














Generative AI
Context-aware incident handling with MCP: A strategic view with a practical case

The observability landscape for IT operations has rapidly evolved in recent years with a plethora of both open-source and commercial off-the-shelf (COTS) tools now available. Despite these advances, many organizations still find existing solutions fall short of meeting the complex real-world demands of site reliability engineering (SRE). Let’s explore where the current ecosystem falls short and outline our vision for an autonomous observability accelerator: a modular AI-powered system that ingests alerts, correlates logs/metrics/traces, pinpoints root cause automatically and sends business-friendly reports to the right people without manual intervention.
Current observability platforms connect to many systems and convert logs into alerts based on rules. On the surface, this improves visibility. However, it only solves part of the SRE problem. After an alert fires, engineers typically face a tedious, multi-step investigation:
Fragmented analysis: An SRE might jump between several dashboards, sift through logs and trace data across services to find the root cause. This manual hunting is time-consuming and error-prone as systems grow more complex.
Slow handoffs: Once engineers identify an issue, they must relay it through systems like Slack, Teams or email to business stakeholders. Each handoff introduces delays and risks miscommunication, slowing down fixes.
Reactive workflows: Traditional tools wait for incidents to happen and then trigger alerts. This means teams only respond after problems surface, rather than anticipating issues or learning from anomalies proactively.
Together, these limitations can dramatically extend mean time to resolution (MTTR), waste skilled SRE time on routine work and leave business teams confused by technical jargon instead of clear impact statements.
To truly empower SRE teams and support business stakeholders, the observability process needs to be transformed from a fragmented workflow into a seamless, autonomous loop — one that minimizes or even eliminates human intervention in root cause analysis.
Key improvements with autonomous observability:
Dramatically reduce MTTR (mean time to resolve): Automated RCA can cut detection and resolution time from hours (often three to four hours of manual investigation) down to minutes, by instantly correlating events with underlying causes.
Optimize human effort: By offloading repetitive diagnostic tasks to intelligent systems(Example : looking at alerts ,correlating them to specific traces & logs and then getting the context of error ) SREs are freed to focus on high-value work like performance tuning, reliability improvements, and strategic architecture changes.
Business-centric insights: Instead of bombarding managers with error logs, the system translates issues into plain business terms. Stakeholders instantly see not just the “what” but also the “why” and “how” of system incidents.
The existing organizational flow for incident management relies heavily on manual processes and fragmented toolchains, involving:
Event generation: System logs from servers and applications feed into monitoring tools. Alerts are generated by traditional rules (for example, when error rates spike).
Triaging and analysis: SRE engineers receive the alert and begin manually examining dashboards, logs, and traces. They look for patterns and clues to identify business impact and root cause.
Communication: Once business problems are deduced, SREs relay issues to the relevant business users through channels like Slack, Teams, or Google Chat.
Resolution: The team applies fixes or mitigations. This loop of diagnosing, fixing, and updating stakeholders repeats until the incident is resolved and systems stabilize.

While this process ensures someone is looking at the problem, it is reactive and labor-intensive. Each step depends on human intervention, which stretches MTTR and crucial insights may be delayed, under-documented, or fragmented across teams. By automating data correlation and surfacing high-fidelity signals, AI augments this human judgment, reducing MTTR.
Now picture the autonomous alternative:
Smart ingestion: Alerts from all systems automatically flow into the AI engine without waiting for someone to review dashboards. Webhooks or built-in hooks trigger the process as soon as an anomaly appears.
Automated RCA: The system immediately begins correlating logs, metrics, and traces across your stack. Using AI/ML (for example, models like Gemini orchestrated via LangChain), it pinpoints the root cause and quantifies the business impact without human intervention.
Contextual notifications: A clear, concise report is generated that describes the incident in business terms (what broke, why it matters, and next steps). This report is automatically sent to the right channels (e.g. a Slack or Teams group) so decision-makers see the issue instantly.
Hands-off operation: The entire pipeline runs in the background, asynchronously. SREs do not need to drive the initial analysis, allowing them to jump straight into resolving the verified root cause.
