














Data strategy
A Streamlined developer experience in Data Mesh (Pt. two)

This is the first blog in a two part series exploring the creation of a streamlined developer experience in data mesh (part two is here). You can read high level data mesh architecture here. The practical learnings explored herein have all been inspired from one of our Data Mesh implementation engagement with a large health care provider.
In the data mesh journey, the platform team plays a critical part: they build the self-serve platform. In this blog, we cover everything the platform team needs to consider when building it.
A self-serve platform is important because it’s responsible for bootstrapping the infrastructure required by the data product teams to build, deploy and monitor data products. As Zhamak Dehghani — the inventor of Data Mesh — describes it, a self-serve platform is really a high-level abstraction of your infrastructure that removes complexity and the friction of provisioning. In other words, the key to a successful self-serve platform is a smooth and intuitive developer experience.
As a first step, platform and data product teams need to work together to define and determine a data product’s high level architecture. This logical architecture is everything that allows it to function effectively for its users.
There are a number of important technical decisions that platform and data product teams need to make together in order to define the product architecture.
These include:
Data Acquisition
How do we ingest data from input ports?
Data Storage and compute
How should we provision resources for data processing?
What should we use to store datasets? Do we need intermediate storage?
Data Modelling and Transformation
How should we apply modeling and transformations on the data?
Data Observability and monitoring
To what extent are we able to follow data lineage within the data product? How easy will it be to identify and debug issues?
How should we monitor the agreed service level objectives (SLOs) to validate the service level indicators (SLIs) to incorporate data observability and improve the trustworthiness of the data product?
Data Governance
How do we define and apply policies such as column/attribute based access control of the data or data masking for sensitive data? How should we model data with global identifiers/business keys to standardize the data product across different domains?
Data catalog
How can we visualize the flow of data from source to consumption alongside metadata documentation?
Where should we catalog data products to make them discoverable across the mesh?
Data visualization and Integration with operational systems
What should the output ports’ access pattern and type (shape of data, format of data) look like to cater to requirements for data visualization and integration with the operational system?
Development and Testing
How do we build the ingestion and transformation workflows to build the dataset required by the data product?
How should we test data products for data quality aspects such as data freshness,accuracy and completeness?
Deployment and Orchestration
How should we deploy data products?
What workflow orchestrator to use to refresh data on schedule based on the user requirements?
The above tasks outlined can be implemented in a number of ways, and this is why a well-designed self-service platform team is essential; it ensures you don’t have to continuously reinvent your data infrastructure. Ideally, we want data product teams to focus on business problems and not solve low-level infrastructure problems again and again.
Based on the technical tasks above, the platform team will decide the first set of platform capabilities, taking a view on what will be enough to constitute a minimum viable product (MVP) for data product teams. This is important; rather than building all capabilities upfront and expecting data product teams to adapt, platform teams should instead be involved in a process of continual discussion about what is required and what will provide the most value.
To illustrate how this works, let’s use an example stack. It’s important to note that while a Data platform stack can vary based on the tooling choices the underlying principles will remain the same.
Here, Snowflake is used for data storage and compute. Data from different sources — including ERP systems used to manage inventory — is ingested to a staging layer in snowflake. This is done using the extract and load jobs run on Talend.
Next, DBT is used for data transformation and data quality testing. JDBC is the standard input and output ports to support addressability. Collibra is used for cataloging the product meta data. For monitoring, meanwhile, Monte Carlo is used. Roles are defined on Snowflake and users are mapped to appropriate roles to grant appropriate privileges to users. Immuta is used to define policy as code and DataOps.live is the CI/CD pipeline.
