














On our journey to allow for faster delivery times, wowing customers with new features and allowing for quicker support, we made a decision to move Mingle to a 'Software as a Service' on the cloud. We spent a few months architecting Mingle to suit the features and limitations of the cloud and this is the story about that effort.
Our first challenge was to build something quick and customer-facing. We wanted to engage with the customer as early as we could by providing a cloud-based web trial. Architectural changes were introduced piece-by-piece to allow for assessment and tweaking. The trial system was the same Mingle available as a packaged installer - except that we were doing the operations work. The user could thus have a dedicated instance of Mingle on the cloud and get started on it, with just a sign-up.
While doing this we also wanted to be cost-conscious. Considering how costs on the cloud add up over time, we were constrained by how much we could spend on each customer. Given how most cloud services operate and charge, the majority of our costs were using specialized services like compute, database and network traffic. Cost of storage, load balancing and stock services like caching turned out to be a percentage of the specialized and more expensive services. In order to minimize these costs, we examined the option of building such a system, and found examples on Unix systems. On Unix, you can build 'jailed environments' on top of chroot or its Linux clone lxc. We could also get control on how these services could be expanded or contracted based on metrics of usage. This was our first architecture change.

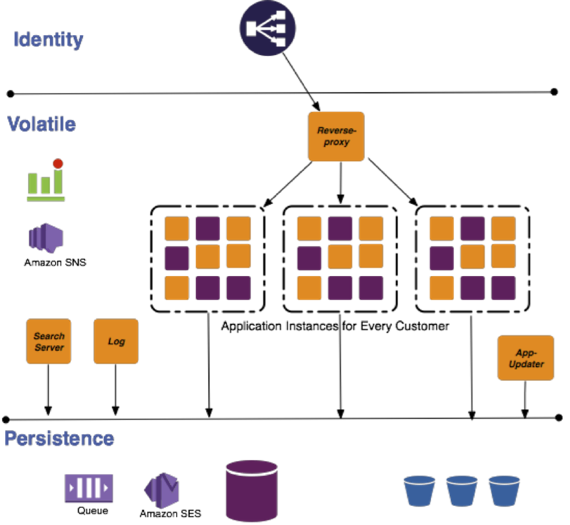
Using lxcs as our control and isolation mechanism worked well since:
- lxc were guaranteed by Linux to be isolated and independent environments.
- We could multiply the lxc or throw it away.
- A simple lookup table would keep track of allocated lxcs for customers.
- This allowed us to test on the cloud without building real multi-tenancy.
- It allowed us to efficiently use the resources of EC2 compute instances.
We used this mechanism for a while, along with a reverse-proxy for routing requests correctly to the servers. As our customer base started scaling, we faced constraints when managing such growth with the lxc architecture. Our costs started growing, almost linearly with requests, which wasn’t sustainable. Running a service on SaaS can be profitable only if you can control your costs aggressively, and spend money only when there is substantial load on your system. With the lxc architecture there was a base cost of running each instance, as the lxc continues to run on the instance CPU even when there are no customer requests for the instance. Given how lxc works, we were restricted in turning them down, as they continued to be running processes and occupied some minimum CPU time. Since we had dedicated lxc instances for each customer, as the customer base grew, we were adding more compute instances to support them. This posed another problem - updating and restarting each lxc container on a Mingle feature update. This method would be prone to errors, be a time sink, and would also incur downtime, adversely affecting customer satisfaction.
We also had to build additional adapters to fit the lxc based architecture in the cloud:
- Reverse-proxy for routing requests for a particular customer to an appropriate lxc.
- apt-repo- a service to store and update all the instances with all the packages that include and support Mingle - Mingle server, sun jdk, linux updates, and so on.
- Our own adapters to use AWS services.
Mingle on the cloud - new and improved
We needed a better way to do things and reduce our costs while being able to scale. We started examining our approach and comparing it with technologies being launched by Amazon on AWS.
Our analysis revealed that the Mingle load currently does not exceed 30req/minute and would remain at this level for the near future. This built a clear case for multi-tenancy, as that would allow us to scale based on number of active requests (load) as opposed to provisioned customer instances. It would keep the cost constant - we could serve a large number of customers with the minimum number of compute instances - while allowing for data security and efficient usage of resources.
We have since built in multi-tenancy in Mingle’s architecture. It leverages multi-tenancy at every request and reconfigures the application for that request based on the information about the customer. Customer’s data is still isolated at the persistence level while the requests are multiplexed at the application level.
Once we implemented multi-tenancy, we were able to reduce the number of compute instances to two (to ensure redundancy and distribute load) for all the web requests we needed to handle. Having such an architecture allowed us to move the application state to persistence and identity layers, while keeping the volatile resources ignorant to state.

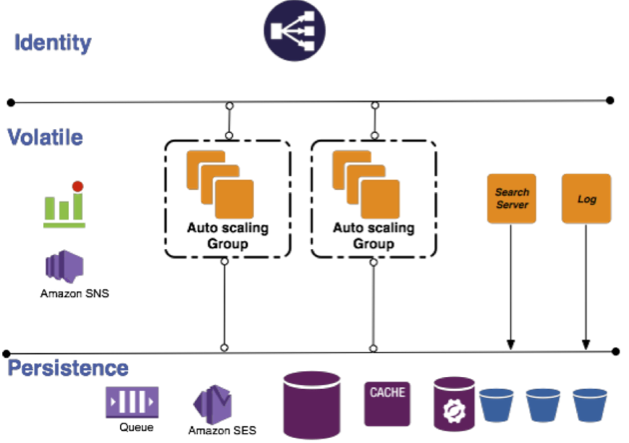
Introduction to Amazon Cloud Formation (CF)
While re-architecting, we were introduced to CF, which promised to relieve us from the pain of writing deployment code using APIs. It also ensured that we would not have to deal with ‘eventual consistency’ issues with provisioning individual services. We would have to change the way we thought about our application though. Some of our deployment code would have to be removed or repurposed to suit CF ‘s requirements.
CF allows you to define your resources and their dependencies and then proceeds to correctly provision them. CF also brought with it a set of features we were looking to build in -- autoscaling, high availability, distributing for redundancy across zones/regions, zero downtime and failsafe updates at no cost to the customer.
Amazon Machine Image(AMI)
AMIs are the recommended way of provisioning resources with CF, and a way to support continuous deployment with CF, as they ensure traceability and are packaged in a way that CF can consume. Since each AMI is identified by a unique id, we use it to tag our latest AMIs for the next deployment. All these updates are stored on Amazon Simple Storage Service (S3) that CF has access to. Our deployment process now follows a simple pattern where CF creates a stack for the new version of the application and retires the old one. This provides us with zero downtime for our web-facing server. Having configured CF stacks in such a way that the autoscaling group spans across multiple zones, we achieve automatic high availability by relying on the AWS system to do the right thing in case an application instance fails.
There are times when we might face errors during provisioning, resulting in failures. However, these errors are hidden from the end user as they are not exposed to the failed stack. The original stack continues to run and serve requests as if nothing has happened. We are notified of such failures and can do our due diligence to fix the deployment.
What’s next?
As we continue to improve our codebase and deployment process, we have been building our new features using ElasticBeanstalk. It is a tool to provision services (which can include stacks with multiple resources) with a better alignment to continuous delivery. Stay tuned for more on ElasticBeanstalk and about a tool that we built to support continuous delivery on AWS.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.