















Transaction foundation models (TFMs) are emerging as a new intelligence layer for banking and payments. They are designed to learn from transaction histories such as payment events, customer behavior, merchant activity and operational outcomes, and turn that learning into reusable embeddings that can improve multiple downstream use cases.
The idea is simple but powerful.
Instead of building a separate feature pipeline and model for every problem (fraud, credit, authorization, reconciliation, customer engagement, liquidity forecasting), an institution can build one shared representation of transaction behavior and reuse it across many models and workflows.
Technically, a TFM is not one component. It is an end-to-end architecture that combines data engineering, transaction tokenization, transformer training, embedding generation, downstream model integration, governance and production deployment.
The most important design principle is to start with a measurable business problem, not with the model itself. Fraud prevention is often the right first use case because it is urgent, measurable and data-rich. Once value is proven there, the same foundation extends into credit risk, authorization optimization, disputes, reconciliation, payment repair, customer engagement and agentic payment orchestration.
This article articulates the steps, the reference architecture and the resources needed to build a TFM. It is the technical companion to the article “The power of transaction foundation models: Building the unified intelligence layer for payments”, which makes the strategic and business case, and it tracks the open reference implementation in the NVIDIA Transaction Foundation Model developer example.
Building the unified intelligence layer for your business
A transaction foundation model learns the “language of money movement.” Just as a language model learns patterns in words and meaning, a TFM learns patterns in transaction sequences: amount, merchant, payment type, channel, timestamp, currency, counterparty, device, location, customer behavior and outcome. These patterns are converted into embeddings, which are mathematical representations that capture behavioral, temporal and contextual signals.
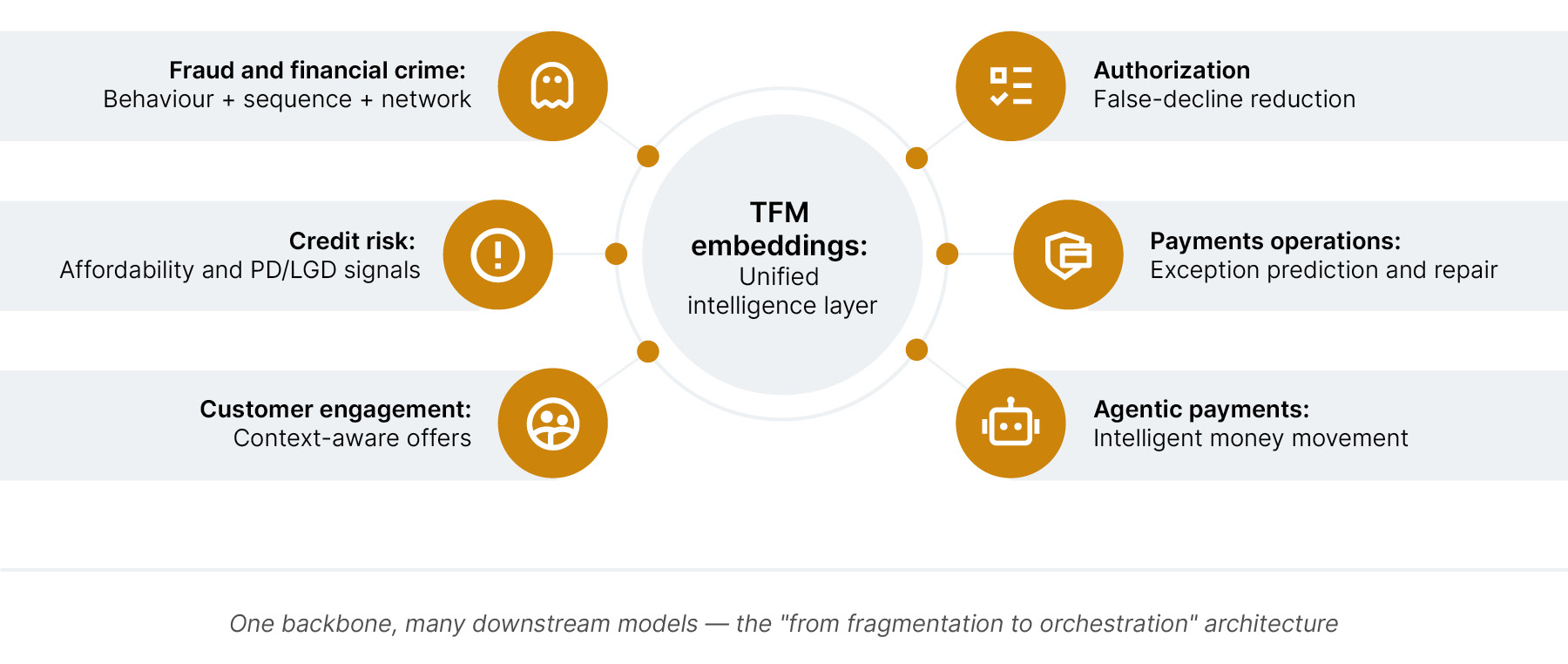
Those embeddings are consumed by downstream models. A fraud model uses them to detect abnormal behavior. A credit model uses them to identify affordability or stress signals. An authorization model uses them to reduce false declines. An operations model uses them to predict payment exceptions. A personalization model uses them to identify relevant customer needs.