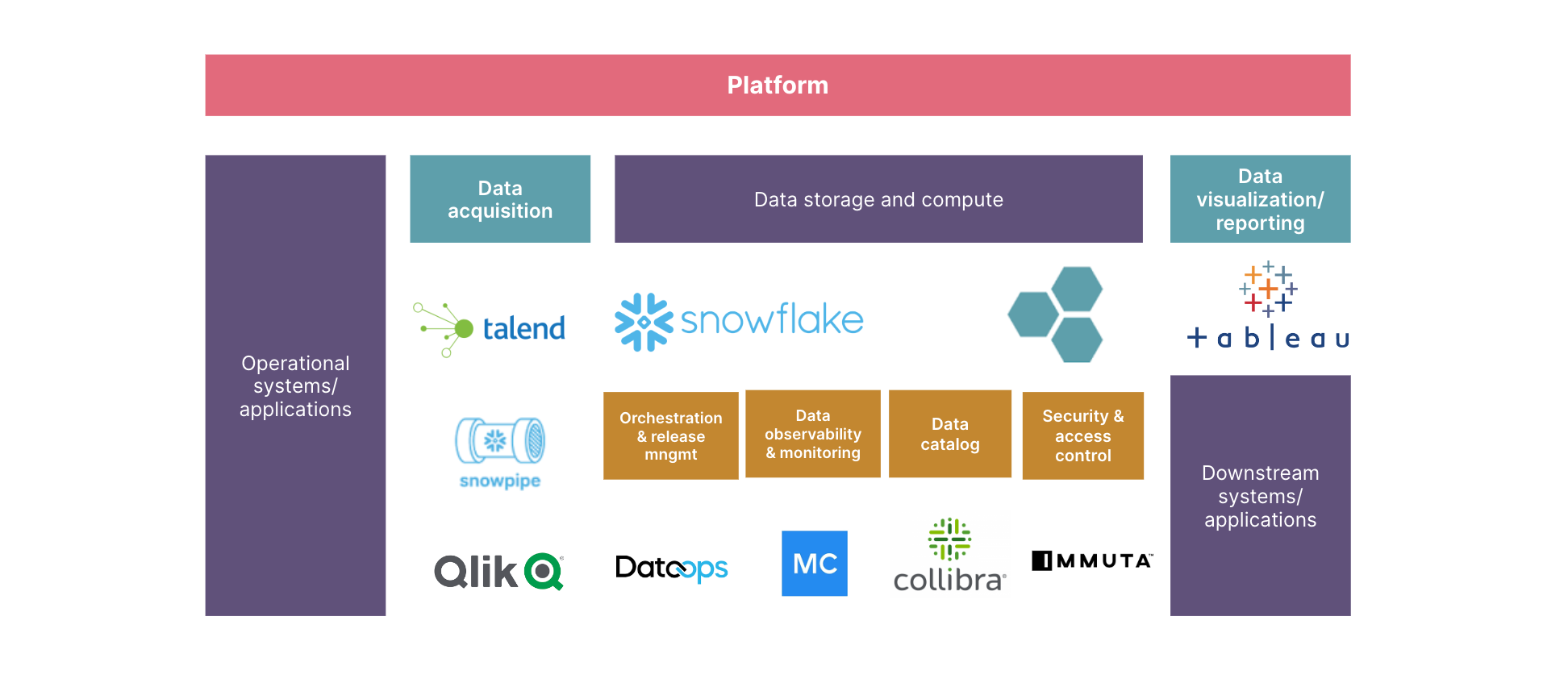
Target platform stack
The above stack is used to define the data product logical architecture as below:
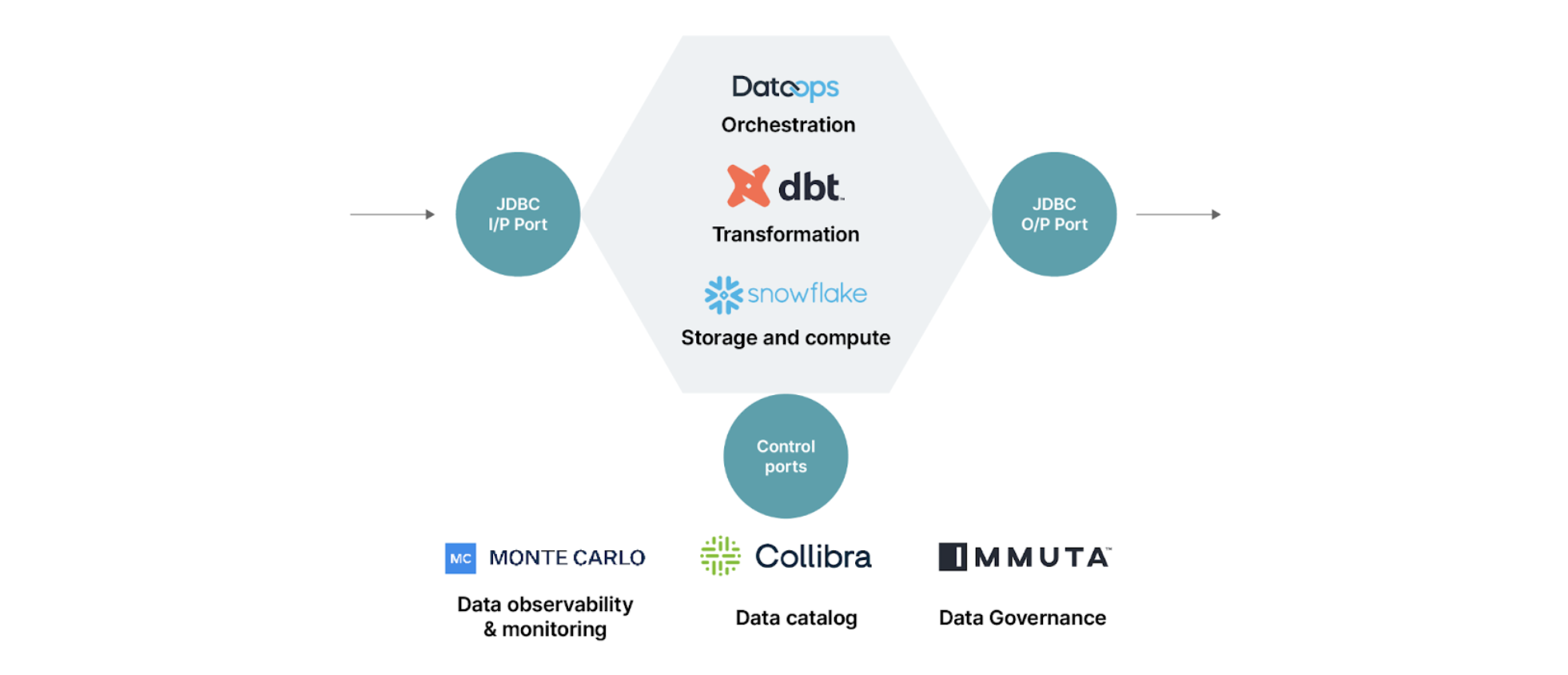
Data product and ports
A data product consists of
Data ingested on a storage via input ports from a source/another data product.
Code to transform data is applied on the stored data.
Output ports to enable consumption of data by other data products or applications such as dashboards for example.
Control ports to support:
Publishing of data product to a data catalog for it to be discoverable across the mesh.
Monitoring metrics around its operations to make visible the Service level objectives thereby increasing observability and trustworthiness of the data product.
Enforcing data policies such attribute based access control,sensitive data masking on the data to ensure data governance aspects such as data sharing and data privacy.
Based on the data product high level architecture and the platform stack, the next aspect considered by the platform team is to design right isolation in the platform for data products.
If data product teams are to function autonomously, it’s important that the self-service platform clarifies the boundaries of given data products. It needs to prevent collisions of different sets of data and resources: this can create confusion and lead to chaos. It can do this through tenancy patterns.
A tenancy pattern delineates access and authorization to specific groups of users to a specific data product (or set of data products). It does this by encapsulating isolations/namespaces on a common capability.
There are two types of tenancy patterns: data tenancy and infrastructure tenancy. Both serve slightly different purposes.
With data tenancy, each data product team has an isolated namespace in which they can store data sets, metrics and metadata.
To return to our example stack, if you were using Snowflake for data storage,each data product will have a dedicated schema for grouping of datasets provided by it. This comes in the form of database objects (tables, views, etc.). These schemas can belong to databases across different environments such as development, test and production.
For quality and monitoring, meanwhile, metrics can also be stored in a different namespace for each data product.To return to our example stack, if you were using Monte Carlo as a data observability platform, it allows specifying namespace for each data product using the monitors-as-code.
For cataloging, data product metadata can be similarly created within a dedicated namespace.To return to our example stack, if you were using Collibra as a data catalog platform, metadata for each data product is grouped using Collibra community.
With infrastructure tenancy, each data product should have its own dedicated compute, storage, governance and deployment infrastructure.
To return to our example stack, if you were using Snowflake for data infrastructure — with storage and compute warehouses for processing — Snowflake warehouses would be created for each domain to support various loads for all the data products within it. In other words, a given data domain within an organization — say, finance — will have its own dedicated Snowflake warehouse..
