














Our friends at SoundCloud embarked on a journey a few years ago that changed their system and moved it from a monolithic Rails application towards an ecosystem of microservices. One thing that worked particularly well for them during that project is the BFF pattern, Backends for Frontends. Their BFF usage and the success story behind it may help other teams; so we decided to write it up. We hope you find it useful.
Motivation
Early on, SoundCloud was one monolithic system, exposing an API serving the web client, Android and iOS apps as well as the Internet, a bunch of different mashups, partners, etc. This shared API grew with every feature and was also a common denominator between all the platforms and API consumers.

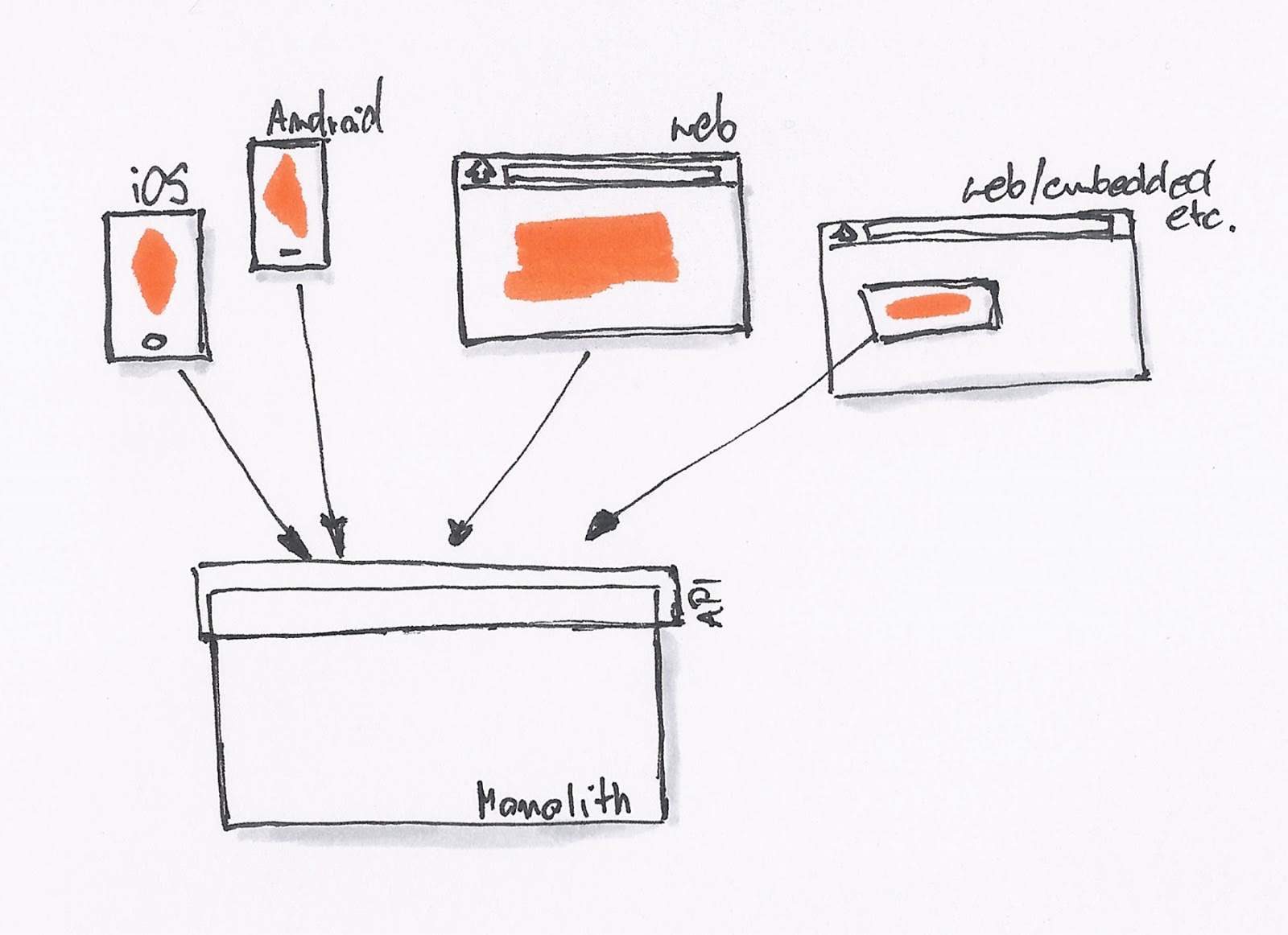
After a while, it started to get problematic, both in regards to the time needed for adding new features, and also due to the different needs of the platforms. For a mobile API, it's sensible to have a smaller payload footprint and request frequency than a web API, for example. The existing monolith API didn't take this into consideration and was developed by another team, unaware of the mobile needs. So every time the apps needed a new endpoint, first the frontend team needed to convince the backend team that this was truly the case, then a story needed to be written, prioritized, picked, developed and communicated to the frontend team.
