














When you start on the CD journey, it is tempting to think of it only as “What tools should I use?”
While part of it is selecting the right tools for each aspect like version control, CD server, infrastructure configuration, monitoring and so on, an effective CD implementation doesn’t stop at that. For instance, you might use a particular version control tool and have a particular CI server set up, but if you are not checking-in code in small batches frequently, or don’t have automated tests, it's not really Continuous Integration.
Remember also that the goal of CD is to be able to release software frequently, and reliably, in a frictionless manner. So, while you start automating your deployment process, it is also important to identify bottlenecks in the deployment process and streamline it over time.
In this article, I am going to talk about three recurring themes in CD enablement that I have seen in my experience as a developer:
- The trouble with monolithic codebases and approaches to break it down
- Designing the test suite for optimal feedback
- Setting up a deployment pipeline as the backbone of CD
A common recurring challenge on CD is dealing with large monolithic codebases that show the following immediate symptoms:
- Sluggish build and application start-up time
- Slow feedback loop with large test suites
Up to some point, you can attack this problem by parallelizing build tasks and test runs. Build tools like Gradle, Rake, and others, support parallel task capabilities that we can take advantage of. Additionally, CI tools including Snap CI support test parallelism with multiple build workers.
But for teams working on a monolithic codebase, this is usually not enough. Apart from the aforementioned problems, a large codebase can be difficult to work with and intimidating to new members on the team. When multiple functional teams work on the same codebase, there tends to be less ownership of the code, multiple implementation patterns begin to emerge, and it gets more difficult to get consensus. Technical debt accumulates and can easily spiral out of control.
A large team working on a monolithic codebase also compounds problems on the CI front. Many teams in this situation find that their build times increase to dangerous lengths. At some point the build is slow enough that developers think twice about running the full test suite locally before checking in. With so many people checking in changes at the same time, the feedback cycle slows down. This, in turn, makes it tricky to diagnose build failures. Broken builds get left for someone else to fix, like dirty dishes in a sink waiting for “someone” to clean them
A large monolithic app can also be a significant overhead on your deployment throughput. Cycle times are longer because of the slower builds and automated and manual tests required to validate the entire app. This creates a lot of friction in the pipeline.
There are examples of teams that have optimized their deployments for the monolith—Etsy, for instance, has written about its experiences with Continuous Development. However, it is worth noting that Etsy has also invested significant time building the custom tooling and infrastructure to support the approach.
In short, with a monolith, it becomes increasingly hard to manage technical debt, encourage good engineering practices, and deploy.
Extract components
We can address the issues with the monolith by decomposing the codebase into smaller components such as libraries or services.
Componentization via Libraries
For a start, shared components (like a pagination UI component or a library to make database or API calls) can be extracted and added as binary dependencies on the application.
But when there are multiple functional teams working on the same repo, the biggest payoff comes when you can separate out each team’s work into components to be managed in their own repos.
One large-scale Open Source project doing this is the OpenMRS application, where independent modules are wired up together in the application runtime. A component in this case is a binary dependency that includes end-to-end functionality of a module including the UI. Deployment of a component can be managed on the deployment pipeline and means upgrading the component version on the parent application.
On a recent project where we saw the pains of a large team working on a monolithic content management system (CMS) codebase in Java, we started to break out components under active development into separate repos. For example, the search functionality was separated out. Then, everything related to search - from UI to backend code - could be developed on a much smaller codebase. The binary artifact, in this case a JAR file, could then be plugged in as a runtime dependency on the application. We then had a small test suite on the main application build pipeline to validate that the component worked well within the application boundaries.
Separating out the component enabled the Search feature team to focus on their parts of the code. In addition, the test suite on the new repo was smaller and directly related to what the team was working on, so as a result there was better ownership of the code and better management of technical debt. Further, the savings on the short feedback loop for both application development and on CI were enormous.
