














Generative AI
Generative AI: Headwind or tailwind for product development?

(100% written by humans.)
Earlier in 2023, Samsung severely limited its employees' use of ChatGPT. Somewhat innocently, employees were using it to check their work, but in doing so they inadvertently shared sensitive corporate information. This could be competitively damaging — ChatGPT could hypothetically generate answers for a competitor based on those inputs. In another case, unwitting lawyers used fake reference legal cases invented out of thin air by ChatGPT in a civil suit. They were fined several thousand dollars. The lawyers thought they were using a search engine; they claimed they did not understand it was a generative tool.
Despite these stories, there are nevertheless examples of how ChatGPT can be used effectively. One of the most notable is within customer service, where it has the potential to improve the way customer inquiries are handled. One documented case study from a major e-commerce company used ChatGPT-4 chatbots for customer inquiries: the project led to a 40% reduction in response time and a 30% increase in customer satisfaction.
ChatGPT, Bard and Chinchilla may not be household names yet, but they likely will be very soon. Businesses are investigating Generative AI (sometimes referred to as GenAI) and artificially intelligent chatbots, such as ChatGPT, in two distinct ways. First, it is being used to secure investment from venture funds, private equity and R&D funds within large companies. Second, it’s being used in business processes to improve products and unlock increased operational efficiency. However, unless GenAI tools can be trusted, they will struggle to gain widespread adoption — they will likely remain experimental curiosities situated in R&D teams and labs.
It might seem premature to worry about trust when there is already so much interest in the opportunities GenAI can offer. However, it needs to be recognized that there’s also an opportunity cost — inaccuracy and misuse could be disastrous in ways organizations can’t easily anticipate.
Up until now, digital technology has been traditionally viewed as being trustworthy in the sense that it is seen as being deterministic. An Excel formula, for example, will be executed in the same manner 100% percent of the time, leading to a predictable, consistent outcome. Even when the outcome yields an error — due to implementation issues, changes in the context in which it has been deployed, or even bugs and faults — there is nevertheless a sense that technology should work in a certain way. In the case of Gen AI, however, things are different; even the most optimistic hype acknowledges that it can be unpredictable, and its output is often unexpected. Trust in consistency seems to be less important than excitement at the sheer range of possibilities Gen AI can deliver, seemingly in an instant.
We need to take trust seriously when it comes to Gen AI. Addressing this issue can have a significant global benefit. For example, one system called ‘Jugalbandi’ (meaning entwined twins) was used as the basis for a GenAI chatbot helps Indian citizens access, learn and apply for government website social programs (written in English) in their own language. It impressed Microsoft CEO Satya Nadella so much that he said it is unlocking a “sense of empowerment… in every corner of the [globe].”
There are three main technology-driven trust issues with GenAI:
Hallucinations — when the system outputs false or inaccurate responses
Privacy — the system’s learning process cannot distinguish between public and private information, and there is a risk of sharing an organization's private information outside.
Ethical malfeasance — GenAI systems can generate harmful instructions or biased content
GenAI, in a category called Limited Memory AI, also known as large language models (LLMs), are fed training natural language data sets and create statistical knowledge from this training data or new data it is exposed to. Its probabilistic machine-learning engine then generates its answers to questions or prompts. As a probabilistic system, it will not produce identical results from identical questions. This can be a very productive outcome — the creativeness of its output makes it useful. And this shouldn’t be an issue provided its outputs are true, not plagiarized and socially acceptable.
As mentioned above, Thoughtworks recently deployed an LLM solution to create an authoritative chatbot that provides information on government programs to users in their native language. Because accuracy was particularly important in this context, Thoughtworks explicitly created an architecture to manage and correct potential hallucinations and inaccuracies, to ensure the outputs are trustworthy and reliable. Let's see how it was done.
At their core, LLMs are designed to generate text that's almost indistinguishable from what a human might write. This makes them incredibly powerful tools for creating digital products and services that can interact with people in a more human manner.
However, hallucinations undermine the usefulness of LLMs by sometimes producing inaccurate information. The use case or business process that the LLM is used within is also an important factor in mitigating this risk — is there a human in the loop reviewing the output before it ultimately reaches an end user, or is the GenAI’s output immediately presented to an end user/consumer?