You can see the problem here: unnecessary friction, communication overhead, delay. At the same time, the backend team started to have issues with the monolithic application, as adding new features became harder, whilst fire-fighting got more prominent.
Solution
To tackle these issues, SoundCloud decided that whenever implementing a feature needed a specific, fine-tuned API, the team driving this is also able to implement the API endpoint and therefore decides where to get the data from and how to aggregate it, what payload needs to be transmitted etc. This API endpoint is to be created outside of the monolithic app and acts as a feature specific facade. The frontend team is the owner of this new layer.
The BFF was born and could be fine-tuned to the needs of the specific platform and feature (Android, iOS clients, web API and other consumers).

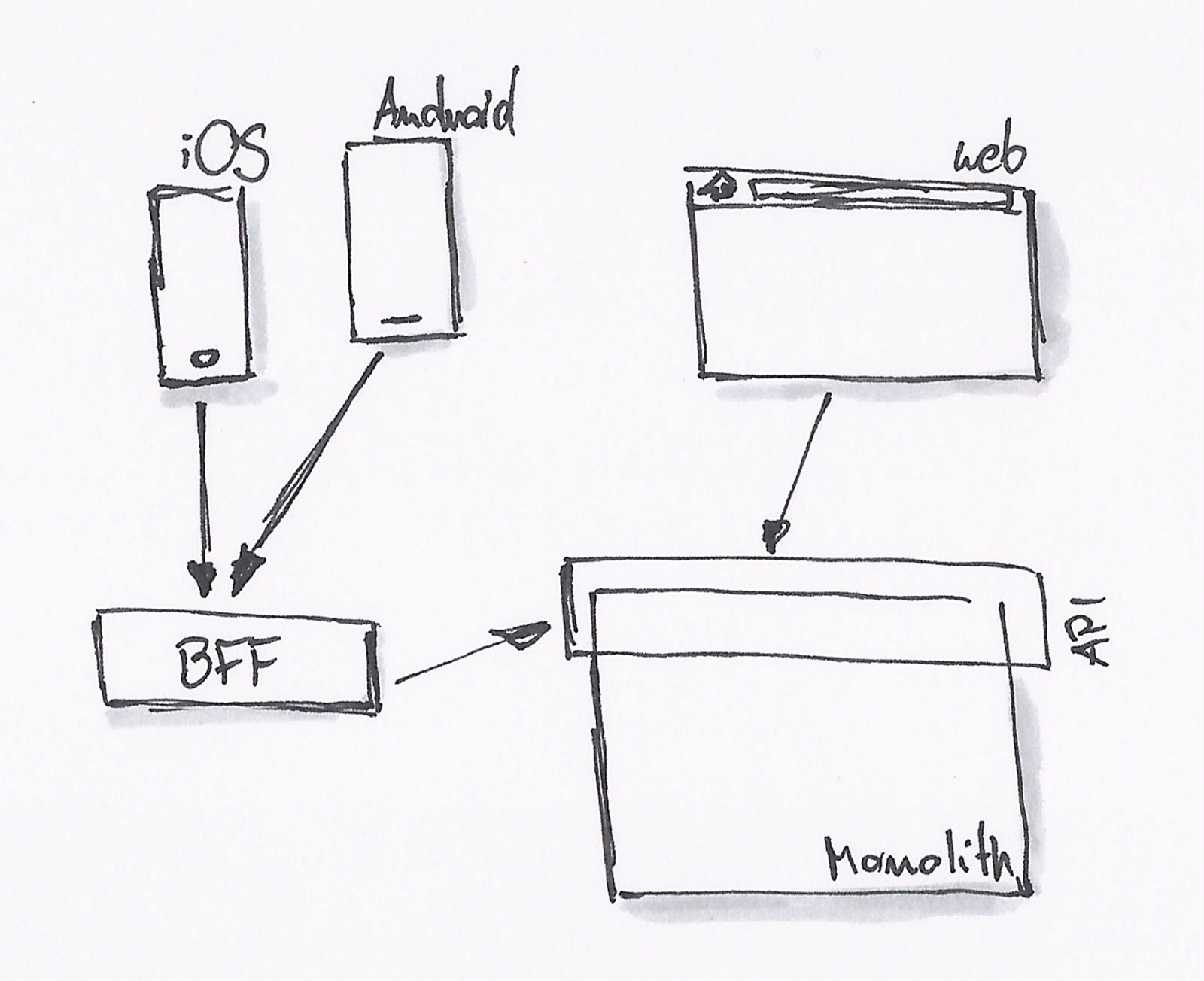
Frontend Developers Writing Backend Code
This shift meant that people, who until now were mainly working on the frontend code with their main expertise around Android or iOS development, needed to reason about backend: different tech stack and different challenges. To help with that, the backend team developed a lightweight library which enabled writing the 'edge services' more easily, taking care of alerting, monitoring, telemetry, authentication as well as applying best practices for rate limiting and cleaning the incoming requests. This helped to standardize the way the BFFs are written, as it is easier to use the BFF framework provided (based on Finagle), rather than to do everything from scratch.
BFF as a Migration Path