Componentization via Services
Depending on the situation, breaking down the monolith app into a composition of smaller runtime services can provide enormous leverage in terms of the autonomy it affords to the team, given that apart from service boundary or API, everything else is completely de-coupled from each other. A standalone service can be deployed independently and scaled appropriately based on its requirements. The Building Microservices book by Sam Newman is an excellent read on the subject.
But of course, microservices are not a free lunch and your team or organization needs to be tall enough to use them effectively.
When used appropriately, the microservice approach can help drastically reduce cycle times and simplify the deployment pipeline.
However, by either approach, componentization can be a multi-month effort with no quick wins. In addition, the separation boundaries between components need to be thought through before implementation. But that said, the payoffs in terms of CD impact will more than make up for the time spent setting it up.
When you start on a greenfield project, automated GUI tests or acceptance tests seem small and manageable and it is tempting to add as much coverage on that layer as possible. But unless tended to, these tests grow become unmanageable over time. [The ice cream cone anti-pattern for test suites is well described in this article.]
Indeed, teams that are saddled with a large number of acceptance tests end up getting slowed down by the very automation that was supposed to make the application delivery process easier and faster – tests taking many hours to run and producing random failures in the end. Acceptance tests also tend to be brittle and because they are harder to reproduce and fix, these tend to accumulate over time. In many instances, the quality starts being gauged in terms of the percentage of passed tests. “85% pass. Not bad compared to previous run!” This doesn’t say anything about the quality of the application.
Therefore, it is advisable to design your test suite to give just the necessary validation with acceptance tests and everything else covered by unit tests and a smaller layer of integration tests. Unit tests are fast to execute, give the right level of feedback about what is broken. As you go up the pyramid, the tests are slower and it becomes harder to point out root cause of failures because the surface area is larger.

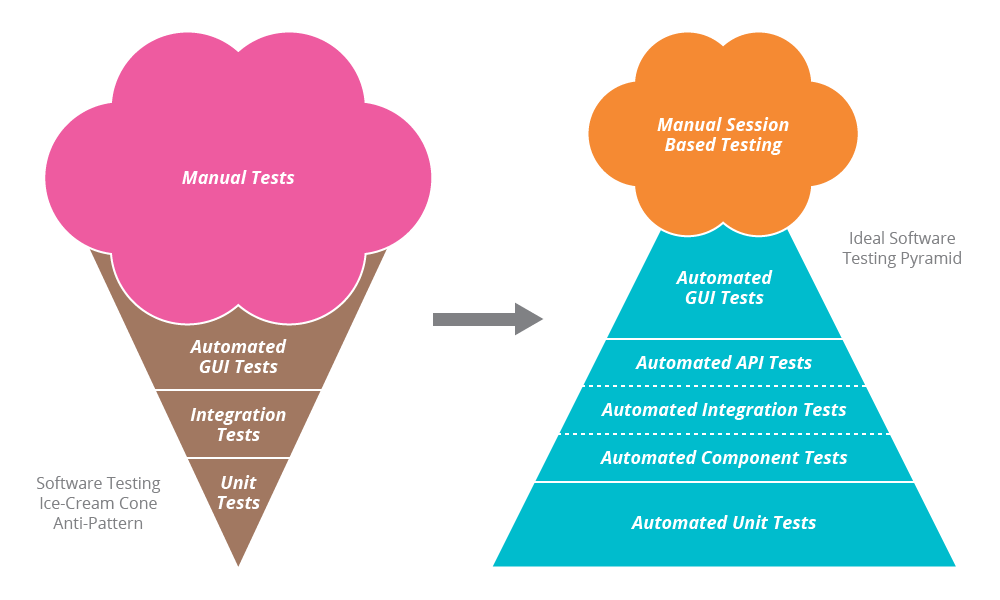
(Adapted from watirmelon blog)
On a recent project - a single page application on AngularJS talking to a backend API - we knew we had to test the UI layer because there was a lot of conditional logic, formatting, etc. embedded within the UI on AngularJS view templates. But instead of settling with a heavyweight Selenium or a Protractor test suite that would have been prohibitive given the number of test cases we had, a team member developed a tool called Duck-Angular which could validate AngularJS rendered DOM and simulate DOM interactions using JS tests in-memory. Read more about it here.