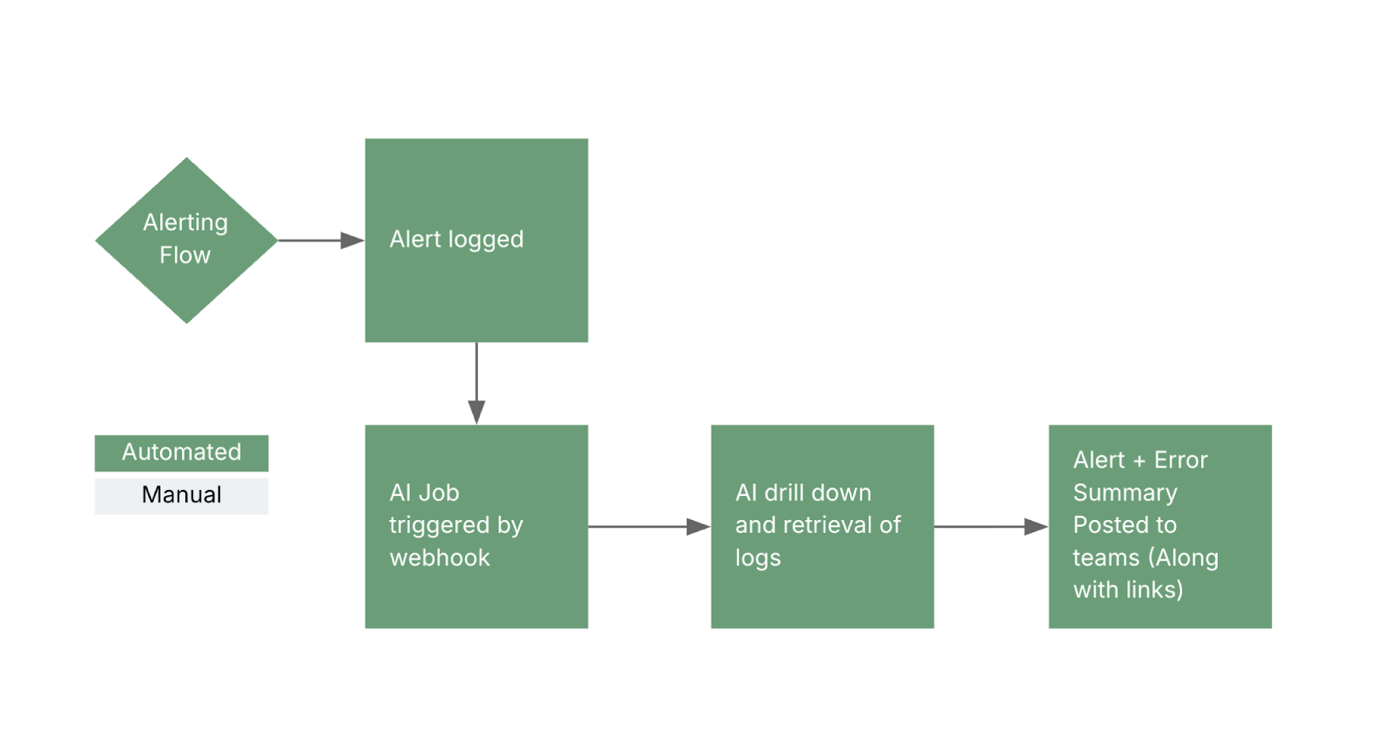
To realize this autonomous observability vision, the solution follows a modular architecture:
Automated trigger: The observability stack (like Google Cloud’s alerts) automatically kicks off the workflow. No extra clicks or inputs are needed.
Ingestion layer: Integrates directly into Google Cloud Logging API via an MCP connected to the AI agent, allowing for automatic retrieval and decoding of inputs.
Correlation and reasoning with AI/ML : At the heart is an AI-powered Correlation and Reasoning engine (e.g. Google’s Gemini model, managed and orchestrated with LangChain and LangGraph). It digests logs, metrics and traces to uncover root causes, trends, and correlations that a human might miss.
Automation engine: This component maps technical issues to higher-level business concepts. It translates the technical analysis into both a detailed technical report and a simplified business-facing summary for each incident.
Notification hub: Once an incident is diagnosed, the insights are automatically delivered through the organization’s communication tools to the appropriate teams.