This has implications for both governance and deployment. For example, each data product will need dedicated roles with relevant privileges that can manage access control for its consumers, and fine-grained access controls to protect particularly sensitive data. For fine grained access control at the level of your data sets, a mechanism to classify sensitive data such as personally identifiable information (PII) is required. In the example stack, Immuta — a governance platform — is particularly useful for this because it offers integration with snowflake's ability to define tag-based policies. In terms of release and deployment management, each data product must have its own deployment pipeline and release management processes in place.
The below diagram illustrates data product tenancy patterns across platforms:
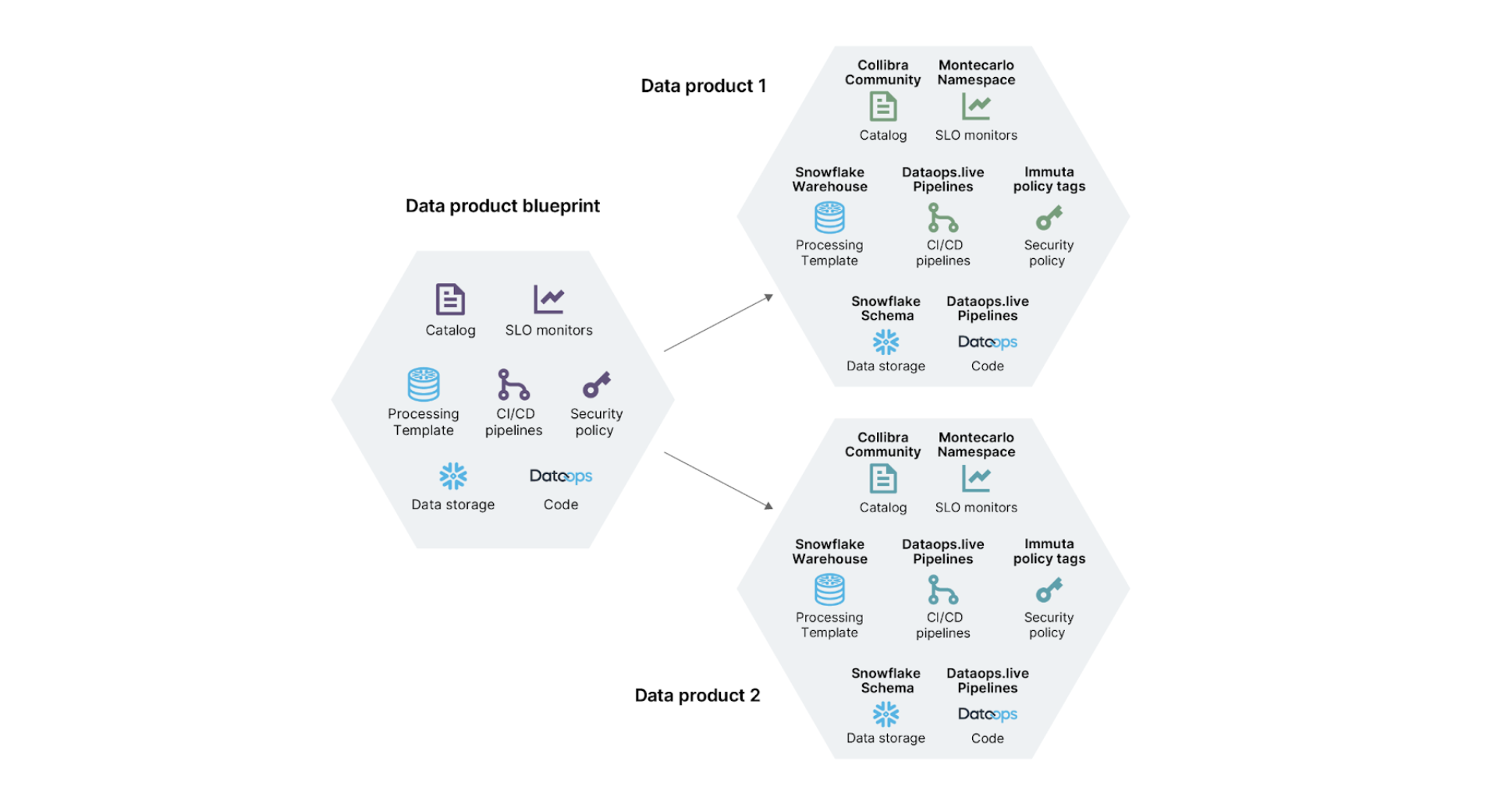
As mentioned earlier, failing to isolate and define data product boundaries can lead to serious issues. These include:
A lack of ownership and autonomy between data product teams.
