














Technology strategy
Use serverless functions for microservices? Yes, but cautiously - Part 1

Application development and deployment strategies are constantly changing. While planning for a new microservices-based architecture, architects should think about a deployment strategy — choosing between a serverless function or container orchestration (such as Kubernetes , Docker Swarm , etc..) or a dedicated virtual machine (VM). Today, a one-size-fits-all solution that delivers applications both economically and at scale does not exist.
Serverless isn’t being devoid of servers. In fact, the servers exist but are managed by the cloud provider.
To call something a serverless service, it would have to follow four principles:
Servers are abstracted
Pay only for what you use
Have high availability out of box
Be able to scale on demand
One part of the serverless stack, the function-as-a-service or serverless compute, takes care of abstracting the server. You pack your applications and dependencies in a zip file or a container image and ‘give’ it to the cloud provider. They will instantiate the container and execute the function on the server — entirely event-driven. If many events are simultaneously triggered, the cloud provider auto-scales and you only pay for the executed functions.
The other part of the serverless stack is the backend-as-a-service that handles storage, eventing, orchestration, ETL, analytics, etc. Many cloud provider services have adopted a ‘pay-for-use’ pricing. For e.g. Azure Cosmos DB, a NoSql DB store now offers serverless pricing where one pays only for request units consumption (or read and write operations) and the amount of data stored.

Compute
Azure Function
AWS Lambda
Google Cloud Function

Storage
AWS S3 , Azure Blob storage
Azure Cosmos DB
AWS Dynamo DB
Google BigTable
Eventing
AWS Event Bridge
Azure EventGrid
Orchestration
AWS Step Function
Azure Logic App
ETL
Azure Data Factory
AWS Glue
Cloud Data fusion
Analytics
Azure ML Service
AWS SageMaker
Our suggestion is for architects to have a serverless mindset and use the entire serverless stack when building the solution. You will be able to access 9’s reliability at a ‘pay-as-you-go’ cost.
Every microservice should be independently deployable, scalable, monitorable and reliable. To meet these needs, you need a platform that can auto-scale, perform resource management for efficient utilization of underlying infrastructure, have an ecosystem for observability and allow various deployment strategies at optimized costs.
We compare Kubernetes and serverless on each of these factors:
Kubernetes can scale in three dimensions — increasing the number of pods, pod size and nodes in the cluster. It can scale based on server metrics like CPU and memory or custom metrics like the number of requests per second per pod.
In serverless computing, scaling happens as per the application itself. For instance, Lambda can auto-scale exponentially up to burst traffic. After that, linearly up to concurrent limits. These limits apply to all functions in a region, so care needs to be taken that the maximum concurrent instances in applications falls below the limits. The concurrency limit promotes fine grained function with small execution times.
In Kubernetes, CPU and memory requirements for service are specified at the pod level. However, in serverless, memory requirements are mentioned in the deployment manifest which implicitly decides the CPU allocation.
Most organizations use tools on top of Kubernetes clusters for collection, aggregation and visualization of logs, metrics and traces. They install these tools as operators or demon sets in the cluster. Since logs and telemetrics grow in large volume, they need storage services provisioned and managed at scale.
With serverless, the metrics are slightly different. You need to measure metrics of function with respect to the cost model. Due to the concurrency limit, you will also need to watch the number of concurrent executions and processes along with their duration. Cloud providers ensure a set of tools for end-to-end visibility of function execution and application logging observability.
Serverless observability platform

