














Data strategy
Why are enterprises having a data quality problem and how to fix it (part one)

In the first part of this series, I discussed what data quality is, why it’s important, what causes data quality issues etc. I’d argued that the quality of data is closely intertwined with the purpose it is intended to serve. In essence, the use case is a key driver for the quality of data.
This blog explores how you can leverage that approach to solve data quality problems.
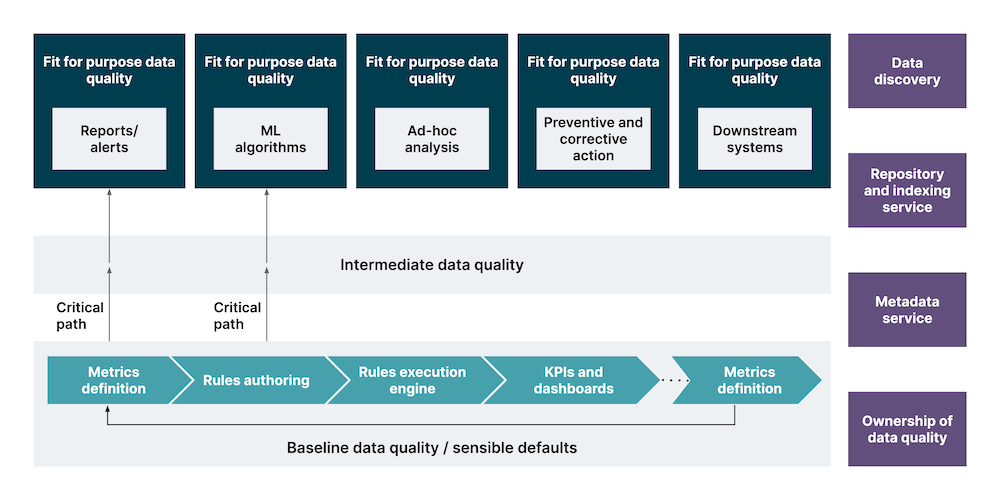
The framework we recommend is hierarchical and seen from the data users’ perspective. As you see in the diagram below, there are two dimensions to data quality here:
Baseline of data quality requirements: the framework begins with defining the baseline rules of data quality. These form the defaults, or common denominator quality rules for all use cases this data can enable. Data type validation (alphanumeric characters in numeric fields like price/sales) and data format validation (date format) are some of the examples needed irrespective of use case.
Fit-for-purpose data quality requirements: this is the quality required for the data to serve its intended purpose – you cover a critical path that includes just enough quality checks. You can start moving to other use-cases for those according to the delivery/business plan iteratively.
In most cases, the effort, time and resources required to fix all data quality issues is not justifiable given we may not even be using the data that way. So, it is important to identify the critical path. For instance, if you’re looking to use data for a retailer's pricing decisions, validating the email address of customers to check if it belongs to the correct recipeint might not be required, as that does not factor in the dynamic pricing algorithm. Please note here that the email structure or format validation is still a required data quality check and it belongs to the baseline data quality requirement.
Data quality framework
Once you’ve identified data quality rules for each layer – from the baseline data quality layer to fit for purpose data quality layer, convert them into metrics. Author the data quality rules around metric values; you can use a green, amber and red classification to highlight where you have issues. Remember that this is a continuous process and will keep evolving for a growing data platform.
Set up a rules engine (custom or OTS) to execute the rules authored you’ve authored
Connect the output from this engine to a dashboard that clearly communicates metric values and KPIs
Onboard stakeholders to the platform and enable self-service dashboards that they can use to create views that work best for them
To make this successful, you need a couple of other tools:
Data discovery mechanism: to support the identification and semantics of existing and new data into the platform. This will help navigate to the right dataset to evaluate against the right rules.
Metadata repository: repository of metadata e.g. business glossary, technical metadata, schemas, relations, lineage, indices etc.
Metadata service (to manage the repository): metadata Ingestion/updation by APIs to enable data discovery.