The architecture matters because the TFM should not be designed as a one-off model. It should be designed as a reusable transaction intelligence platform: built once, governed once, consumed by every team that touches money movement.
The recipe for a transaction foundation model
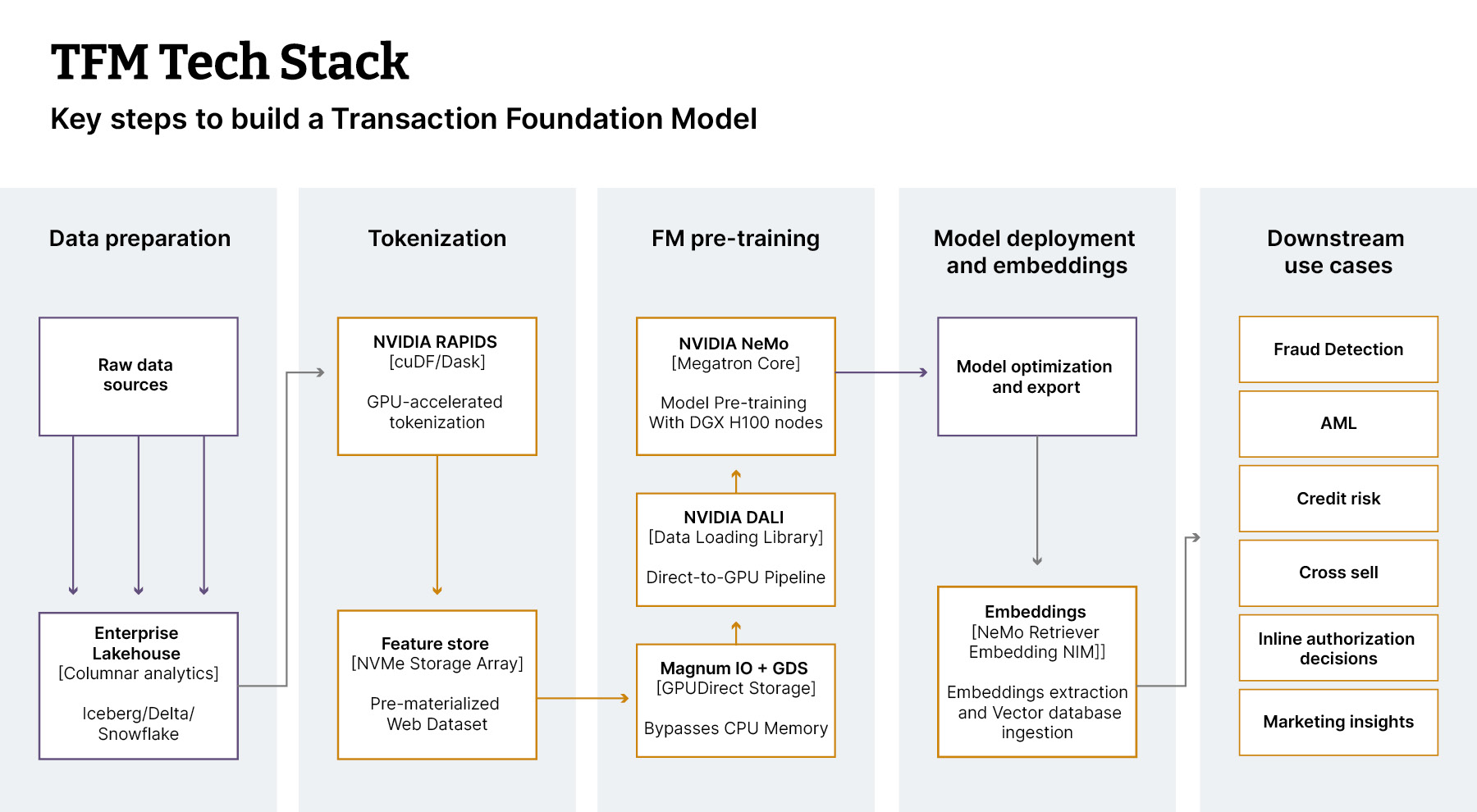
Starting point: Define the first use case
The first question is not, “How do we build a large model?” It is, “Where can reusable transaction intelligence create measurable value first?” Pick something specific, measurable and close to production. Fraud detection is often a strong starting point because the value case can be quantified through fraud loss, recall, precision, false positives, manual review volumes and decision latency.