Kubernetes ‘natively’ supports rolling updates. For blue/green and canary, you need add ons. In serverless, the API gateway can ship traffic to two Lambda versions – which can be used for blue/green or canary.
When deciding between Kubernetes and serverless, it is essential to look at the total cost of ownership – including infrastructure, development and maintenance costs. While cloud providers offer discounts for reserved instances, it can be leveraged economically to deploy Kubernetes clusters, but operating costs of running clusters, manageability and observability should also be accounted for – Total Cost of Ownership (TCO).
Total cost of ownership
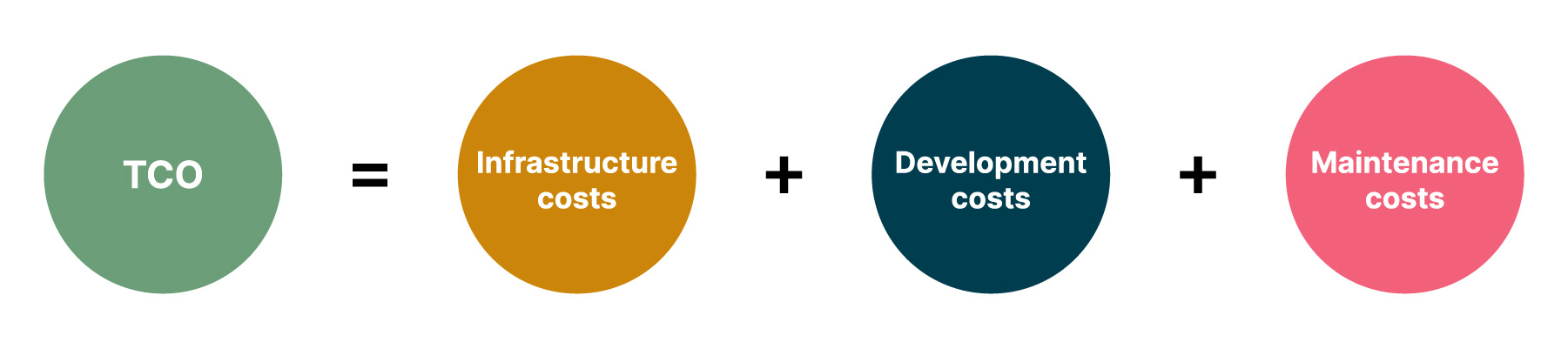
This means applications with medium and low traffic or unpredictable traffic patterns — gain considerable savings in the serverless model. For high-traffic applications with predictable load patterns, Kubernetes could cost less.
If you’re planning to move to serverless computing models for microservices-based applications, here are some pointers to help you through the decision-making process:
Standardization/vendor lock-in. There is no Cloud Native Computing Foundation (CNCF)-backed serverless codebase like there is for Kubernetes. Each provider has its own implementation and features. You will need to adapt to these differences.
Execution time. Long-running or batch processing kinds of use cases cannot run seamlessly with serverless yet. There is limited support for runtime and languages as well.
Security. There is a common misconception that as servers are abstracted, there is no multitenancy. Not always true. You will need to shell out more for dedicated servers.
Cold start. To overcome the problem of latency in serverless, cloud providers have launched pre-warmed instances. If your application is latency-sensitive, use cloud providers.
Full-stack serverless. To make the most of serverless computing, leverage it across the stack and not just compute.
Serverless modular codebase
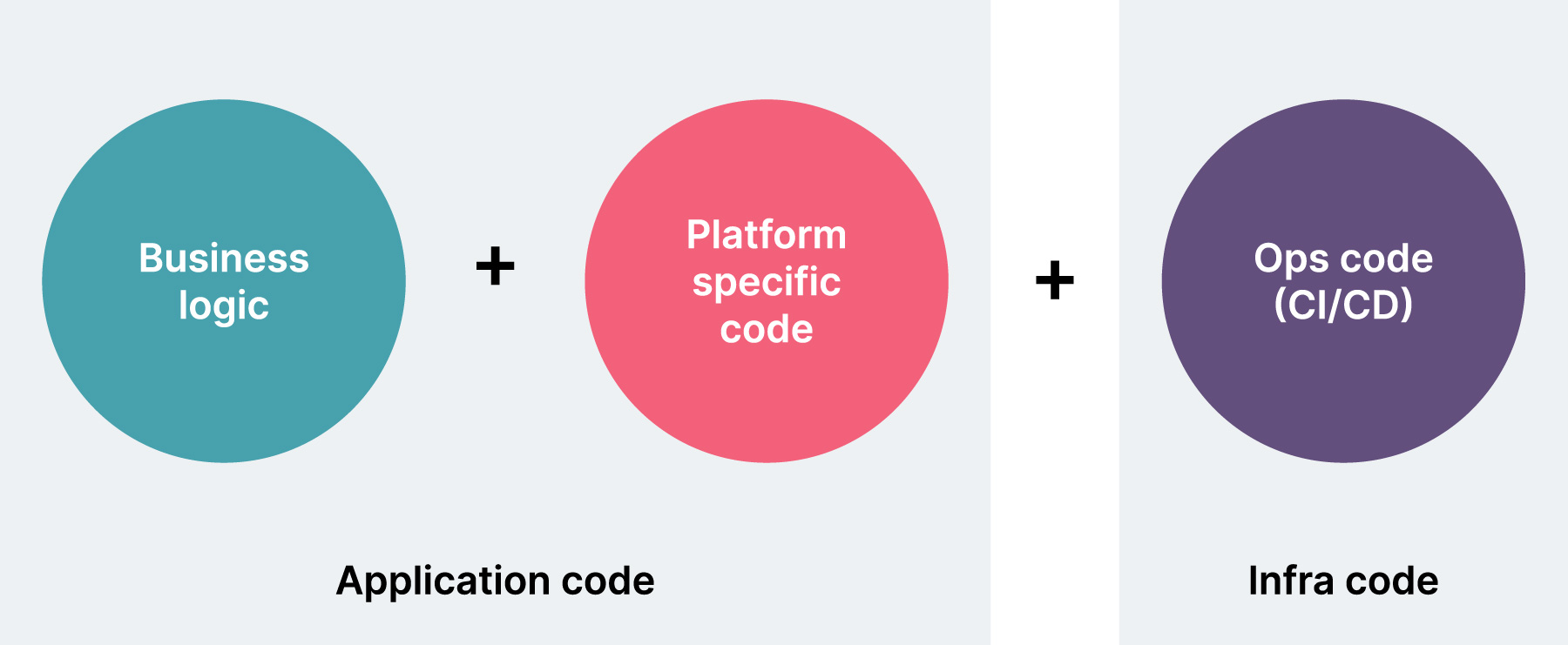
Flexible deployment models. We recommended designing your applications so that switching deployment models between serverless and container orchestrator is as economical as possible. This can be achieved by enforcing strict separation between what is dependent on the actual target platform, what is common and independent. You’ll need to enforce a neat separation between business log.
Containers are great for predictable workload, heavy traffic, high compute intensive and long batch running applications. They are proven and you should consider leveraging cloud provider managed services.
Serverless is the mindset of ‘owning less and building more.’ Serverless can offer faster time-to-market, high elasticity, availability and low entry cost. Most organizations and startups start with serverless and focus on solving customer use cases.
We recommend building using modular code patterns so that deployment models are flexible and easily change-able. Serverless are effective for event streaming, IoT data processing, chatbots and cron jobs. But they’re not the best solution for every use case.
As described above, every choice comes with a specific trade-off. The right decision depends on the goals you want to achieve. Serverless are the first steps towards No-ops.
If you would like more information on this subject, click here.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