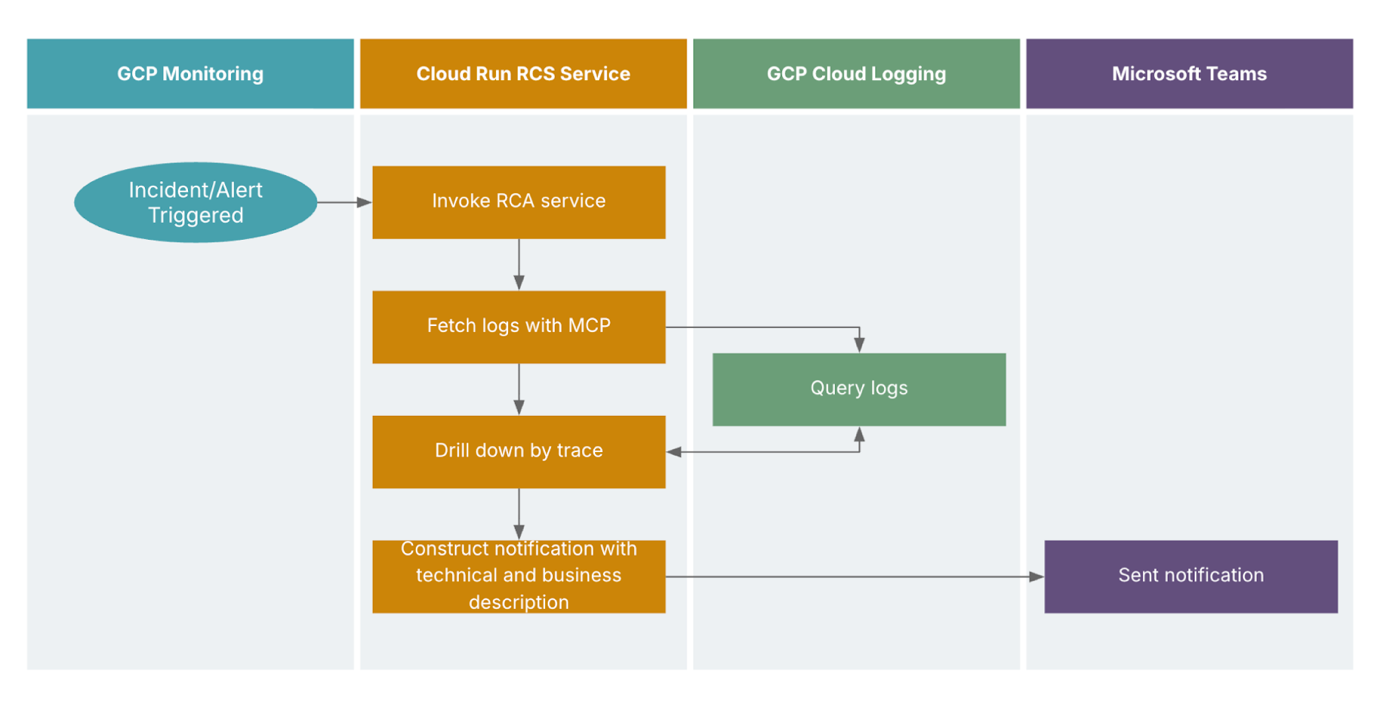
The swim lane diagram visually describes the interaction between various components.
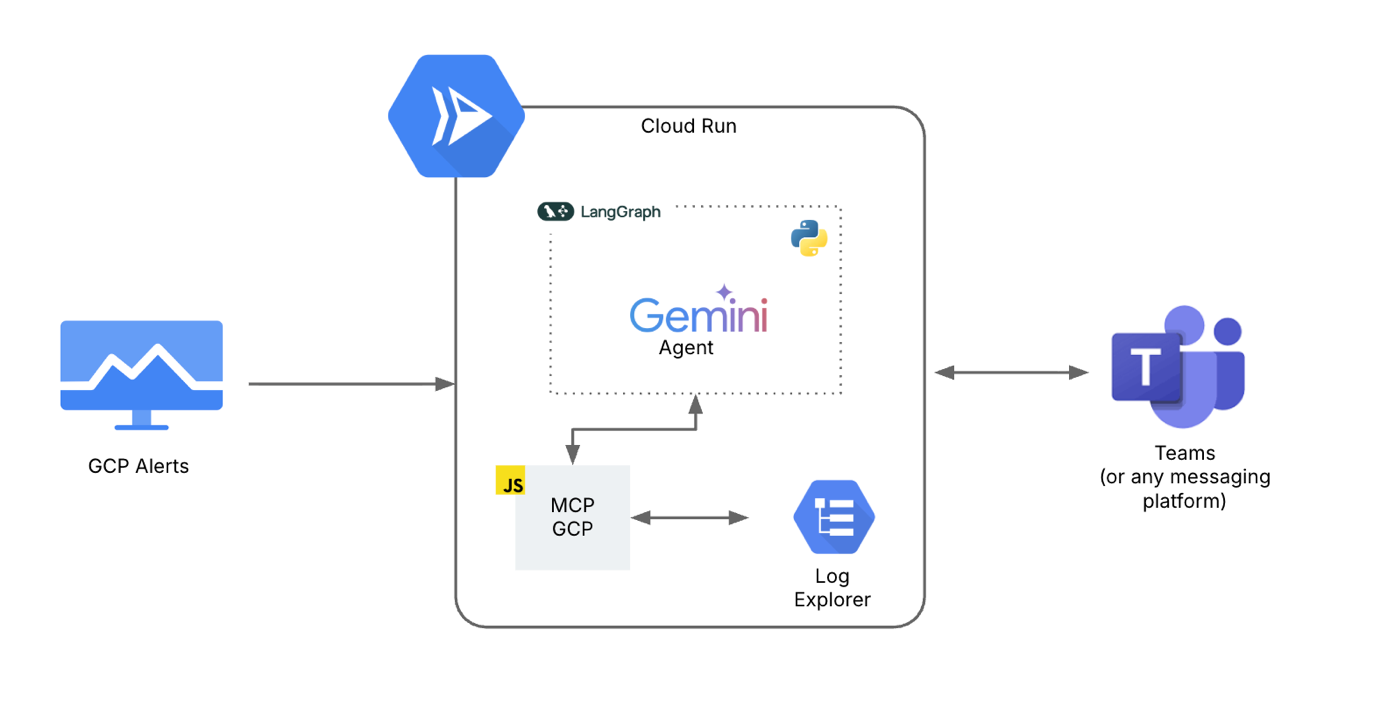
The main component diagram illustrates core solution modules:
Observability integration points [GCP Alerts]
AI/ML RCA engine [Cloud Run]
Communication connectors [Teams]
GCP Alerts: Google Cloud Monitoring raises alerts when defined thresholds, like error counts or latency, are breached. These alerts act as the trigger that starts the entire flow.
Cloud Run: A fully managed serverless environment where the AI application runs. It ensures scalability and executes the logic for processing alerts in real time
AI Agent (LangGraph + Gemini + Python): The agent orchestrates workflows using LangGraph, analyzes logs with Gemini, and runs logic in Python. It transforms raw alerts and logs into human-readable insights.
MCP GCP: A Model Context Protocol server that provides a secure interface for the AI agent to query Google Cloud resources. It abstracts direct SDK calls and standardizes log retrieval.
Log Explorer: Google Cloud Logging’s interface where application logs are stored and searched. The agent retrieves both alert logs and original error logs here for deeper analysis.
Teams (or any messaging platform): The destination where enriched alerts and insights are posted.
To speed up adoption, this entire observability solution is packaged as accelerator, enabling Thoughtworks teams to implement and adapt autonomous observability for client needs.
The path forward is clear: move away from slow, fragmented monitoring towards an intelligent observability ecosystem. By harnessing AI and automation for root cause analysis .
Operational benefits :
Radically reduce MTTR: What once took 4-8 hours of manual investigation can now be resolved in minutes.