Good first questions look like: “Can TFM embeddings improve fraud detection for account-to-account payments and reduce false declines without increasing fraud?” This step defines the business objective, baseline performance, target metric, decision workflow, available data and production constraints.
Step 1: Data preparation
Assemble the transaction and event data foundation
A TFM depends on rich, well-governed transaction data. The minimum dataset includes transaction amount, timestamp, merchant or counterparty, transaction type, channel, currency, customer or account identifier and outcome labels. Advanced use cases add device, location, IP, customer profile, merchant metadata, payment rail, authorization response, fraud outcomes, chargebacks, disputes, sanctions outcomes, servicing events and app behavior.
The aim is not to collect every field on day one. The aim is to create a high-quality, sequenced view of behavior over time, with strong data engineering underneath: schema mapping, lineage, quality checks, consent and privacy controls, entity resolution, deduplication and temporal ordering. In payments, time matters — the model must be trained and evaluated in a way that reflects how decisions would have been made in the real world (point-in-time correctness).
Normalize, sequence and prepare the data
Raw transaction data is not ready for transformer training. It must be converted into coherent sequences. Group events by the right entity — customer, account, card, merchant, device, counterparty — and order by time. Define windows that match the use case: fraud needs recent high-resolution sequences; credit needs longer-term income and spend patterns; operations needs sequences of payment failures, retries, repairs and settlement events.
This is where data science and payments domain expertise have to work together. The model should learn from patterns that make sense in the payments context, not from arbitrary rows in a table.
Step 2: Tokenize transaction data
Tokenization is the most distinctive technical decision in a TFM build, and a small set of choices has a large effect on model quality:
Amount fields: Bucket using log-spaced or decile thresholds; never feed raw values.
Time-delta tokens: Choose a granularity (minutes for fraud, days for credit) that matches the downstream task.
High-cardinality fields (merchant ID, counterparty, device): Use top-K + UNK, hashing or learned embedding tables.
Categorical fields (channel, payment rail, status): Implement direct token mapping.
Outcome tokens (approved, declined, disputed, fraudulent): Inject explicit tokens so the backbone learns the supervisory signal in pre-training.
A good tokenizer balances domain meaning, privacy, scale and model efficiency. The NVIDIA Transaction Foundation Model developer example provides a custom NVIDIA CUDA-X -powered tokenizer for this stage, which is useful because tokenization and preprocessing routinely become the bottleneck at large transaction-data scale.
Step 3: Train the transformer backbone
Once sequences are tokenized, the foundation model can be trained. The NVIDIA reference uses NeMo AutoModel to train a decoder-only transformer with causal language modeling — the model learns what tends to happen next in a transaction sequence. Other approaches use masked event modeling, where the model reconstructs missing events or attributes. Model size is a function of data scale and task complexity.
The goal of pre-training is to produce a model that learns useful representations of financial behavior: recurring patterns, abnormal shifts, behavioral similarity, merchant relationships, temporal context and risk signals.
