














Generative AI
Generative ref-AI-ctoring: Solving tech debt in the age of AI

As organizations transition from experimenting with conversational AI chatbots to deploying autonomous AI agents, a critical bottleneck has emerged: context.
While large language models (LLMs) possess vast world knowledge, they’re blind to the inner workings of your business. They do not know your engineering standards, your specific domain boundaries, or how your internal systems integrate.
To bridge this gap, organizations must build an AI knowledge fabric. This is not just another database or a static wiki; it’s a highly curated, dynamically updated and agent-optimized semantic layer that serves as the single source of truth for your AI workforce.
In the age of AI, traditional knowledge management systems (like Confluence or SharePoint) fall short. Over time, these platforms inevitably become clogged with conversational clutter, obsolete documentation, and redundant files. If you point an AI agent directly at these unstructured data silos, you encounter three immediate failures:
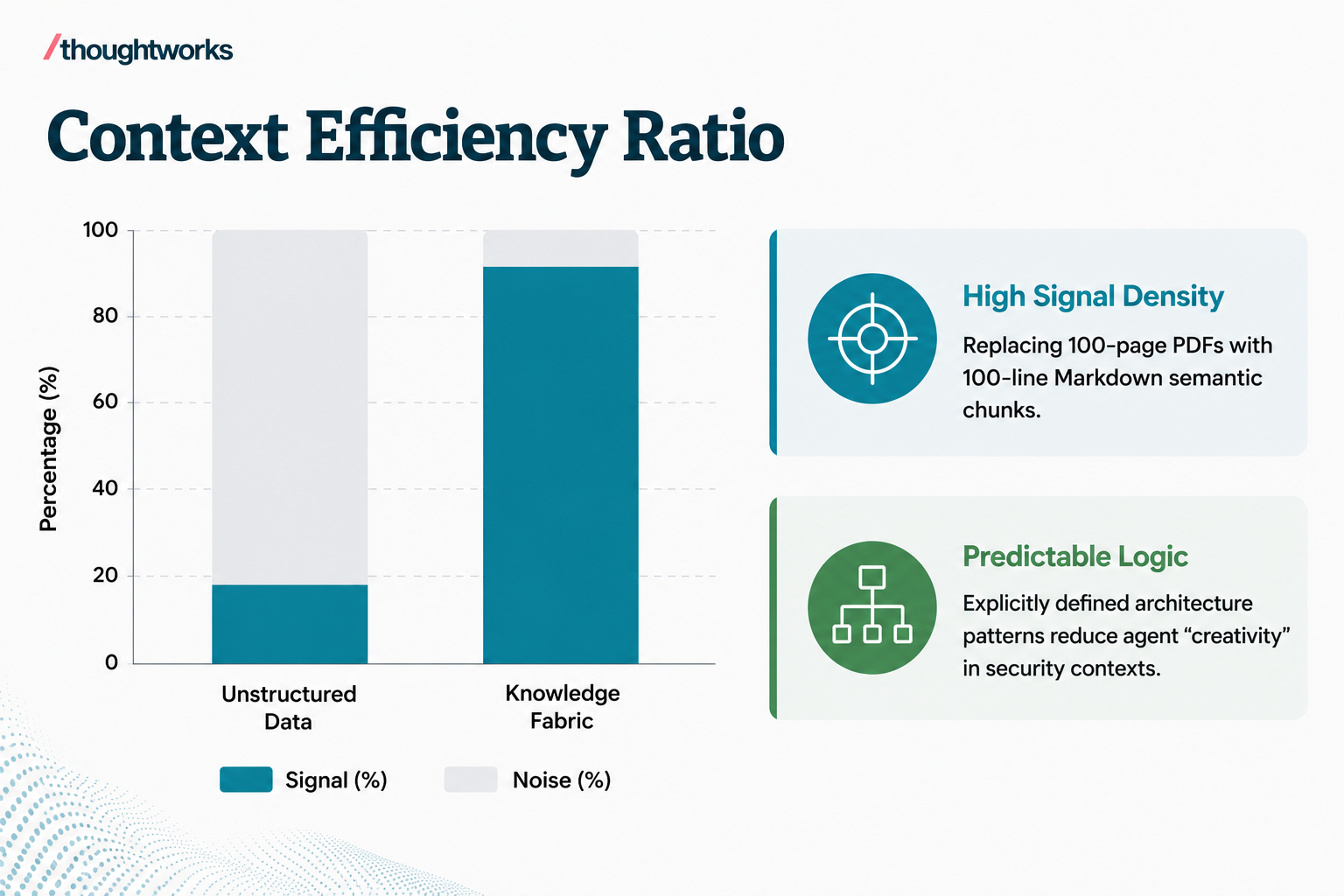
The hallucination and alignment trap: Without specific, rigid guidelines, AI agents fall back on generic public training data. This leads them to suggest outdated libraries, insecure integration methods or architecture patterns that violate security policies.
