














In Part 1 we discussed some of the reasons behind moving to a service oriented content management system, and went into some detail on how to commit an item using the Github API.
Thus far I have managed to skate over the details of how we mapped the operations the content editors wanted to perform (save, publish) to the functionality that git provides (commits, branches).
We tried several different implementations around publishing, which are explored below. The basic functionality we needed to support for editors was:
- Create and update to a draft state
- Publishing between a public and a draft state (single or multiple items)
Save as commit
When a content item is saved (updated or created) then this results in a commit in the git repository. Initially we considered allowing several content items in a commit, but this creates an additional requirement for a staging area (or local repository) where uncommitted work can be kept. In a load balanced implementation this either implies a shared staging area or sticky sessions. Furthermore you need to deal with ownership and sharing of uncommited items, so that all editors can view the most up-to-date content. Commit on save avoids this complexity.
Single user, trunk based
Having different users holds out the possibility of each user maintaining their own set of commits on a separate branch, allowing multiple simultaneous edits to a single content item. In reality long running branches hidden from other users just create merge difficulties and complexity. It's much simpler for everyone to have the same view of the content. This has a direct analogue with trunk based vs branch based development [http://paulhammant.com/2013/04/05/what-is-trunk-based-development/]. Without branching on a per user basis, we could still allow each user of the system to have their own GitHub identity; this would allow commits to be tied to users - but we can easily achieve the same effect through the commit message if needed. Ultimately, we settled on a single content service user for communicating with the GitHub repository as the simplest solution.
Branch per content state
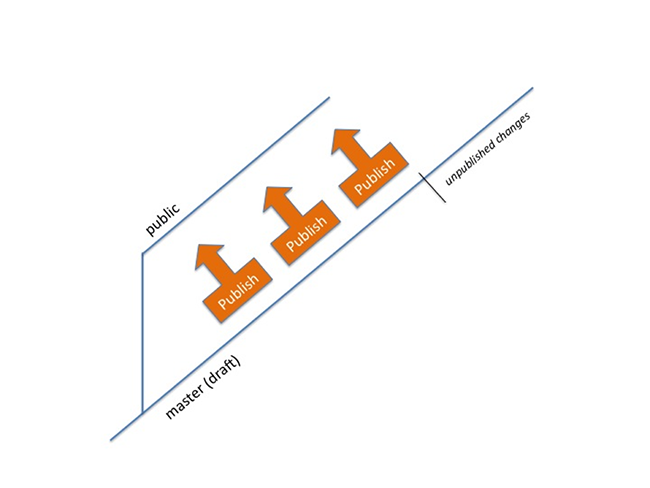
Our first attempt at mapping workflow to GitHub branches was to create one branch for each workflow state we required (in the simple case exactly two – public and draft). As changes are always applied to the draft state first, this was mapped to the git master branch. Publishing is then just a matter of merging from the master to the public branch. Public content is served from the public branch. Because all merging is one way (from master to public) there is no scope for merge conflicts.
This proved to be very simple and effective, but only allowed en-mass publishing – all changes up to and including the merged commit were published in one operation. Cherry-picking could have been used to publish single items, but this does not result in a shared history between the two branches, and over time the two branches will diverge (and could never be merged).
Branch per content item
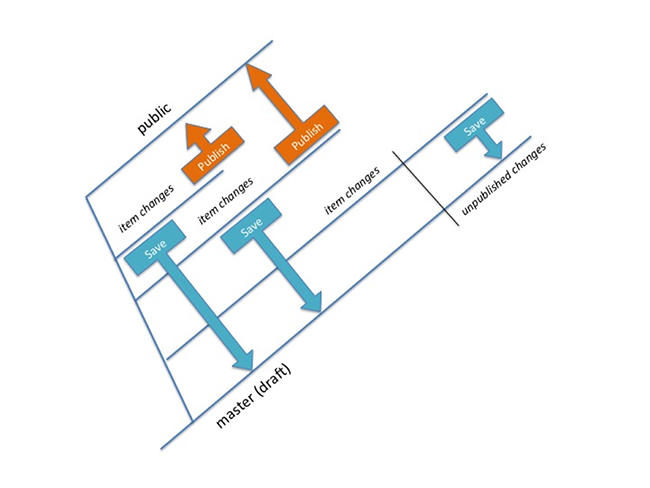
To allow more fine grained publishing we needed to move to an implementation where the changes for a single item could be distinguished from changes to other items. If we create a branch for each item with unpublished changes, then we can do this. Branches are taken from the public branch rather than master, so that unpublished changes from other items are not included in the branch. Each time an item is saved, as well as committing to the branch, the branch is merged to the master branch (so that there is a shared view of all the latest changes). When an item is published, then all changes on the branch are merged to the public branch, and the branch is deleted.
Although we were able to complete a spike of this implementation, ultimately we felt that the accidental complexity of the implementation was too great, and moved to a simpler, but less git-oriented solution.
No branching, directories modelling content state
We are storing all of our content data in files. We can move away from using git artefacts to support our implementation, and use the file system instead. By creating separate directories for each of our workflow states, publication just becomes a simple matter of copying files (from the draft folder to the public folder) and then committing to git. This greatly simplifies the implementation, but at the cost of duplicating content (which git will manage efficiently) and dividing elements of the implementation between git and the file system.
The editing front-end
The final piece of the puzzle was to implement a more user friendly interface for creating and changing content. While the developers were happy to edit and commit JSON files directly into git, other users were less inclined to do so. The editing front-end is worthy of its own insights article (and I'm hoping to persuade someone from the team to do so). In essence it is a web front-end using in-line editing and based upon the website itself; as far as possible it's like being able to just edit the web pages themselves. The editing application posts changes to the content service, which in turn updates GitHub through the GitHub API.
What about Jekyll, Octopress and Prose.io?
[http://jekyllrb.com/, http://octopress.org/, http://prose.io/]
Other content management systems based on GitHub typically use an offline page assembly model. Content is created in a markup language (like Markdown) and the commit process combines this with templates, and spits out a final website. One of the initial inspirations for our approach came from the article “How we build CMS-free websites.” [http://developmentseed.org/blog/2012/07/27/build-cms-free-websites/] Dave Cole advocates using Jekyll as part of a CMS-Free approach.
We looked carefully at these systems at the beginning of the project, and liked them, but we felt they were more suited to blogging platforms, and would need considerable work to provide editors with an easy to use interface. The offline page assembly model means that we would need a separate implementation for dynamic parts of the website, and the small steps to the final system were not clear. Overall it felt more like choosing a CMS than approaching the problem incrementally. Perhaps next time.
Finally
This article has detailed an incremental approach to developing a content managed web application, in contrast to the adoption of a CMS at the outset. While there are the costs associated with developing functionality which you could get “off the shelf,” these are offset by some of the advantage of this approach – flexibility, simplicity, control, obviating the need to learn a bespoke framework and above all being able to move in small steps from a simple static web site to a managed one.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.