With that tool, we could write as many UI validation tests as needed as unit tests. In the end, we had comprehensive coverage, with more than 1000 tests that ran in a few seconds.
Another project had hundreds of functional tests which were so slow and flaky that they were ignored. We were able to dedicate a couple of weeks as a team exclusively towards replacing acceptance tests with unit and integration level tests and that effort set the impetus to prune the test suite to the desired state.
The deployment pipeline concept in CD is a huge step change in the the way we build and release software.
CI is essential but not sufficient for an effective application delivery workflow
Automating the deployment procedure is the first step and most CI tools like Jenkins or TeamCity do a good job of providing that capability. For example, you can set up build configurations for each phase – say a build phase or a unit test phase, acceptance tests – and also automate deployments to each environment.
While this is certainly useful, the trouble is that it is very difficult to answer the question: “Do we have confidence to release this version of software to Production?”
Because deployment process is spread across disconnected build configurations, it is difficult to visualize the entire production flow process and this additionally ends up hiding inefficiencies in the process.
This is where the deployment pipeline helps.

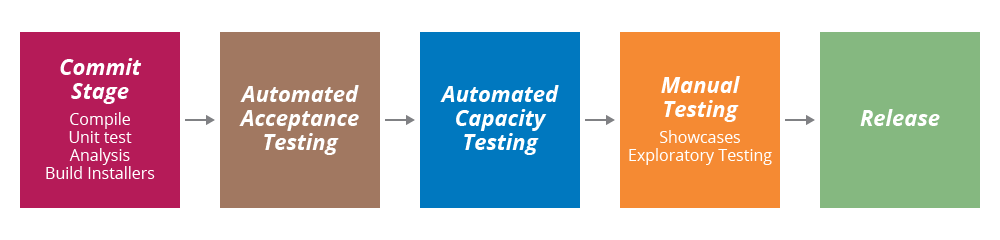
(Source: Continuous Delivery book)
I am constantly amazed by how much this idea of the pipeline is similar and inspired from non-software manufacturing workflows like Lean manufacturing.
In High Output Management, Andy Grove talks about modeling the production process and constantly optimizing the steps to achieve better throughput.
The deployment pipeline in essence represents a flow chart of your production process and enables you to automate and visualize your deployment process from source repo all the way to production. Each step of your build and deployment process can be modeled into the pipeline to provide high resolution visibility into your deployment workflow.
Below is the view of a simple pipeline on Snap CI:

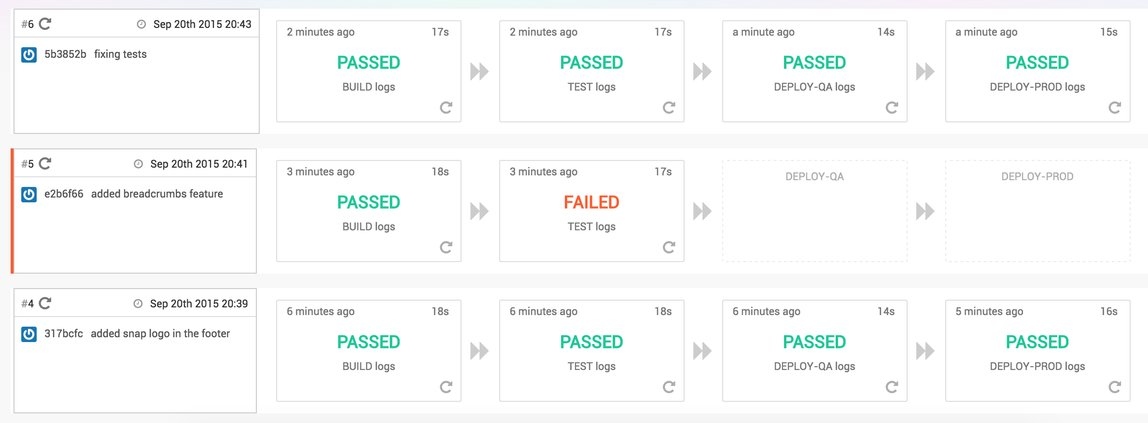
Each commit goes through a series of stages that lead all the way to production. With each passing stage, you get higher confidence with that revision of the code. If something fails, the pipeline stops and you have to fix the build OR revert the commit that caused the failure. If the deploy to production fails, you can rollback by triggering the last successful “Deploy to Production” stage.