Step 4: Generate reusable embeddings
After training, the model is used to generate embeddings, which are compact numerical representations of a transaction sequence, customer, account or merchant. A few decisions shape how reusable they are:
Pooling strategy (last hidden state, mean pool, CLS-token analog): Controls what the embedding captures.
Granularity: Per-transaction, per-customer rollup over a window, or per-merchant aggregate.
Frozen vs fine-tuned: Frozen embeddings are simpler to govern; fine-tuned embeddings give more lift per downstream task.
Dimensionality: Typically 128–768; lower dimensions cut serving cost, higher dimensions preserve more signal.
The embeddings are stored in a vector database and served through an embedding service. From this point on, fraud, credit, operations and personalization teams all consume the same intelligence layer. This is the architectural pivot that turns isolated AI pilots into a shared bank-wide asset.
Step 5: Evaluate against a baseline
The right evaluation is a three-way comparison: existing raw features only, TFM embeddings only and raw features + TFM embeddings. The third typically wins, and the lift is what unlocks budget for the next use case. The NVIDIA Transaction Foundation Model developer example demonstrates this pattern using XGBoost on top of raw features, TFM embeddings and combined features.
The final mile: Integrate into decisioning and workflows
A TFM creates value only when its outputs are embedded into business processes. In fraud, this means feeding embeddings into a fraud-scoring model, case-management system or real-time decision engine. In authorization, it supports approval optimization and false-decline reduction. In operations, it supports exception routing, payment repair or reconciliation. In credit, it augments affordability models or early-warning indicators.
The integration pattern depends on latency. Card authorization and real-time payments need sub-100ms end-to-end inference, solved on the NVIDIA platform with NIM, Dynamo-Triton and TensorRT-LLM. Credit decisioning and customer engagement can run near-real-time or batch; operations can run offline. The architecture must also include fallback logic, human-in-the-loop review for high-impact decisions, A/B or shadow deployment, and continuous drift monitoring on both embeddings and predictions.
Under the hood: A TFM reference architecture
A practical TFM reference architecture can be structured across nine layers. Each layer is modular. The TFM should not force every downstream team onto the same model or workflow; it should provide a shared intelligence layer that can be consumed through controlled interfaces. The color zoning below maps the layers to five functional groups: data (green), tokenization (yellow), model training and serving (blue), decisioning (purple) and governance (black).
