














I have done 3 projects in a row where we did not use story points and simply counted stories. I’m a big advocate of that approach. Let me explain why.
I'm an estimation geek who loves the nuances of estimation, and have used function points, use case points, COCOMO, and story points for over 10 years. Over time, I’ve become convinced that the more we estimate past the very initial point, the less accurate we get. Additionally, long-drawn, “scientific” estimation exercises generate wrong expectations of certainty.
Does this sound familiar?
PM: Your original scope was 100 points, but now it went up to 130 points, so you have to cut 30 to deliver the release in the original timeline.
Sponsor: But the scope is the same. We have exactly the same 30 stories from when we started!
PM: Yes, but 100 points from then turned into 130, because we now know more about the complexity.
Sponsor: But it is the same scope and business objective. We haven't changed it! Hmm...I can't see how that story is a 5-pointer, it looks like a 3. Let’s review all the estimates...
We all know how this story plays. Business feels tricked by our "bloating" of points (and in their perspective, not of the scope.)
On the last 3 projects, I measured average days/point and the standard deviation of same-sized stories (chart below). I found the spread to be very similar to calculating average days/story and its standard deviation. Using points did not give us more predictability. On comparing burnup charts of the sum of points and story count, I get exactly the same insights in terms of progress.

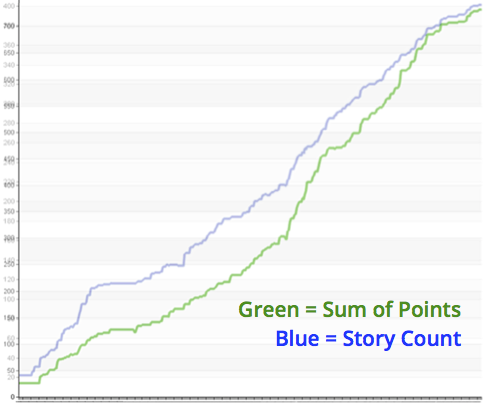
Burnup over 1 year (6 releases)
I now prefer to have a different conversation with clients using these two ways:
- Define release scope not in terms of stories but in terms of features we're delivering and their business objectives.
Points represent 3 types of scope:- Feature/function
- Richness/usability/depth
- Technical complexity
However clients generally only consider the first one and get confused when we say “scope increased” due to the other two types, as their business objective has not changed.
- Discuss scope in terms of projected number of stories we think we can do (forget points) and put rules around the maximum duration of a story.
For example, the team should not pick any story that they think will take more than <max> days to complete. So if the “scope” (any of the 3 types) increases , the story can be split and the last one in the queue might fall out.
Not only are these conversations easier, but they also get people focused on simplifying the last two aspects of scope that don't “directly” contribute to the business objective, so they can actually get more of "their scope" (features/functions) in. And we don't get into (endless) discussions about points and sizing stories.
In Summary:
I do think that there is an evolving progression in a team’s approach to estimation:
- Estimate in effort (days, weeks etc.).
- Estimate in points (use case / story points etc.).
- Estimate by counting stories/cards. To ease the transition, I generally say, "Let's assume all stories are 3 points and split those that aren't", and multiply every story by 3. This helps to drive right behavior towards smaller, similar-sized work packages that give you more flow.
- Forget estimates and simply work on continuous flow, focusing on cycle time.
Now, to get to each stage there must be some stakeholder buy-in. I have had honest conversations to the tone of "We can game the points all day long, but that won't get your business outcomes delivered, so what would you rather do?” Sometimes the answer has been that they can't help it and still want to fight points, so fight points we do until we can change it.
FAQs:
Q: I like cycle time and features as metrics. But how do you handle that (often long) period before the former stabilizes?
There is no magic bullet. (Projected) velocity or (projected) cycle time can help you take a call as to how much you can deliver in a certain time.
- If stories are diverse in size, I do the usual total points scope calculation and simulate 2-3 iterations with the Devs, asking how many stories they think they can complete; then infer velocity from there.
- If stories vary less in size, I count the stories and ask Devs how long (Dev cycle time) it would take them to develop them. I then infer available capacity by multiplying number of available pairs (discounting capacity for tech tasks) by time available and dividing by guessed cycle time. This gives me how many stories can be completed, (need to factor in critical path/dependencies). This is also useful as a second (different) way to validate velocity.
Regardless, I always ask the client the amount of risk they see in the scope/complexity. What is their current understanding of the stories and unknown scope? How many points/stories/scope buffer do they want to add? My general rule is 0-10% is unrealistic, 20-30% is manageable, and >30% if everything is very experimental. As they give me the number and I just give a recommendation, I find it easier to have conversations later when unknowns unfold (to number of stories or points).
When planning the release I do it at epic/feature level linked to a business outcome, and then split it into stories, asking if every derived story really does contribute to it.
Thus story culling happens more naturally. When things stabilize, I have a conversation about flow and cycle time.
Q: Everyone's advice is to have all of your stories roughly the same size but I generally see a huge spread. Have you achieved that, or are you saying it doesn't matter?
To an extent I've found that it doesn't matter. I've found that the spread goes from 0.33 day/point to 3 days/point, as the final stories tend to get easier (more certainty) than their size in points indicate. This huge spread makes me think that from a scope management perspective there is no value in discussing points, as I get roughly the same data with a count (graph on Pg 12). Without generating wrong expectations about our certainty.
If someone is really wedded to points I just say, "Multiply each story by 3 points (I anchor estimates around the “average” 3 pointer story) and the difference will come in the wash". This has worked just as fine (or as badly) as if I discussed the difference between 2 and 3 points. Also, I don't allow stories>8 points (or that the team says would take >5 days to complete) in the backlog, as that size seems to indicate amount of risk rather than complexity.
To me the value of an estimation session is to align the team around scope, solution, risk and complexity as different people discuss estimating the same story with different sizes in points; not from the actual number that comes out at the end.
How do you estimate on your project?
Check out other insightful perspectives on estimation in this ebook.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.