as a series of stages. Each stage can be configured to run automatically based on the success of the previous stage OR with a manual trigger. Artifacts built in one stage can be consumed in subsequent stages – giving you the confidence that the same artifact that was tested is what is being deployed.Continuous Delivery tools that implement the Deployment pipeline as first class concept can enable highly effective workflows with Trunk-based development.
A deployment pipeline modeled in Snap CI:

The pipeline status page in Snap CI:

You can see the list of commits and each commit has triggered a series of stages that lead all the way to Production. With each passing stage, you get higher confidence with that revision of the code. If something fails, the pipeline stops and you have to fix the build OR revert the commit that caused the failure. (Yes, this is inspired from Lean principles). Thus, the deployment pipeline thus affords a high degree of visibility into the build and the deployment process.
The pipeline can have any number of custom stages — including manually triggered stages — to deploy to intermediate environments like a QA or a Pre-Production (staging) environment. This way, a QA (for example) can decide to manually promote a revision to a QA environment and after verification, promote it to a production or staging environment as is the process.
This eliminates the need to have a branch per environment and enables a highly visualized and reliable workflow with trunk-based development.
Also, because there is no friction that comes with intermediate branches, this workflow promotes the practice of pushing small incremental changes that the customer benefits from continuously – which is the whole point.
There are cases, of course, where directly checking in to trunk might not be suitable. For example, if you are developing an open source project you might not be willing to give access to third-party developers to commit to your mainline. Or if in an organization, you don’t want to give other teams the access to directly make changes without going through review by the core team. In such cases, Pull Requests and Integration pipelines can be suitable options and can be used in conjunction with TBD.
This article was originally published on Snap CI's The Pipeline blog.
Thanks to Zabil C. M. and Marco Valtas for reviewing and suggesting improvements to this article.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.