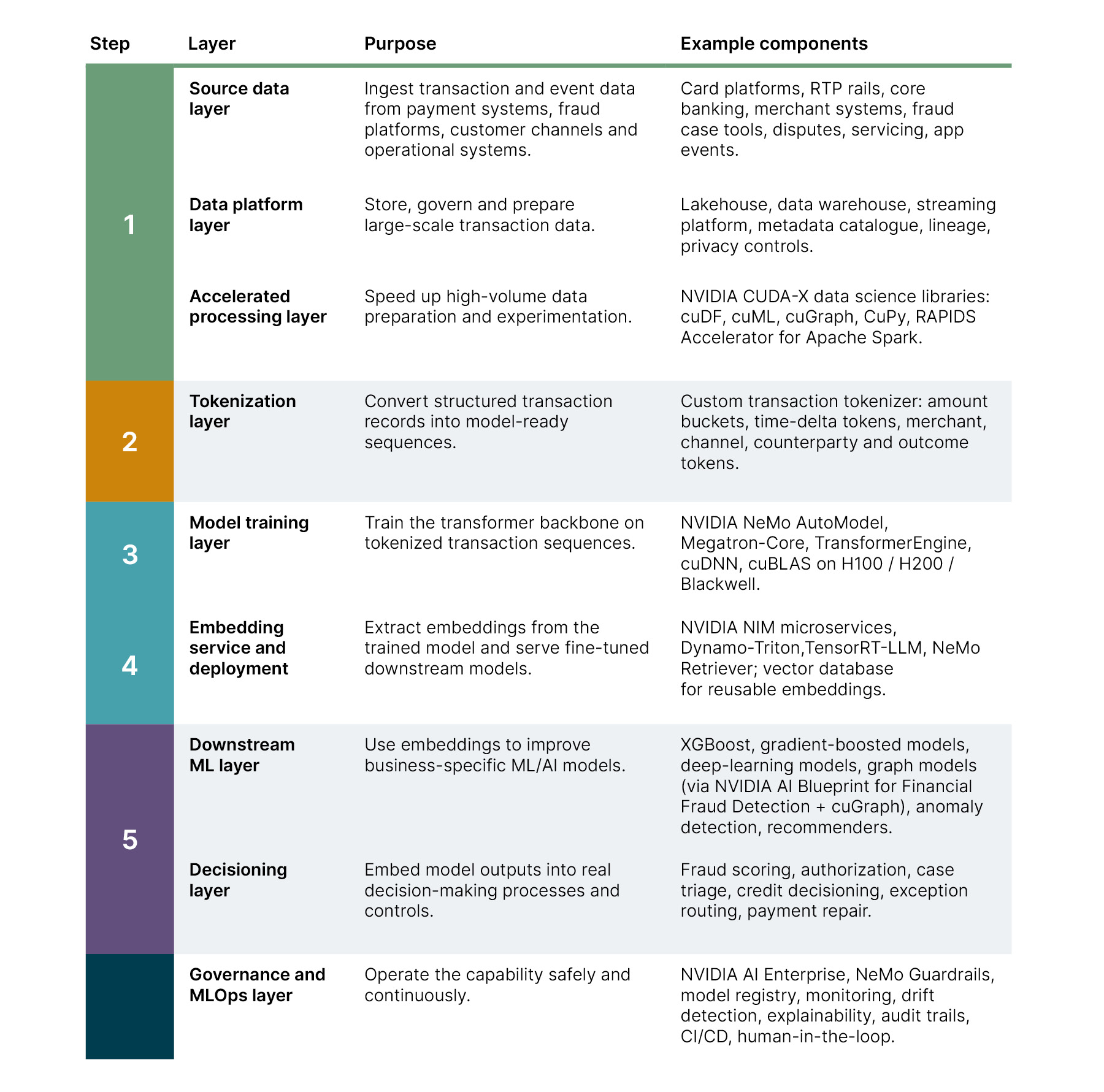
Key building blocks for a production-ready TFM
Delivering a TFM as close to production as possible requires three categories of building blocks: infrastructure, AI libraries and enterprise integration.
Infrastructure
The compute layer is central. GPUs accelerate the most demanding parts of the pipeline: high-volume data preparation, tokenization, training and embedding generation. NVIDIA H100, H200 and Blackwell GPUs are typical for serious training and inference workloads, with A100 as a reasonable starting point for experimentation.
Cloud infrastructure options
For institutions deploying on AWS, a comparable stack is available natively. AWS supports secure ingestion of high-volume transaction, authorization, device, merchant, customer, dispute, and fraud-label data through Amazon S3, AWS Glue, Amazon EMR, Amazon Redshift, and managed feature stores. Model development, fine-tuning, evaluation, explainability, monitoring, and deployment are supported through Amazon SageMaker. For training large transaction models at scale, Amazon SageMaker HyperPod provides distributed training across thousands of accelerators with resilient, self-healing infrastructure, node management, checkpoint recovery, and long-running job support.
The data platform supports both batch (training, back-testing, embedding refresh) and streaming (real-time fraud, authorization, operations). Storage must support raw data, curated data, tokenized sequences, training datasets, model checkpoints, embeddings and downstream feature sets — with encryption, access control, lineage, retention and auditability in regulated environments. For production serving, the institution needs low-latency APIs, scalable inference services, fallback mechanisms and integration into existing decisioning platforms.
NVIDIA libraries and tools
The TFM economics only close because the NVIDIA AI computing platform is codesigned end to end. The same accelerator that trained the backbone also serves it; the same memory bandwidth, NVLink, NCCL collectives and Magnum IO that make distributed training fast also make distributed inference cheap. A non-codesigned stack will not deliver TFM performance at production scale.
Key components of this unified architecture include:
NVIDIA CUDA-X (cuDF, cuML, cuGraph, CuPy): GPU-accelerated dataframes, classical ML, graph operations and tokenization. ~88% data-processing cost saving vs CPU per the published NVIDIA AI Blueprint for Financial Fraud Detection.
NeMo AutoModel, Megatron-Core, TransformerEngine: Scalable training of transformer architectures, supporting Hugging Face-compatible decoder and encoder models. Used in the the NVIDIA Transaction Foundation Model developer example to train the decoder-only TFM over tokenized transaction sequences.
