














Microservices
Domain modeling by Algebraic Data Types (part 1)

DDD (Domain Driven Design) is a well-established approach to designing software that ensures that domain experts and developers work together effectively to create high-quality software.
This article introduces how to apply FP (Functional Programming) to implement DDD both elegantly and concisely.
In the C4 model, software architecture diagrams consist of four levels: “System Context”, “Container”, “Component” and “Code.”
“Component” is the basic unit of how a Container is made up, it is also the level described in this article.
As applications grow in complexity, one way to manage that complexity is to break up the application according to its responsibilities or concerns. Layered architecture is an approach that follows this principle and can help keep a growing codebase organized so that developers can easily find where a certain functionality is implemented.
In Layered architecture, the code is split horizontally into different layers, with each layer encapsulated through OO (Object Oriented) design. The request is entered from the top, the code is executed from top to bottom, and the output comes from the top layer.
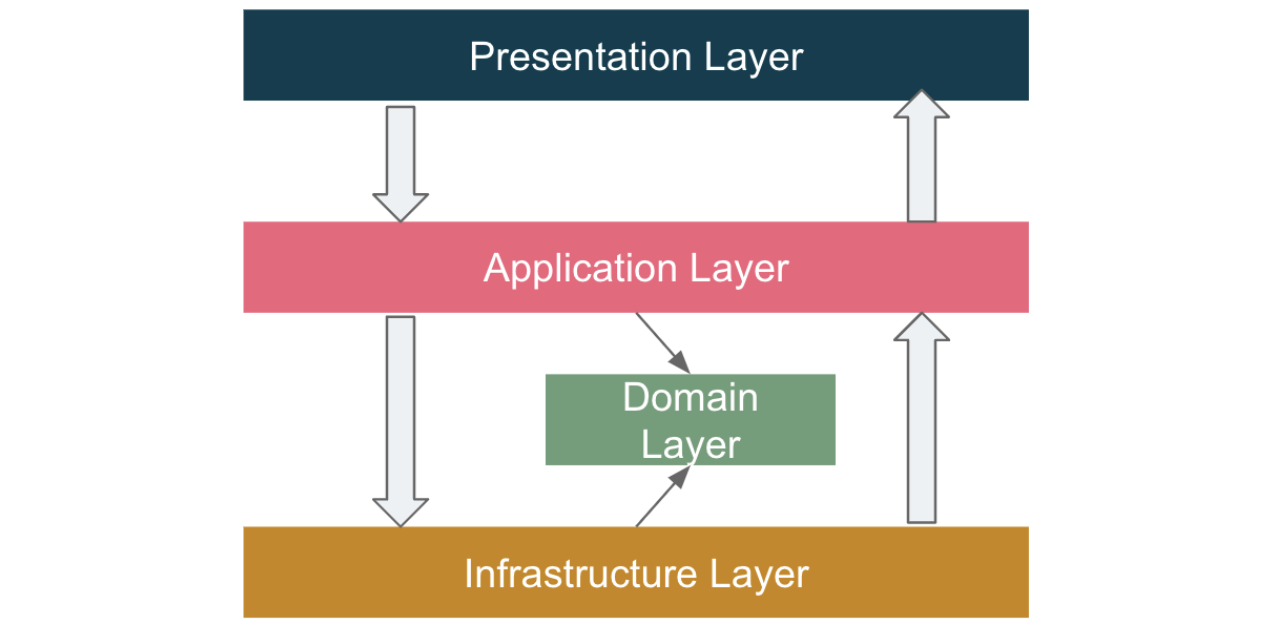
One of the problems of this design is that multiple layers not only separate concerns but also separate the context of the same business function to different places, which means that when modifying the same business function, it may be necessary to modify multiple layers at the same time.
Another problem with this design is that the presentation and application layers are usually designed as facade patterns, which can easily become God objects, which is considered an anti-pattern.
The nature of FP is composition. FP is more geared towards organizing code vertically rather than splitting code horizontally. Several functions required for the one business function (typically an API) are vertically combined as a function pipeline through Monad.