First, let's tackle how information fed to a GenAI system can contribute to inaccurate responses.
The information generated by LLMs has two sources:
Parametric knowledge is what an LLM has learned during pre-training from datasets like Common Crawl and Wikipedia. Trustworthy information can also be inserted into the LLM’s input prompt. The chances of hallucinations are much greater if we rely exclusively on parametric knowledge. This is because the source of this information may not be trustworthy, or it can be outdated. However, if we ask an LLM to use the information in the input prompt to create answers, the chances of hallucinations reduce drastically. This method is popularly known as Retriever Augmented Generation (RAG). However, the amount of information you can insert into a prompt is typically restricted by GenAI restriction called the “maximum context length” of the LLM. The maximum context length typically varies from 4k tokens (roughly six pages of single-spaced text) to 32k tokens (roughly 50 pages). So it is important to select the proper information to be inserted into the LLM input prompt so that user questions can be answered with that information.
The diagram below shows what we’ve termed our "PostRAG" reference architecture for LLM-powered conversational apps, which augments LLMs with authentic information. We believe it’s an authoritative solution to tackling GenAI hallucinations. (Note that decisions like which LLM to use and where to host the LLM are outside the scope of this architecture description.)
It has six layers: the UI layer, the conversation handling layer, the data privacy layer, the data acquisition planning layer, the LLM Augmentation layer and, finally, the LLM layer.
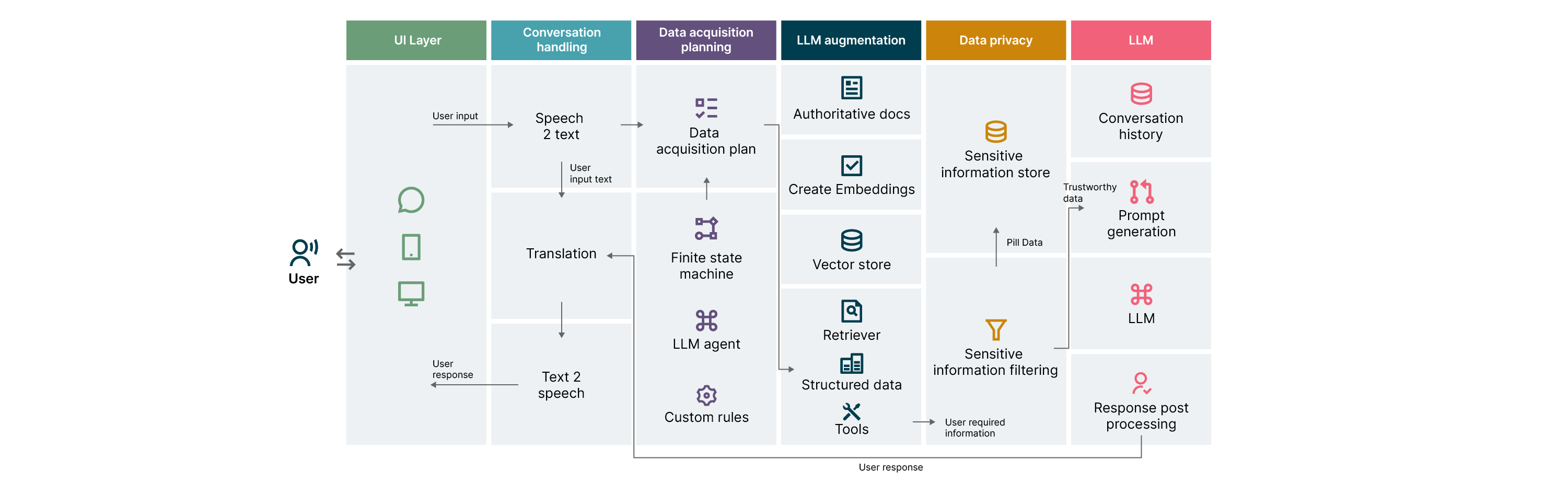
Let’s take a look at each of these layers in more detail.