Repurpose human expertise: Engineers shift from routine firefighting to high-impact work on performance and reliability.
Deliver clear business insights: Incidents are communicated in terms that executives and stakeholders understand, ensuring faster alignment and decisions.
Boost resilience: Faster incident resolution and better context mean systems stay up more reliably, and teams stay focused on strategic goals.
Business benefits:
Autonomous RCA enables non-technical staff from product teams and managerial staff like engineering managers to quickly understand the root cause and enable the relevant teams to act accordingly thereby reducing the MTTR.
Saves valuable time for engineering staff thereby allowing them to focus on more important and pressing goals.
LLMs can present the RCA in such a way that it bridges the gap between product and engineering staff, ideally creating a better shared understanding of issues and improving overall synergy within the team.
Greater shared understanding of an ongoing issue improves the quality and timeliness of advisories which communicate issues between verticals/departments of the same organization when there is a
Traditional RCA meetings can be cut short using the inputs made available through the Autonomous RCA system, thus saving precious time.
Time spent on reporting issues and system health can also be greatly saved through summarization, trend analysis and forecasting of issues through the same autonomous RCA System.
Autonomous observability reframes the relationship between people and systems: SREs retain their critical role, but with AI-driven support, their energy shifts from reactive incident work to driving systemic improvements and aligning reliability with business goals. This is the vision advanced by the Thoughtworks DAMO AIOps, which lays the groundwork for long-term operational excellence & beyond.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