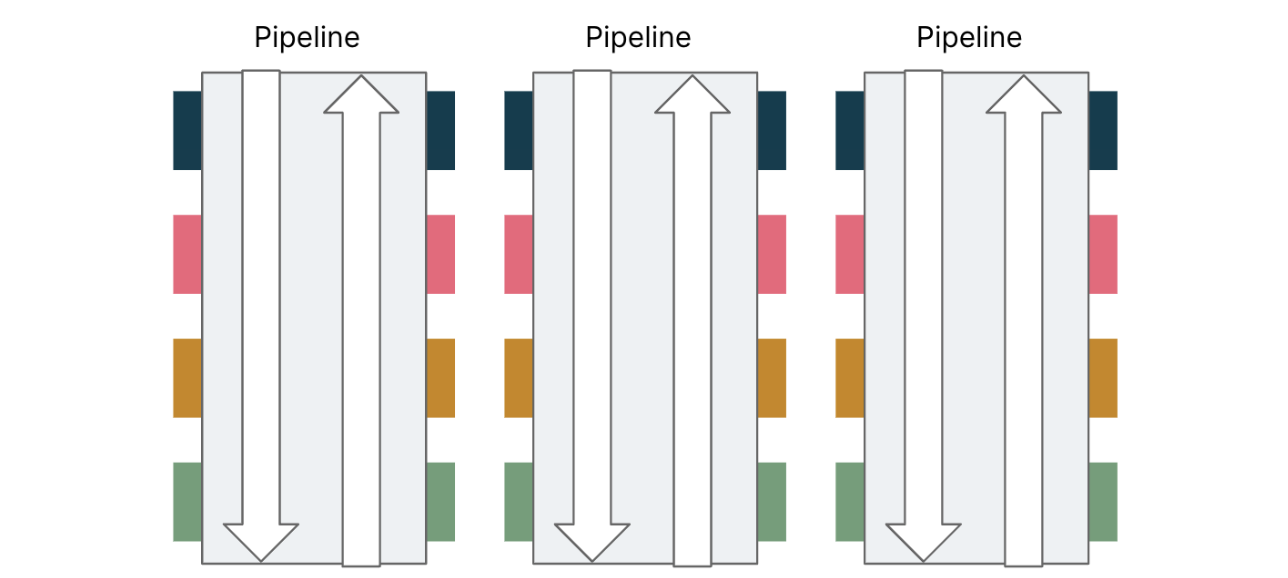
In the real world, the boundaries between problem domains are blurred. Bounded context is the artificial projection of a real-world problem in a computer system.
The world outside the boundaries cannot be trusted, as it includes various inputs from the user. And the world inside the boundaries is a trusted, legitimate, shared domain model.

This requires us to introduce validation and transformation at the boundary of the bounded context, thereby preventing external input and verifying the output to the outside.
Common validation and transformation such as:
Transfer input data as domain model
Verify the validity of the input data, e.g. ensuring the user name and email aren’t empty
Output checker, to prevent sensitive information such as user passwords from being included in the output data
Applicative is often used in FP to validate and transform input to the domain model. Once the input data breaks through the trust boundary, you don't have to worry about whether the user name is empty or the email format is correct. You should focus on using ADTs for domain modeling and handle business rules through pure functions.
Business models can be modeled as transitions between different states. You can always model your domain as a state machine by union types (sum type). Another benefit is that in FP, pattern matching forces you to deal with each branch of the union types to avoid missing cases.
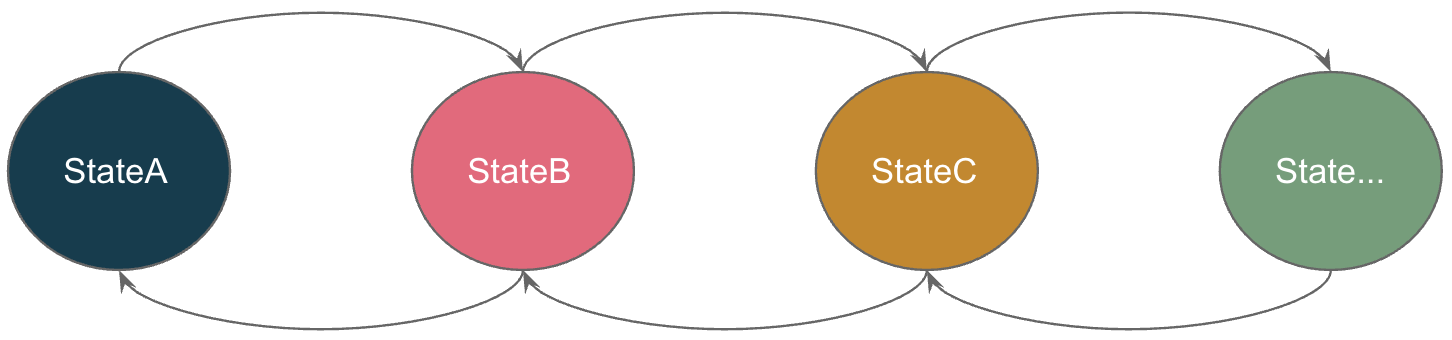
Take user registration as an example: registration can be broken down into three steps:
Input user name and password
Verify email
Pay membership fee
These three steps can be documented as three explicit states by union type. The behaviors like registration, adding email, verifying email, etc. can easily be designed as functions by pattern matching against this domain model.
