














A Go-Environment is a grouping of pipelines and agents. By assigning an agent to an environment, it will be used to run only those jobs that belong to the pipelines of that environment. An agent can belong to more than one environment but a pipeline can only belong to a single environment. Once an agent is associated with one or more environments, it is no longer capable of picking up jobs on pipelines that do not belong to environments. Pipelines outside of environments will only be assigned to agents in the default pool (not associated with any environment).
So what?
What does this grouping buy us? Independent of all other features, Go-environments allow us to:
- Ring-fence agents so that they are only available to certain pipelines.
- Define environment variables at the level of an environment. They become available to tasks in all pipelines associated with the environment.
- Visualize pipeline activity from the point of view of an environment.
Let’s explore each of the above in some detail. Note, however, that the overall utility of Go-environments increases significantly when used along with other features such as pipeline locking, run-on-all-agents, timer-triggers, trigger-with-options, manual stages and pipeline templates and parameters.
Ring fencing agents
Go-agents can play one of two roles. For build pipelines, they act as workers. For pipelines that are meant to do deployments, Go-agents can serve as agents of software installation/deployment/distribution.
- Let’s say we have a QA environment with 5 nodes and a performance test environment with 7 nodes. Now if we install a Go-Agent on each of our 12 nodes, then a typical deployment job will start with a fetch-artifact task and end with a deployment script that simply extracts and configures the artifact into the right set of directories. (Some would argue against having agents running on performance nodes but it doesn’t matter so much if you are interested in understanding performance variations rather than absolutes. Go-agent activity won’t vary between runs). In this configuration, Go has full knowledge of your environments and can display the most information about deployment activity. But this would also require the purchase of sufficient number of agent licenses.
- With the increasing popularity of techniques like infrastructure-as-code, we may not want to run a Go-agent in addition to a Chef or Puppet agent on every node. In this configuration, the actual environments are managed by Chef Server or Puppet Master and Go-Agents are used to orchestrate configuration runs. We set up one orchestrator Go-Agent per target environment and authorize each agent to ssh (or winRM) to its corresponding set of target environment nodes. This configuration is also effective with agentless tools like Ansible. Just install Ansible along with Go-Agent on the orchestrating nodes.
But can’t we achieve all this ring-fencing with resource tagging? Well, it can get very cumbersome. With tagging, you can say run this job on an agent with matching resources (tags). What if the job has no tags? It is then free to run on any agent. To work around this, we could attempt to assign tags to all jobs but it soon gets impractical. If you forget, the first run on the job may overwrite a deployment on some other tag-based environment. Also, this tag-every-job approach overloads the meaning of resources for the same job - one resource may stand for what software the agent is expected to have, the other stands for a logical partitioning - potentially confusing for users.
Environment Variables
You don't necessarily need Go-environments to use environment variables. These two are somewhat independent. Environment variables can be defined at environment/pipeline/stage/job level and can be dereferenced using ${env_var_name} inside a task definition. There are a bunch of predefined variables that may come in handy e.g. GO_PIPELINE_LABEL for suffixing versions to artifact names etc. Secondly, you can specify sensitive information (passwords, private keys etc) using the recently introduced secure environment variable feature available at pipeline level. By the way, doing config via environment variables is considered a good thing by 12factor. Finally, note that one pipeline cannot belong to more than one environment at a time, so what is the use of defining variables at the Go-environment level versus pipeline level? Well, doing so makes the variables available to all pipelines in a given environment.
Visualization
Here is a view of a static environment definition.

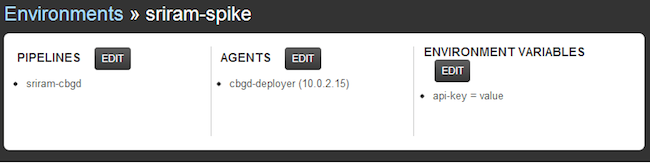
And here is a dyamic view of pipeline activity. Click compare to get a detailed listing of material changes that triggered this run.

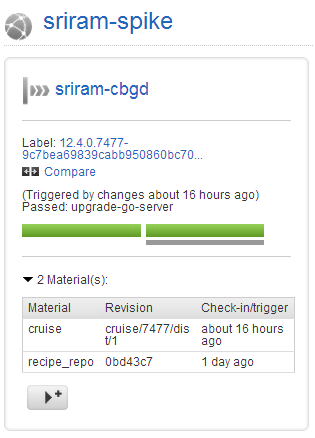
- Easily rerun jobs only on the servers that they failed on (run-on-all-agents)
- Does it seem like a particular server always takes longer to deploy? That it fails more often? Easily check with the Agent job run history tab.
- Pause an Agent to disable deployments to that node.
- Secure environment variables. You can find other ways but I think this is a good option. Works well when the person with permission to deploy (e.g.: "product owner") shouldn't have the production db password (who trusts product owners?)
In Part 5 of our series "How do I do CD with Go?", we discuss the awesome power of pipelines and paramters in modeling your CD workflow
"How do I do CD with Go?" blog series:
- Part 1: Domain model, concepts and abstractions
- Part 2: Pipelines and value streams
- Part 3: Traceability with upstream pipeline labeling
- Part 4: Go environments
- Part 5: The power of pipeline templates and parameters
See how the newly-released Go 12.4 can help you optimize your CD process.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.