Context overload and latency: Feeding raw, massive documents into an LLM's context window degrades performance, increases API latency and dramatically raises operational costs. AI needs high-signal, low-noise information.
Decentralized tribal knowledge: Every organization has "tribal knowledge" — undocumented engineering decisions, custom API quirks and domain insights locked in the minds of veteran employees. An AI knowledge fabric distributes this knowledge, turning implicit wisdom into explicit, actionable guidelines for both human engineers and AI agents.
By structuring your organizational intelligence into a structured ‘fabric,’ you provide AI agents with the exact context they need to generate production-ready code, answer domain-specific questions and automate complex workflows safely.
An effective AI knowledge fabric consists of three distinct layers. Each serves a specific purpose, from global industry domains to individual system schemas.
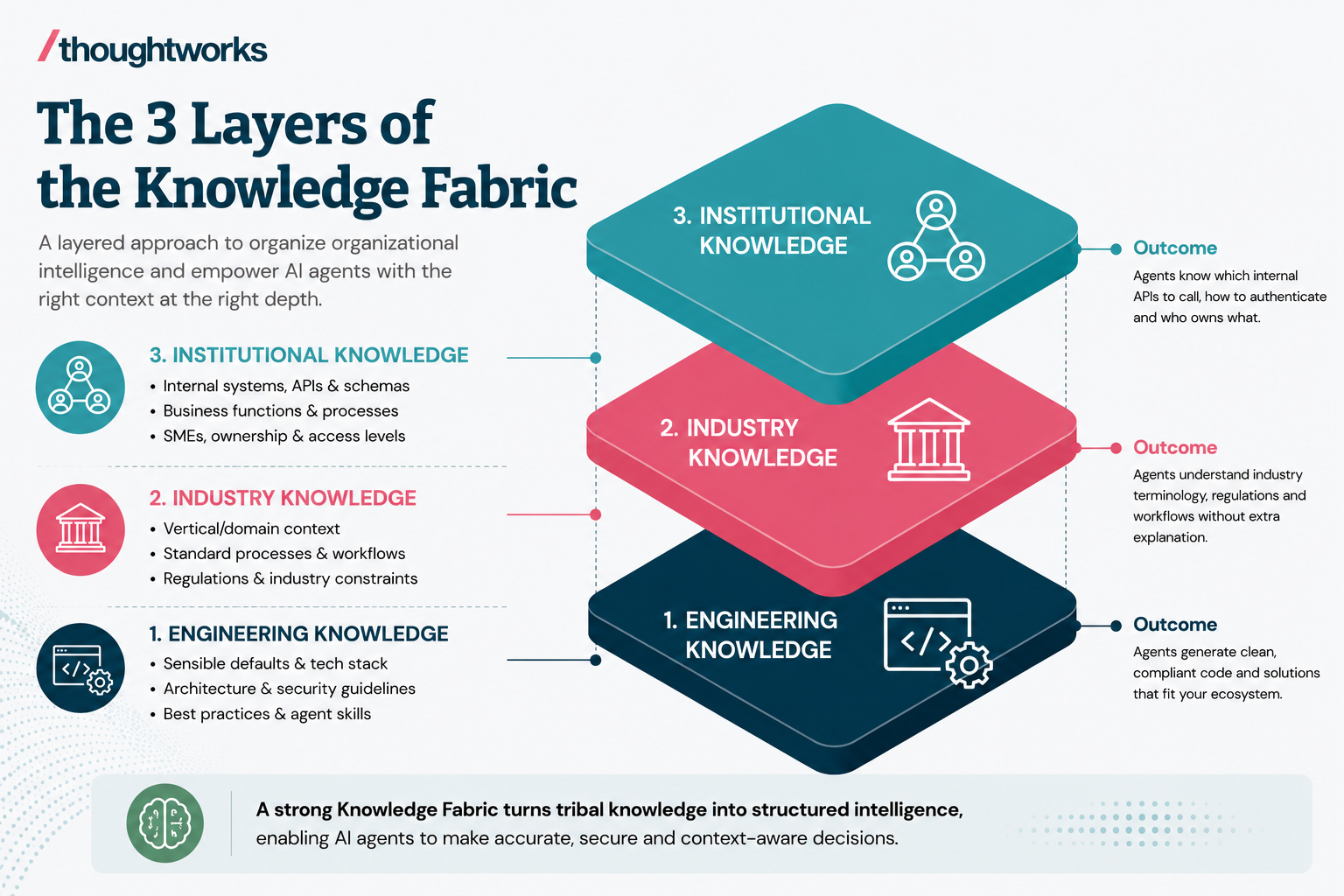
This layer defines your technical stack and sensible defaults. Instead of letting an AI agent choose how to write code, this layer establishes strict architectural guards, best practices and integration approaches packaged as agent skills or knowledge packs.