Harder to provide fine grained access control when data products teams have overlapping storage and infrastructure.
Defining boundaries does not mean data products will be rigid. Once boundaries have been clearly defined, the internal characteristics of the data product such as data access and transformation logic can evolve independently, according to the needs of the product owners and consumers.
The next thing platform teams need to focus on is how to provision and make the self-serve platform available to data product teams.
Once the high level architecture of data products has been defined, the platform team can begin building the components those products need. These components are identified based on the repeated functions in creating data products such as publishing the metadata to the catalog. The platform team should build them as standard reusable components such as jdbc input port, jdbc output port. They should then be entered into a capability registry.
The standard reusable components provided by the platform team together form data product specification for the data product teams.
This specification serves as a contract between the data product team and the platform; it can be defined in a declarative manner. The data product team should provide the specification as a contract and the platform team will then take the necessary steps to satisfy those requirements. This allows decoupling between the data product team and the platform.
This declarative configuration can be maintained in any format. You could, for example, use JSON.
One way it can be done is to use an OAM specification-based approach for data products that'll be created/maintained by the dev team programmatically.
The open Application Model is a declarative specification of the components required to build and deploy the data product. It works by capturing the details of all the entities required for the data product to work. The platform team takes the input so they can then provide the skeleton resources for the data product team. The data product team can then modify the configuration based on their specific requirements.
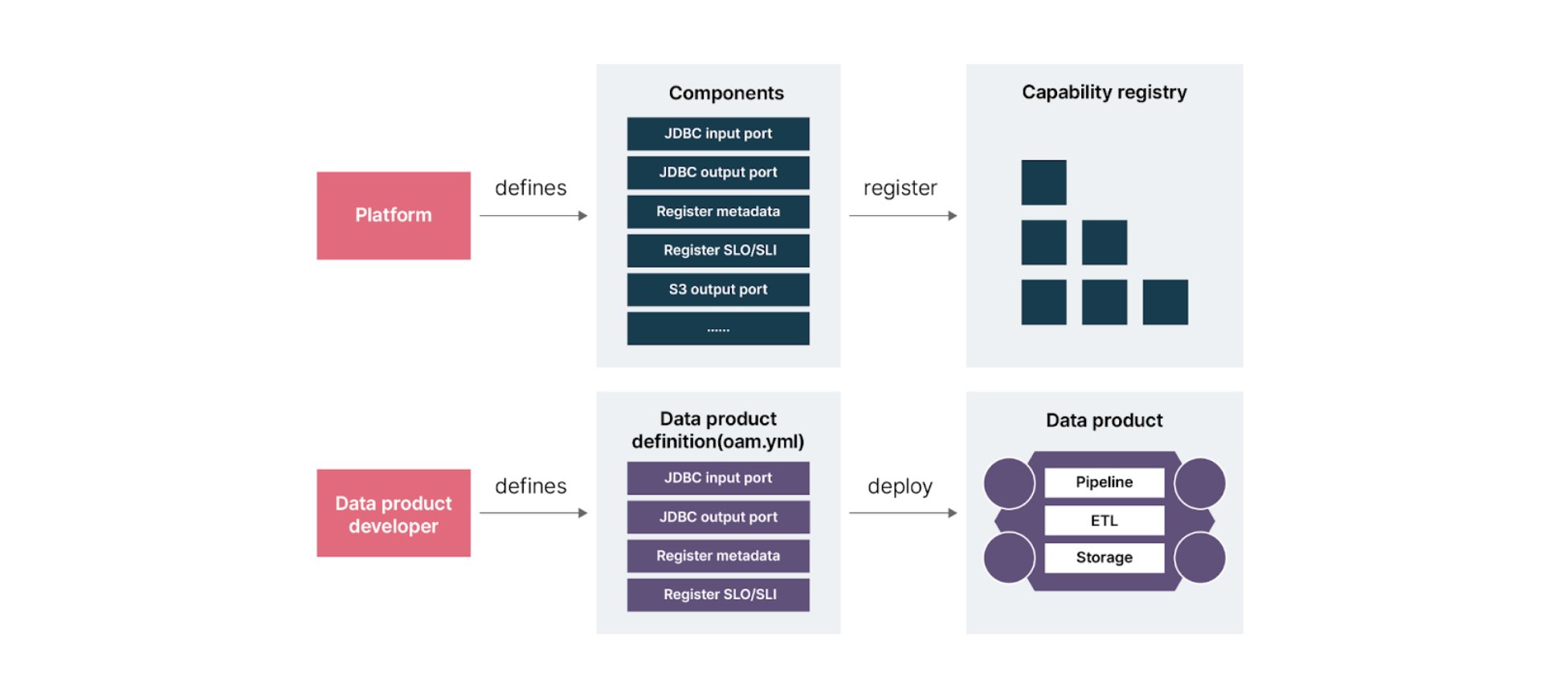
Platform and data product developer interaction
Below is an example of a OAM-based data product specification:
apiVersion: core.oam.dev/v1beta1 kind: DataProduct spec: components: # Domain Details - name: '<Domain Name>' type: domain properties: ... # Data Product Details - name: <Data Product Name> type: data-product properties: ... definition: ... value: '<Description of the data product>' data_product_owner: ... value: '<Product Owner Id>' data_product_type: . .. value: 'Source Oriented' certified: .. value: 'No' # Data Set Details - name: 'Dataset of DP <Data Product Name>' type: data-set properties: ... description: ... value: 'Dataset Description' table_name: ... value: '<snowflake_db>.<snowflake_dp_schema>.<Data Product Name>' table_domain: ... value: '<Data set name>' # Output Port Details - name: 'JDBC-Port of DP <Data Product Name>' type: output-port properties: ... description: ... value: 'You can connect to this JDBC-Port by downloading the Snowflake JDBC Connector.' url: ... value: 'jdbc:snowflake://<snowflake_instance>/?private_key_file=&warehouse=<snowflake_warehouse> &db=<snowflake_db>&schema=<snowflake_dp_schema>' # Input Port Details - name: 'Input from <Input Dataset>' type: input-port properties: ... description: ... value: 'Input Port details' - name: 'Input from DP <Data Product Name>"' type: input-port properties: ... description: ... value: 'Data is consumed from <Data Product Name>' associated_output_port: ... value: 'JDBC-Port of DP <Data Product Name>' # Service Level Objectives SLO Details - name: 'Data is refreshed daily' type: service-level-asset properties: ... description: ... value: 'Data for this data product shall get refreshed every day at least once.' dimension: ... value: 'Freshness' dimension_domain: .. value: 'Reliability Dimensions' # Service Level Indicator SLI Details - name: Daily data refresh indicator over 20-day rolling period type: service-level-indicator properties: ... description: ... value: 'This service level indicator has a passing value (in percentage) which represents the freshness of the data product in the past 20 days for every day.We expect this percentage to be above 80 most of the time and any value above 80 represents that the data product can be trusted with the latest data.' service_level_name: ... value: 'Data is refreshed daily' # Access Instructions - name: 'Access Instructions of DP <Data Product Name>' type: data-sharing-agreement properties: ... description: ... value: 'Instructions To access this data product'
Let’s explore what this means in a bit more detail. The Data Product Declarative Definition (OAM) consists of components and the definitions it provides are critical to the effective functioning of the data product. Data Product is the base entity of this definition.
The Data Product section includes details about the data product, such as its name, function, owner and certified attributes that will assert that it is indeed ready to be used.
The Domain section provides details about the data domain that owns and maintains the data products within an organization.
The Dataset section covers the collection of data elements (such as columns) which are delivered by the data product via output ports.
The Output Port includes information on the delivery mechanism of a data product, representing what each output port provides to consumers.
The Input Port represents how the data is ingested into the data product. Here you’ll find details on the data that is the receiving mechanism of a data product. It can be a dataset/API for source-oriented data products, or an output port of another data product in the case of aggregated/consumer-oriented data products.
The Service Level Asset section is used to communicate the service level agreements that are guaranteed by the data product in order to be considered reliable and valuable to its users.
The Service Level Indicator section is used to define Metrics and KPIs on the service level objectives (SLO) for data products to be considered trustworthy. For example, the Daily data refresh indicator illustrates the percentage of successful data refresh over a given time period.
The Data Sharing Agreement section serves as an agreement between data producers and consumers with terms and conditions including concerning access and sharing of data provided by the data product.
A self-serve platform is a first class principle for data mesh. Its prime objective is to expedite the delivery of data products and shield data product developers from infrastructural complexity. This allows them to focus on the creation and maintenance of data products to add business value, rather than solving the same data engineering problems again and again.
In part two, we discuss how the data product team leverages the self-serve platform to create and maintain the data products.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