One of BFF's characteristics is that it eliminates any direct calls outside of the perimeter to the downstream services. Implementation of this pattern also enabled a minimal invasive migration towards microservice-based architecture, as the BFF hid any underlying changes from the application itself. New features went through the BFF, which then called either the new microservice or the monolith. Whenever further functionality got extracted out of the monolith, the BFF was changed, while the app code remained the same. One can see a similarity to the strangler pattern, where the BFF is strangling the public API offered by the monolith. And so, a BFF called public-api-strangler was introduced to hide the monolith API from the consumers. It was initially just a proxy forwarding the requests to the monolith. Over time, parts from the monolith got extracted and the public-api-strangler just re-routed the requests to the new microservices. Eliminating direct consumer calls to the monolith API, simplified the migration process towards the microservice-based system.

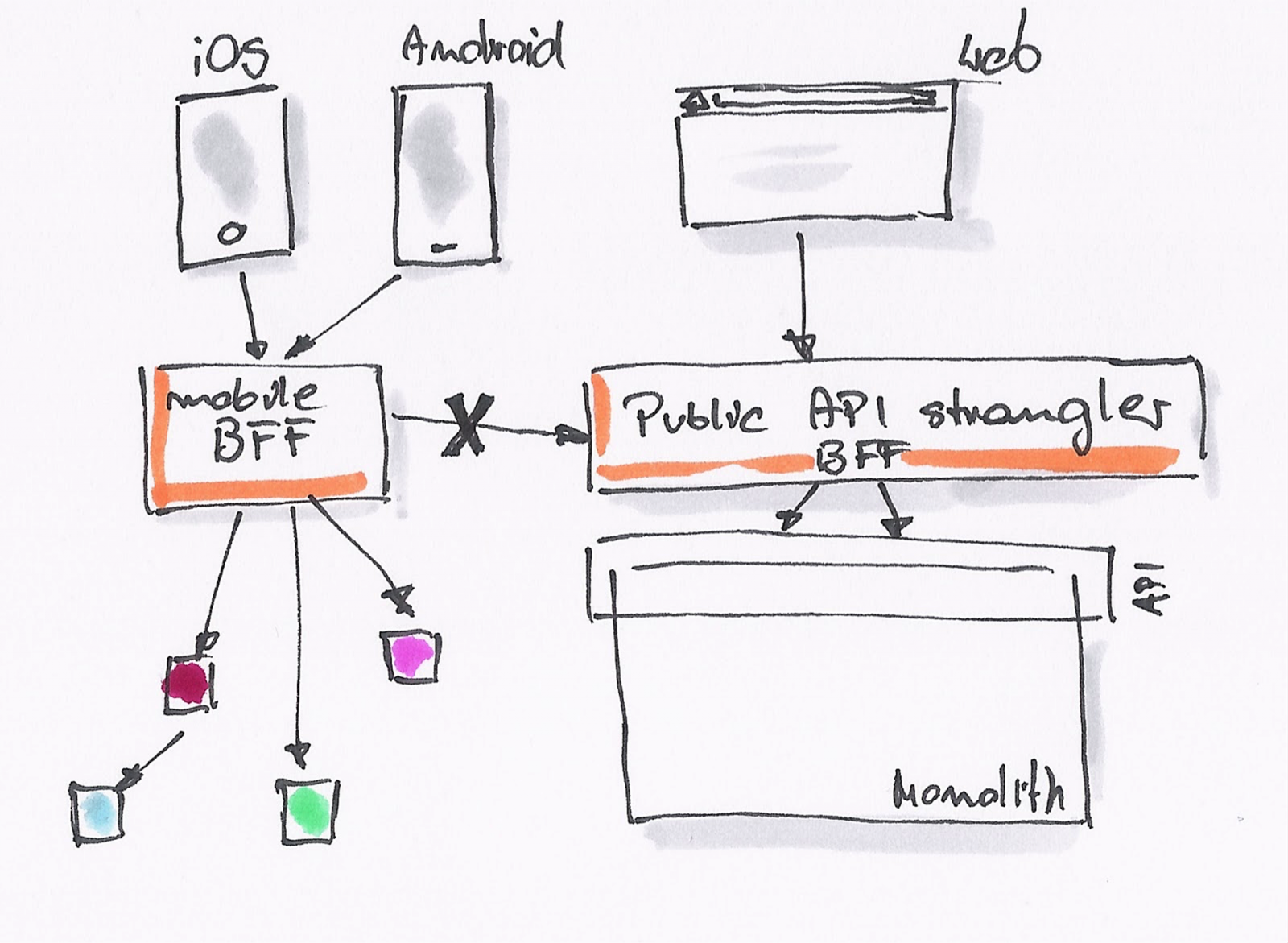
One or Multiple BFFs
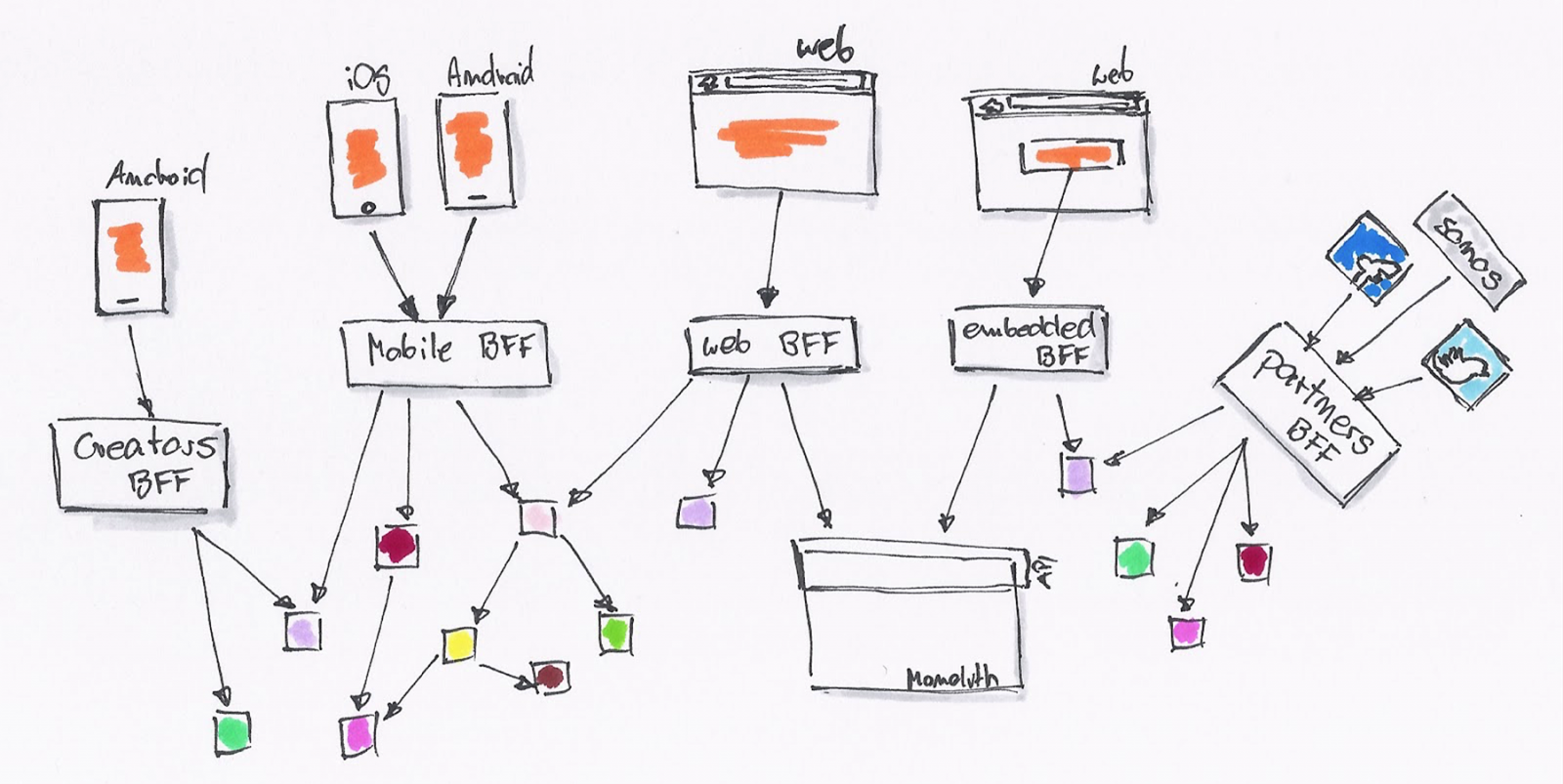
Okay, so how many BFFs should you go for? In the case of mobile platforms, due to limited time and resources, SoundCloud started with one BFF for iOS and Android. In hindsight, it would have been more beneficial to provide one BFF per platform, as the Android and iOS apps are different enough that they expose different API needs. You could also think about providing one BFF per feature, and if a particular feature is present on both platforms, they can use the same BFF. SoundCloud users can be divided into creators and listeners; therefore, it also makes sense to provide one BFF for creators and one for listeners, as these user groups also get separate apps. This is the path that SoundCloud also decided on.