NIM microservices, Dynamo-Triton, TensorRT-LLM, NeMo Retriever: Production embedding service and downstream-model serving inside the sub-100ms latency budget that real-time payment authorization requires.
NVIDIA AI Enterprise: The certified, supportable production runtime that lets the institution deploy this stack as a sovereign AI factory: on-prem, regional/sovereign cloud or public cloud, with the same software contract everywhere. The data and the model never leave the institution's jurisdiction.
NVIDIA AI Blueprint for Financial Fraud Detection (GNN): The complementary blueprint that pairs graph neural networks with TFM embeddings for fraud and AML. TFMs capture behavioral and temporal patterns; GNNs capture relational structure across accounts, devices, merchants and counterparties.
Enterprise integration components
Beyond the AI stack, a production TFM needs enterprise-grade controls:
A vector database makes embeddings reusable across teams.
A model registry tracks model versions, training datasets, parameters, evaluation results and approval status.
An evaluation layer measures both extrinsic metrics (how well downstream models perform) and intrinsic metrics (the mathematical properties of the embedding space itself).
A monitoring layer detects training instability, hardware inefficiency, inference SLA compliance, capacity planning and embedding drift.
An explainability layer helps risk, compliance and operations teams understand how embeddings influence decisions.
A governance framework covers privacy, bias testing, human oversight, auditability, regulatory review and model risk management.
A decisioning integration layer connects the TFM into fraud engines, authorization systems, credit platforms, operations tooling and agentic orchestration layers.
Designing for regulated financial services
TFMs in banking and payments must be designed differently from experimental models. They need explainability because decisions affect customers, merchants and financial outcomes. They need resilience because payments operate 24/7. They need latency discipline because fraud and authorization decisions happen in milliseconds. They need monitoring because fraud patterns, customer behavior and payment flows change continuously. They need governance because data privacy, fairness, security and auditability are non-negotiable.
The best architecture is therefore hybrid. A TFM does not replace every existing rule, model or decision engine; it augments them. The strongest pattern combines TFM embeddings, graph intelligence, gradient-boosted models, hard rules, case-team feedback and human review.
The combination matters most for fraud and scams: TFMs capture behavioral and temporal patterns, graph models capture relationships across accounts, devices, beneficiaries and merchants, rules enforce hard controls and case teams provide the feedback that keeps the model honest over time.
How to start
The safest path is staged.
In a 3-day concept phase, identify the priority use case, define the scope, assess data readiness and shape the value case.
In a 3-week prototype phase, build a working pipeline using real or representative data. Tokenize transactions, train or adapt a model, generate embeddings and compare performance against the current baseline.
In a 3-month MLP phase, harden the capability for production or controlled pathfinder deployment. Add monitoring, explainability, governance, workflow integration and a roadmap for reuse.
This staged approach reduces risk and accelerates value. The first use case proves the model. The next use cases prove reuse. Once fraud value is demonstrated, the same transaction intelligence foundation can extend into credit risk, affordability, authorization optimization, disputes, reconciliation, payment repair, liquidity forecasting, customer engagement and merchant insights.
Over time, the institution creates a proprietary transaction intelligence layer that continuously learns from money movement, operational outcomes and customer behavior, turning payments data into reusable enterprise intelligence.
Thoughtworks and NVIDIA support this journey in a practical way.
NVIDIA provides the accelerated compute, AI tooling and blueprint patterns — NVIDIA CUDA-X, NeMo, NIM, Triton, NVIDIA AI Enterprise and the open TFM Blueprint — codesigned for the data, training and inference economics this workload demands.
Thoughtworks brings the engineering archetype that turns those patterns into a regulated production capability: deep learning engineers to design the tokenizer and train the backbone; AI researchers to choose architecture, embedding strategy and evaluation regime; and domain-specific data scientists to embed the model in the business.
The goal is not a large model for its own sake; it is a reusable intelligence foundation that helps the institution make better decisions across fraud, credit, operations, customer engagement and the future of agentic payments.
References
NVIDIA Blueprint on GitHub · NVIDIA Financial Fraud Detection Blueprint · Thoughtworks: The power of TFMs · Thoughtworks: GNNs in fraud prevention · Revolut PRAGMA (arXiv:2604.08649).