Sensible defaults: For example, defining Java with Spring Boot for microservices, React for frontend web apps, Redis for caching, MongoDB and PostgreSQL for databases and AWS for infrastructure.
Architecture and security guidelines: Pre-defined rules for OAuth2 implementation, exception handling, logging standards, and API rate-limiting.
Outcome: When an agent is tasked with building a new microservice, it automatically uses these constraints to generate clean, compliant code that fits perfectly into your ecosystem.
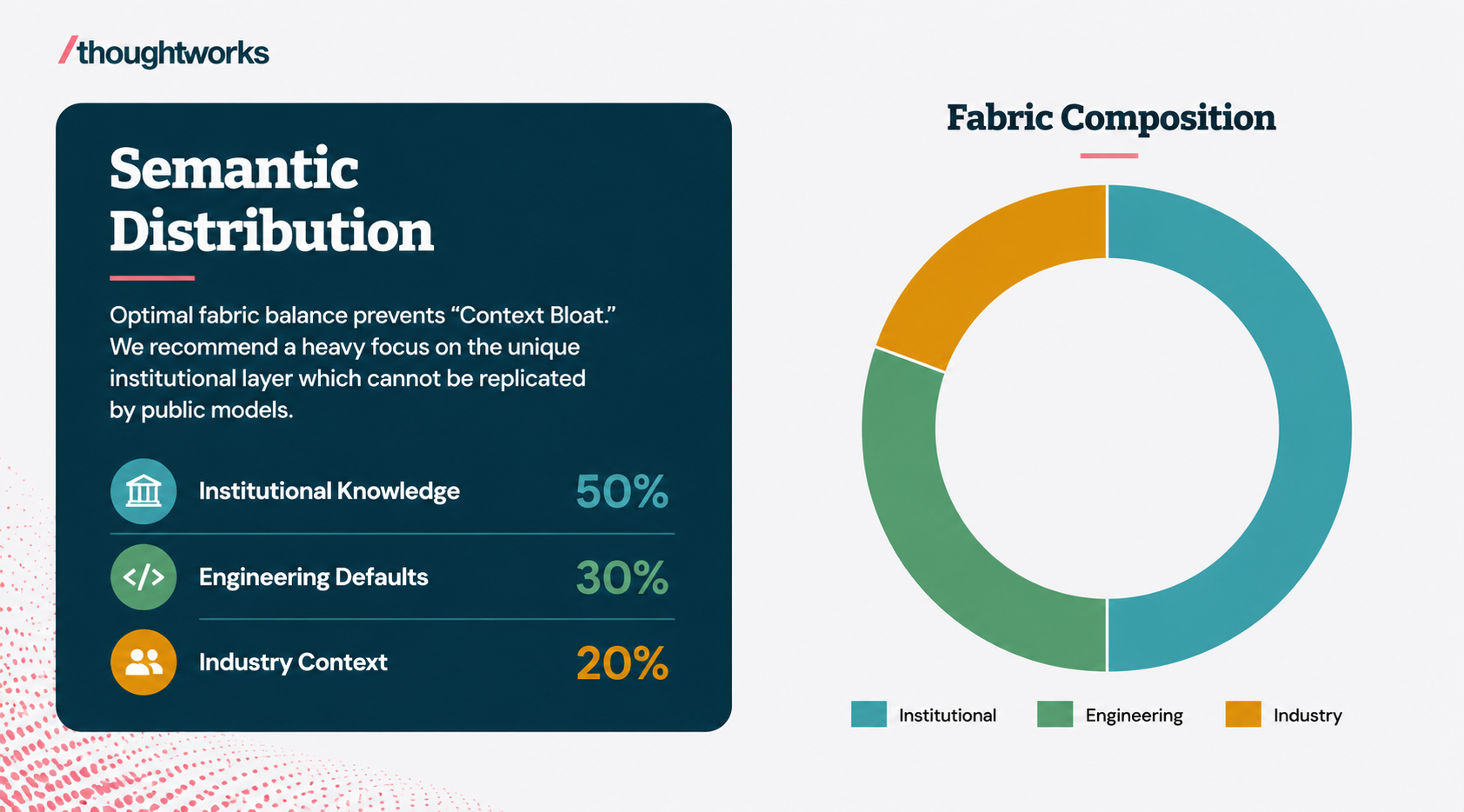
This layer captures the macro-level domain knowledge specific to your business vertical. The key here is strict scoping; you must keep it relevant only to your organization’s operating boundaries to prevent context bloat.
Vertical context: For instance, defining standard processes in banking (KYC, payments, lending), Insurance (claims processing, underwriting), retail (inventory turnover, supply chain), or aviation (flight scheduling, safety regulations).
Outcome: The AI agent understands the baseline terminology, regulatory constraints and industry-standard workflows without needing them explained in every prompt.
This is the most dynamic and hyper-local layer. It captures the unique operational blueprint of your specific organization, mapping functional business logic to technical execution.
Functional knowledge: Product specifications, organizational structure, lines of business (LOBs), and internal subject matter experts (SMEs).
Technical and operational knowledge: API specifications (OpenAPI/Swagger schemas), available system registries, security access levels and internal integration patterns.