The user interface component can be integrated with social media platforms, mobile apps or websites. This interface is needed to handle the voice, text or video inputs made by the user and will subsequently present its response to the user.
This layer deals with activities like converting speech to text, translating input text and converting text responses back to speech. The choice of translation depends on things like the language of the authoritative docs and the languages that the app supports.
The data acquisition planner module plays a particularly important part in reducing hallucinations. The planner does this by using the domain context (keywords) present in the user’s input to discretionarily identify the relevant data sources — documents, databases, search engines, and APIs — that are authoritative, useful, and accurate for the rest of the system to formulate an effective response.
In other words, the main tasks of data acquisition planning are deciding which data sources should be queried, in what order, and the relevant query parameters for each. Hallucination risk is mitigated by telling the LLM only to use these queried, accurate source data references in the Prompt input to the LLM. The hallucination risk is also mitigated by the instructions contained in Prompt input.
This planning module could be designed in multiple ways. One is to implement a finite-state machine as the main design of the planner so it can track the state of the conversation with a user and perform state transitions based on user input and conversation history. As the conversation progresses, the state machine-based planner would discretionarily identify or select different data sources for the rest of the LLM system to use. Recently, LLM agents such as ReAct and OpenAI function calling have shown promising results in selecting external sources — like APIs — and synthesizing the results for use by an LLM to generate user responses.
Our LLM Augmentation layer is responsible for data acquisition based on the data acquisition plan. If the source data is in the form of free text, it can be indexed into a vector store using text embedding techniques.
A semantic search can be done using user inputs. The similarity between a user input (q) and a passage from source data (p) is calculated by taking the dot product of the two embeddings. These embedding vectors could be created using models like OpenAI embeddings:
sim(p,q) ∝ EQ(q)TEP(p)
If the data source is a structured database, it can be queried using SQL queries generated by the data acquisition planning layer. External data can be acquired using the APIs of search engines.
Next, the data received after running the data acquisition plan is sent to the LLM within the Prompt input to generate a final user response. This ensures we are augmenting the LLM prompt with trustworthy information.
It’s often important that sensitive information doesn’t leave the confines of an organization. This is why boundary data redaction is required before it is sent to cloud-hosted LLMs. Alternatively, such sensitive information can be masked and stored in a sensitive information store to log and keep track of the masking. Note that if the LLM is hosted privately, masking and logging may not be needed.
A LLM’s trustworthy prompt is generated by combining the task instructions (the user’s prompt), trustworthy data and previous user/LLM conversation history. The growing conversation history and data source decisions made by the Planner help form the temporary knowledge boundaries or corpus of specific topics using trustworthy information, that constrains the scope of the conversation leading to trustworthy output responses. The response obtained from the LLM using this prompt is then post-processed to generate a user response.
