














Digital innovation
Lessons learned from life as a chatbot: Part 1


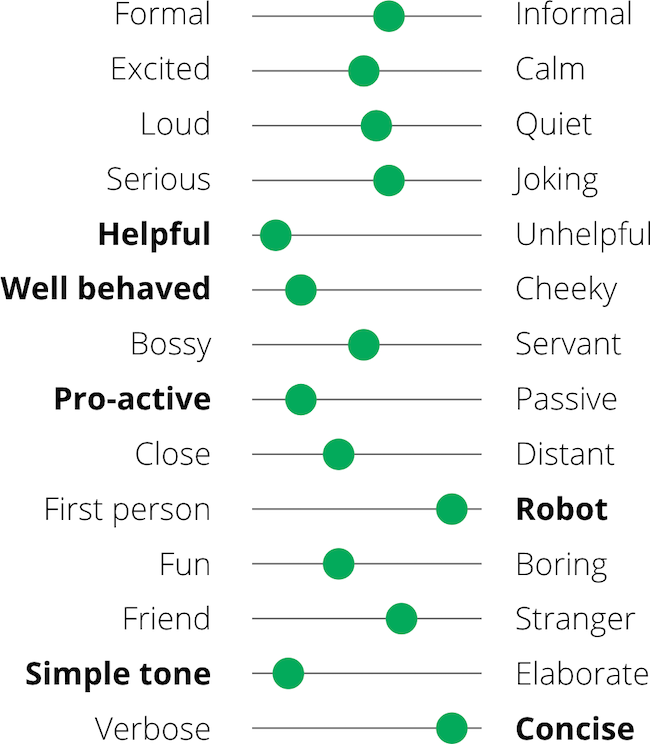

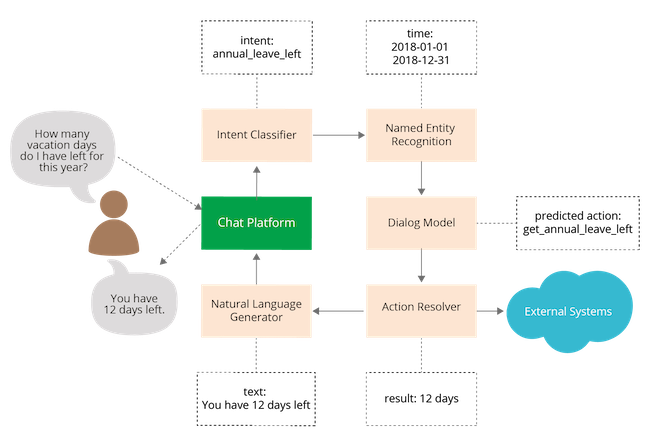

Quality Principles
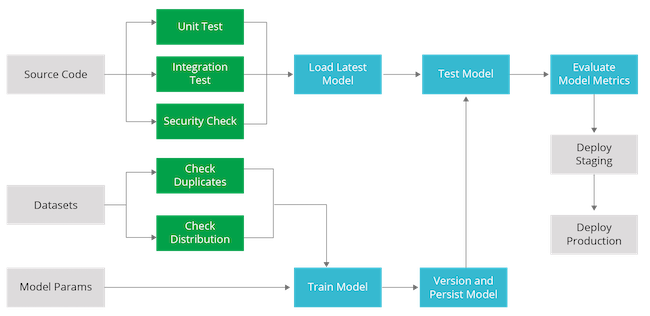
Automated Tests
Metrics for Intent Classification & Conversation Flow
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