Ownership of data quality: however, the most important pillar is defining the ownership of data quality. This will ensure the missed quality at each layer, including the business processes.
Operationalizing data quality
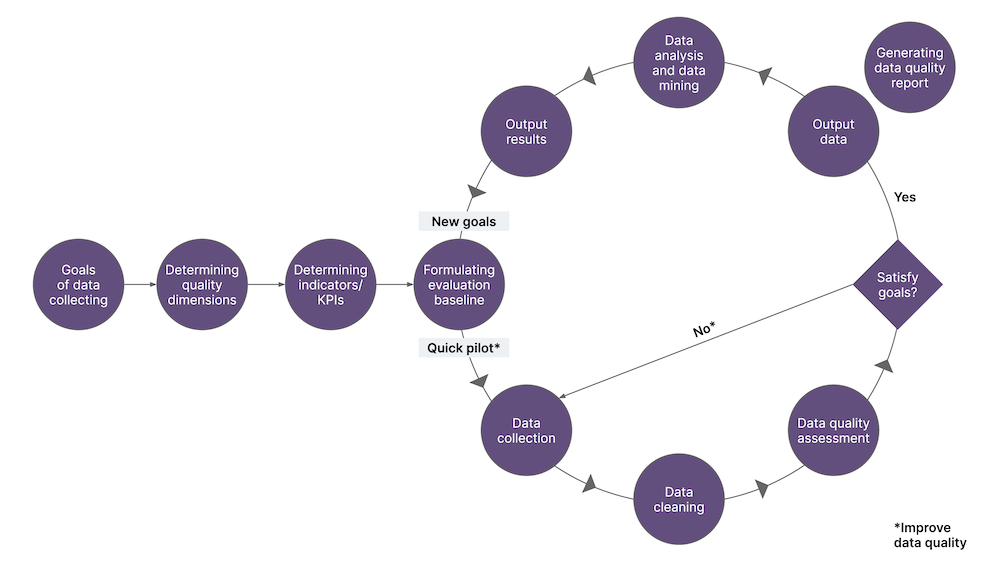
Once you have formulated your data quality framework, the next step is to operationalize it. Here’s the process we recommend.
Set goals, dimensions and indicators - this is the stepping stone for all data quality work. Begin by defining the scope, outlining business use-case, identifying stakeholders, clarifying business rules and designing business processes. Make sure you clearly communicate the objectives of the data quality initiative to all stakeholders.
Evaluate baselines and pilot - once the business rules are clearly defined and communicated, set up baselines around the rules. Use these baselines to categorize the data into different quality buckets. Then, run a pilot on the existing data to measure the current data quality. This typically results in two things:
Identifying the specific actions needed to improve the data quality
Re-thinking business processes to improve data quality over the long term
Collect and clean data - ingest and collect data. Run the quality rules on this data to separate clean data from bad data.
Assess data quality - typically, we use both quantitative and qualitative analytical techniques to do the gap analysis of where the data quality should be based on what’s defined in the first phase and where the data quality actually is.
Report data quality - build comprehensive, yet succinct dashboards that inspire proactive and reactive actions to improve data quality. Enable each group of stakeholders to customize these reports based on their needs and ownership.
Maintain - build and implement processes to maintain the data quality efforts on an ongoing basis. Leverage your organization’s data governance initiatives to make sure data quality is maintained through a sustainable program.
Have a bird’s eye view -

Pre-ETL validations
Format
Consistency
Completeness
Domain
Timeliness
Post-ETL & pre-simulation validations
Meta data
Data transformation
Data completeness
Business specific
Scope
Joins
Data copy
Simulation validations
Model validation
Implementation
Computation
Aggregation validations
Hierarchy
Data scope
Summarized values
UI validations
Representation
Format
Intuitive
In addition to each vertical fit-for-purpose data quality requirements, the framework has a horizontal dimension as well, where it runs across the entire data pipeline. As you see from the image above, each stage in the pipeline will have its own baseline data quality and fit-for-purpose data quality definitions. Ensure that your framework accommodates these requirements as well.
Data users and data providers are often from different organizations with different goals and operational procedures. This results in their notions of data quality also being very different from each other. In many cases, data providers have no clue about the use cases (some might not even care about it unless they are getting paid for the data).
This gap between the data source and data use is one of the top reasons for data quality issues. Domain data products have the potential to bridge this gap which is what we plan to explore further in the series.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