With this level of visibility, you can not only determine whether the application is releasable any point, but also identify the bottlenecks in your process and set yourself in a position to continuously improve the process over time.
The pipeline abstraction can also support complex build and deploy configurations including component dependencies.

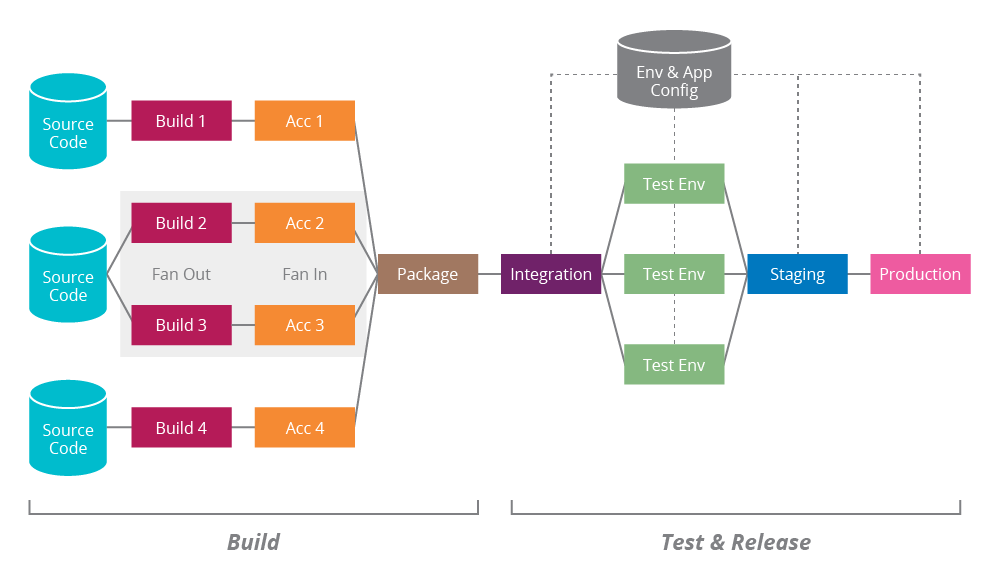
Above is the value stream map of all the dependencies involved on a deployment workflow down to production from the Go.CD website. It displays the state of each commit, and the dependencies of the application that need to be packaged. It provides the end-to-end visualization to production which indicates the confidence whether the application is releasable at any point.
You can see that the deployment pipeline can also easily support requirements like integration testing microservice dependencies and has the flexibility to support best practices like trunk-based development.
Thus, the deployment pipeline is the backbone that provides the right primitives for an effective CD implementation.
Summary
Continuous Delivery is not just about automating deployments. The goal is to be able to release software reliably and without friction. Architectural choices play a huge role in achieving that state. Adopting the deployment pipeline to model your entire process can provide the visibility required to address gaps sooner rather than later.
This article was originally published on Snap CI's The Pipeline blog.
Snap CI and Go.CD are both products from Thoughtworks. Snap CI is the hosted CI/CD service for repo based pipelines that have the essential capabilities for small teams working on cloud. Go.CD is an on-premise tool that supports complex pipeline dependencies that is useful for large teams and enterprises.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.