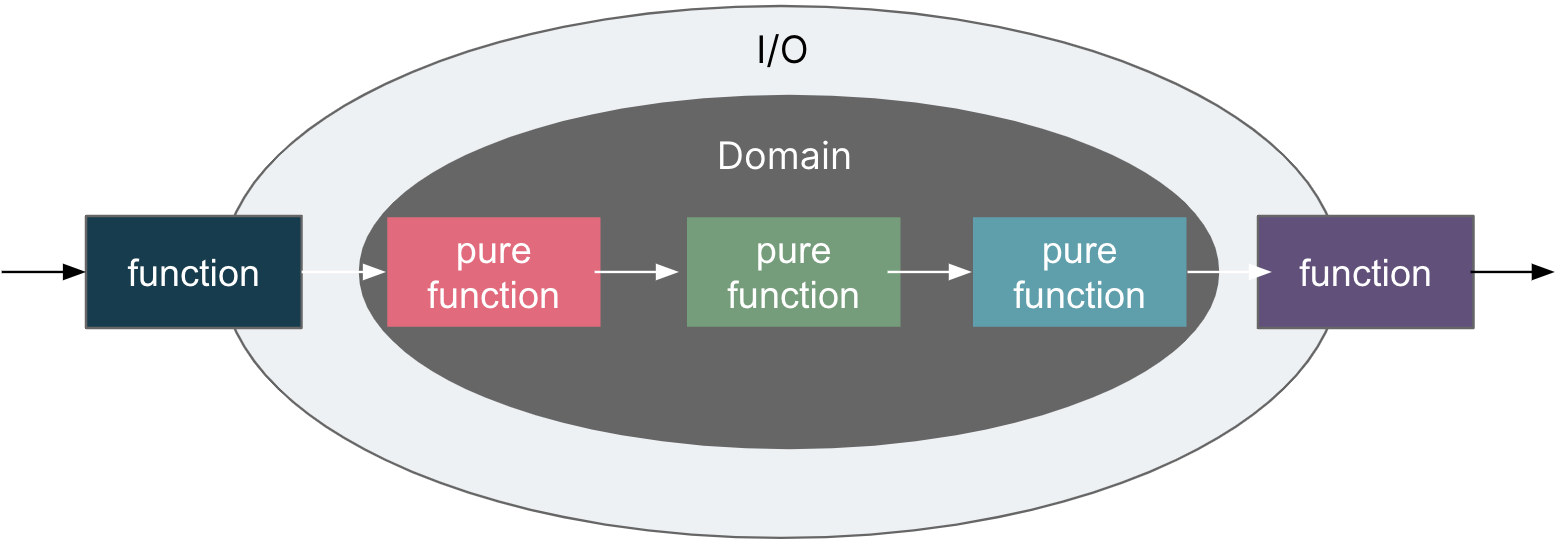
Applications that follow the Dependency Inversion Principle tend to achieve Onion Architecture or Clean Architecture. The idea is to put the business logic and domain model at the center of the application, instead of having business logic depend on data access or other infrastructure concerns. This dependency is inverted: infrastructure and implementation details depend on the application core.
Similarly, in FP, we tend to combine functions as pipelines in each API request. As with Onion Architecture, we are going to put the side effects out to the domain as much as possible to keep the domain pure. The pure functions follow the persistent ignorance principle, they are focusing on implementing business rules.
Usually, OO programming languages are the go-to choice to implement DDD, and FP is considered good at data science pipelines. In fact, DDD is just the idea that you should focus on the domain, it’s not attached to any particular programming paradigm. You can take advantage of FP features such as Composable, Monad, Applicative, and Pattern Matching to implement DDD at the “Component” architecture level.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