This section describes the architecture of the Jugalbandi bot that Thoughtworks helped to develop. As noted earlier, it provides Indian citizens with information about government's assistance programs; the tool makes it easy for citizens speaking many different languages to access the same information.
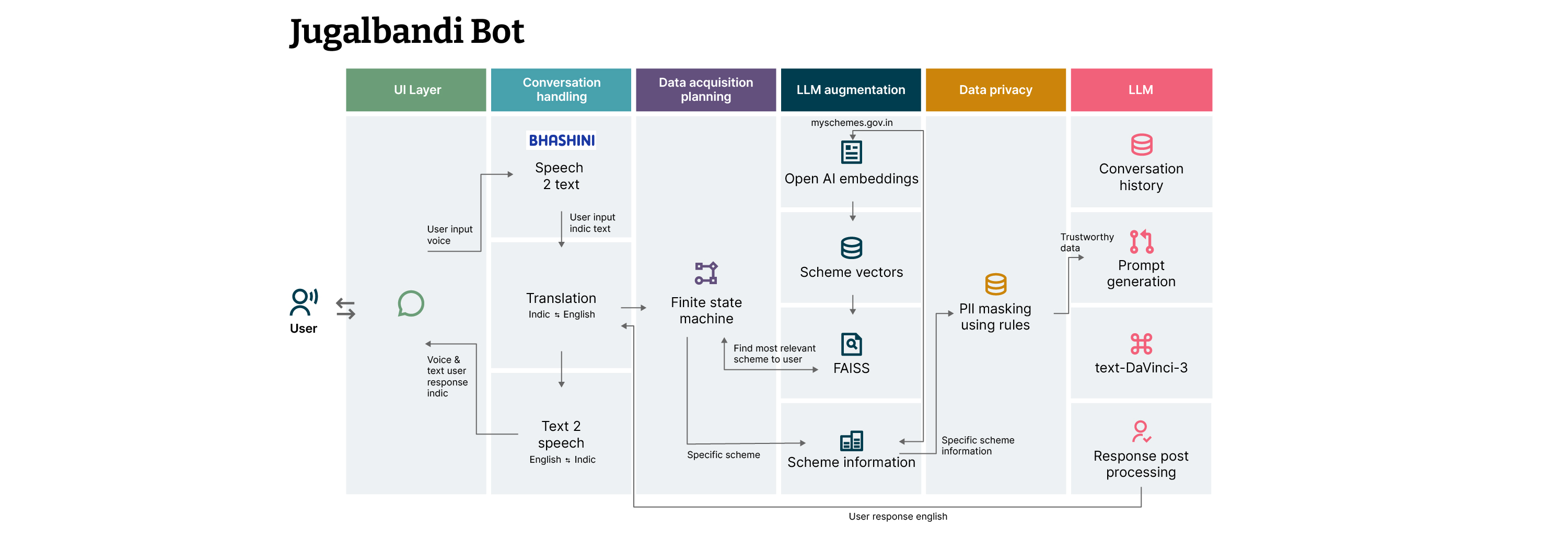
The UI layer chosen is WhatsApp, India's most commonly used social media platform. Since the source information about the government social programs is in English, all the natural language processing is done in English. User queries are converted from speech to text and translated from an Indic language to English. The conversion is performed by Bhashini, the Indian National Public Digital Platform for languages.
Custom rules were used to mask personally identifiable information (PII) in the data privacy layer. The data acquisition plan was created using a finite-state machine. Based on the user query, it creates a plan to search the vector database of government social programs and find the most suitable program for a user's requirement. (More software details about the user state machine can be found here.)
All the information about government social programs was scraped from its official website and converted into vectors using OpenAI embeddings. These government social programs vectors are searched with a user query using an open library for efficient similarity search and clustering of dense vectors called FAISS. Search results are then shown to the user, and the user can select a specific government social program they are interested in. In conclusion, LLM augmentation is done using search and government social program information.
The trustworthy information received from the search or government social programs database is then inserted into the LLM prompt. The conversation history is also inserted into the prompt. The LLM response obtained using this prompt is then sent to the user after post-processing. The text response is converted to audio, and both text and voice responses are shown to the user.
The Jugalbandi system was deployed on the Google cloud, utilizing container-based development so we could run our application on multiple endpoints on a larger scale. It uses Google Looker for BI for dashboarding, taking advantage of its modeling language to create a governed, shareable library of metrics. Lastly Google CloudSQL is used for storage and data persistence.
Data Privacy concerns are handled by the data privacy layer. Organizations' sensitive information could come from users' inputs or during the LLM augmentation process. It may be necessary to mask sensitive information before sending prompts to a cloud-hosted LLM. This can be achieved using a set of rules and/or training custom information redaction models.
Most business conversation apps need to restrict user conversations around a few areas of interest; they won’t be able to provide answers to every query. Drawing the knowledge boundaries for LLMs using its prompts on input to constrain it to trustworthy data drastically reduces the chances of creating harmful content. Parsing, pruning, and cutting down the LLM’s output answers to eliminate ethically challenged content and prose produced by the LLM is an additional tactic to draw boundaries.
The three main trust issues we identified — hallucinations, privacy and conversational performance — are serious enough to warrant a GenAI system that has been designed to mitigate and possibly eliminate their risks. PostRAG, as we discussed, does. Reputational damage not only to the promise of GenAI but also to a company’s brand will become likely if the systems you develop or GenAI products you acquire have not been built in a way that addresses each one of the risks. There’s no advantage in pursuing the ROI that GenAI promises if it only reverses customer satisfaction scores, increases losses, and leads to brand damage.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