One could try to define even more granular BFFs, encapsulating specific features which would result in more flexibility with scaling and the release cycles of the BFFs. However, as they are still tightly coupled to the app they are serving, and the app release cycle is much 'stricter' due to the platform review process as well as the user's willingness to actually trigger the update, this is disputable.
SoundCloud decided to create a BFF per upstream usecase/experience: it may be an app serving a specific need (e.g. iOS listener app vs. iOS creator app) or the API which is exposed for embedded usage or to strategic partners like Facebook, Twitter or Sonos. Here, the benefits of different needs, especially release cycles, are big enough to justify the efforts.
Currently, all the BFFs are based on the same core library/framework (already mentioned above), which is updated in a weekly release schedule. A shared BFF library has its quirks, such as:
- Adding new functionality to the library too quickly, without letting it mature and put to use in some service first, can lead to an upgrade cascade of all BFFs to a version with bugs or with unstable interfaces
- Allowing enough flexibility and configurability, letting go of the assumption that the default implementation is fine for every BFF
- Keeping the library small and composable, so the developers can choose the parts they need and like
Evolution of a BFF
Now the BFFs at SoundCloud obviously grew over time. Apps got new features, which requested new BFF functionality. This horizontal growth doesn't cause any headache. But the BFFs also grew in depth (vertically) and that exposed some duplication and resulted in extracting new services or parts into core libraries. The question is when something should become a new service or a library. A guiding rule could be: use a shared library if the functionality being extracted doesn't have to be updated at the same time, but if it does, then use a service.

Talking about duplication and reuse, don't try to make everything generic from the beginning. If you try, and it is used across the organization, it will cause friction, as a lot of people will want to contribute. Concentrate on your feature and specific usecases, before thinking about generic usage. The 'particular feature first over generic usage' strategy works far better. And don’t forget about the helpful ‘rule of three’ when thinking about extracting code.
Conclusion
BFF offers a good way to enable teams building different client-facing apps to be in charge of their own destiny. This autonomy is crucial to iterate quickly on the client apps and deliver good experience/features fast. By supporting change, BFF supports evolutionary design and moves the whole system into a better, less-coupled state and then a big single purpose API.
Last but not least, a shout-out to SoundCloud’s Kristof Adriaenssens, Matthias Käppler and Michael England for the BFF story and sharing all the learnings that SoundCloud has had in their journey towards microservices.
The Thoughtworks Technology Radar is published twice yearly. Click here to see the latest edition.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.