Outcome: If an agent needs to fetch customer data, this layer tells it which internal API to call, how to authenticate, and which team owns that specific microservice.
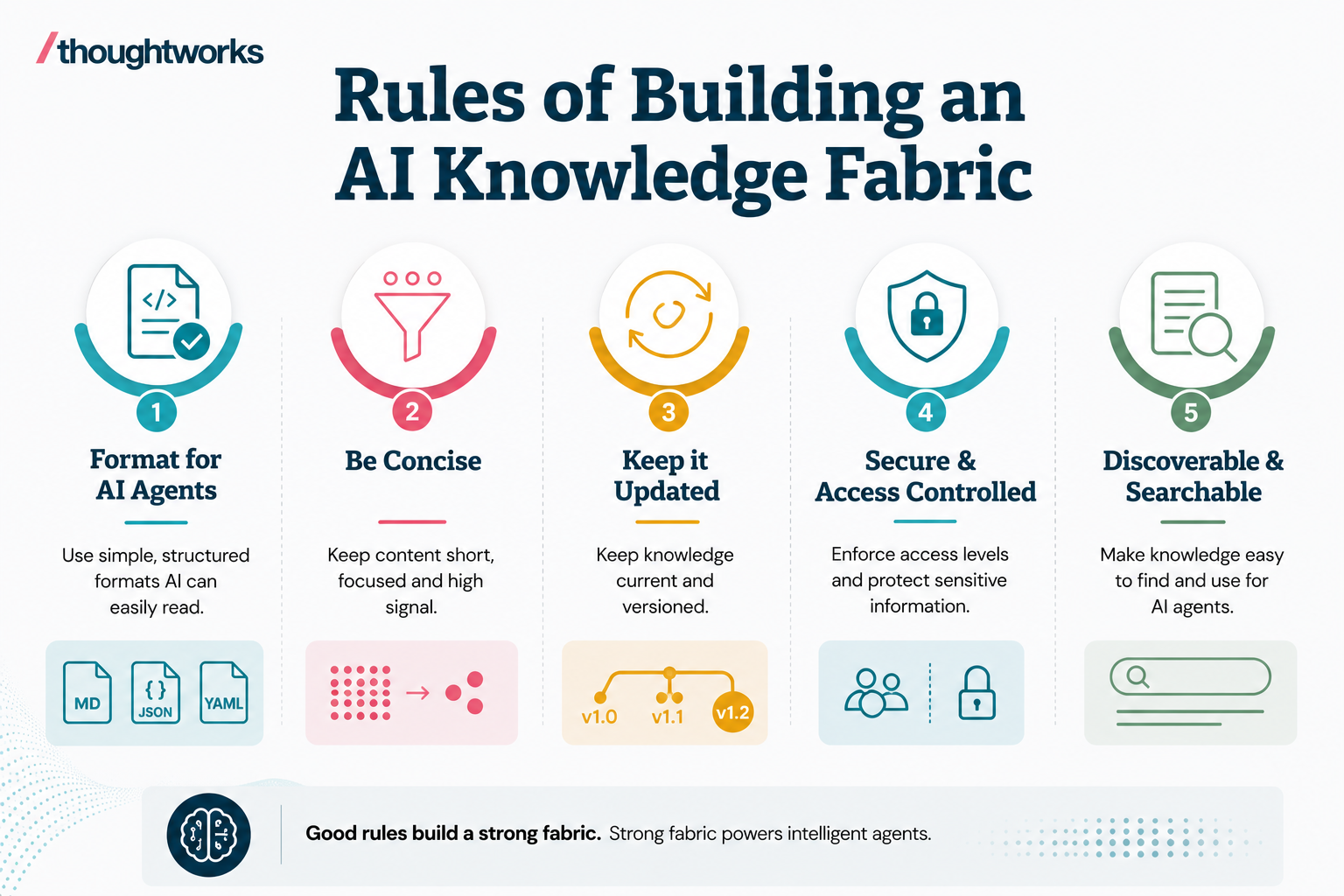
Building a knowledge fabric isn’t a one-time documentation project; it’s an ongoing engineering discipline. To ensure AI agents can consume and act on this fabric effectively, follow these key design principles:
AI agents consume information differently than humans. They struggle with PDFs containing multi-column tables or complex diagrams.
Use agent-friendly formats: Standardize on clean Markdown (.md), JSON/YAML for schemas and structured semantic chunks.
Keep formatting highly consistent so parsing utilities and vector databases can easily index the files.
Leverage Google’s Open Knowledge Format or Andrej Karpathy LLM-wiki.
Do not dump entire archives into your fabric. Large contexts degrade the quality of LLM reasoning and increase token consumption.
Write short, declarative, punchy statements.
Replace verbose explanations with concrete code snippets, schema definitions or clear logical constraints.
With layered context delivery, enable a streamlined discovery phase for autonomous agents, subsequently fetching granular data on an as-needed basis.
Implement comprehensive resource tagging to ensure autonomous agents dynamically fetch the precise knowledge context on an as-needed basis.
A knowledge fabric is only as good as its freshness. Static wikis die because they get out of date.
Set up automated pipeline triggers: e.g., when an engineer updates an API in production, the OpenAPI schema in the institutional knowledge fabric should update automatically.
Implement daily scheduled syncs or CI/CD pipelines to rebuild and reindex vector stores whenever knowledge source files change.
Just like code, knowledge must have owners.
Establish clear accountability for different sections of the fabric. The security team owns the security guidelines; the lead architects own the engineering defaults; the product managers own the functional specifications.
Establish a review process for updates to ensure the AI's source of truth remains accurate.
AI agents benefit immensely from knowing what not to do.
Explicitly document antipatterns. For example, "Never use inline SQL queries; always use ORM parameterization." or "Do not use legacy REST endpoints for New Payments; use the Kafka event stream instead."
Giving agents clear boundaries dramatically reduces the chance of logical errors or security vulnerabilities.
An AI knowledge fabric is the foundational infrastructure that turns generic AI models into highly specialized, hyper-efficient digital teammates. By organizing your engineering guardrails, domain contexts and unique institutional APIs into a structured, agent-friendly architecture, you unlock the true potential of enterprise AI automation.
A well-engineered AI knowledge fabric unlocks material enterprise advantages: first, enhanced cost efficiency with token consumption dropping by X%; second, accelerated velocity as time-to-answer decreases by X seconds; and third, elevated trust with organizational guideline compliance sustained at X%.
Begin by starting small: define your engineering "sensible defaults" first, package them for your agents and watch how quickly your development lifecycle accelerates.

