














Article
Data Mesh in practice: Getting off to the right start (Part I)

This is the second article in a series exploring the key practices and principles of successful Data Mesh implementations. You can read part one here. The practical learnings explored herein have all come from our recent Data Mesh implementation engagement with Roche. However, the use cases and models shared have been simplified for the purposes of this article, and do not reflect the final artifacts delivered as part of that engagement.
In our previous article, we introduced a three-stream discovery process that we undertake at the beginning of an organization’s or domain’s Data Mesh journey to align business, product, and customer outcomes. In this article, we dive into the first of those streams, looking at the operating model changes required to support Data Mesh, and the discovery process that helps us identify and define them.
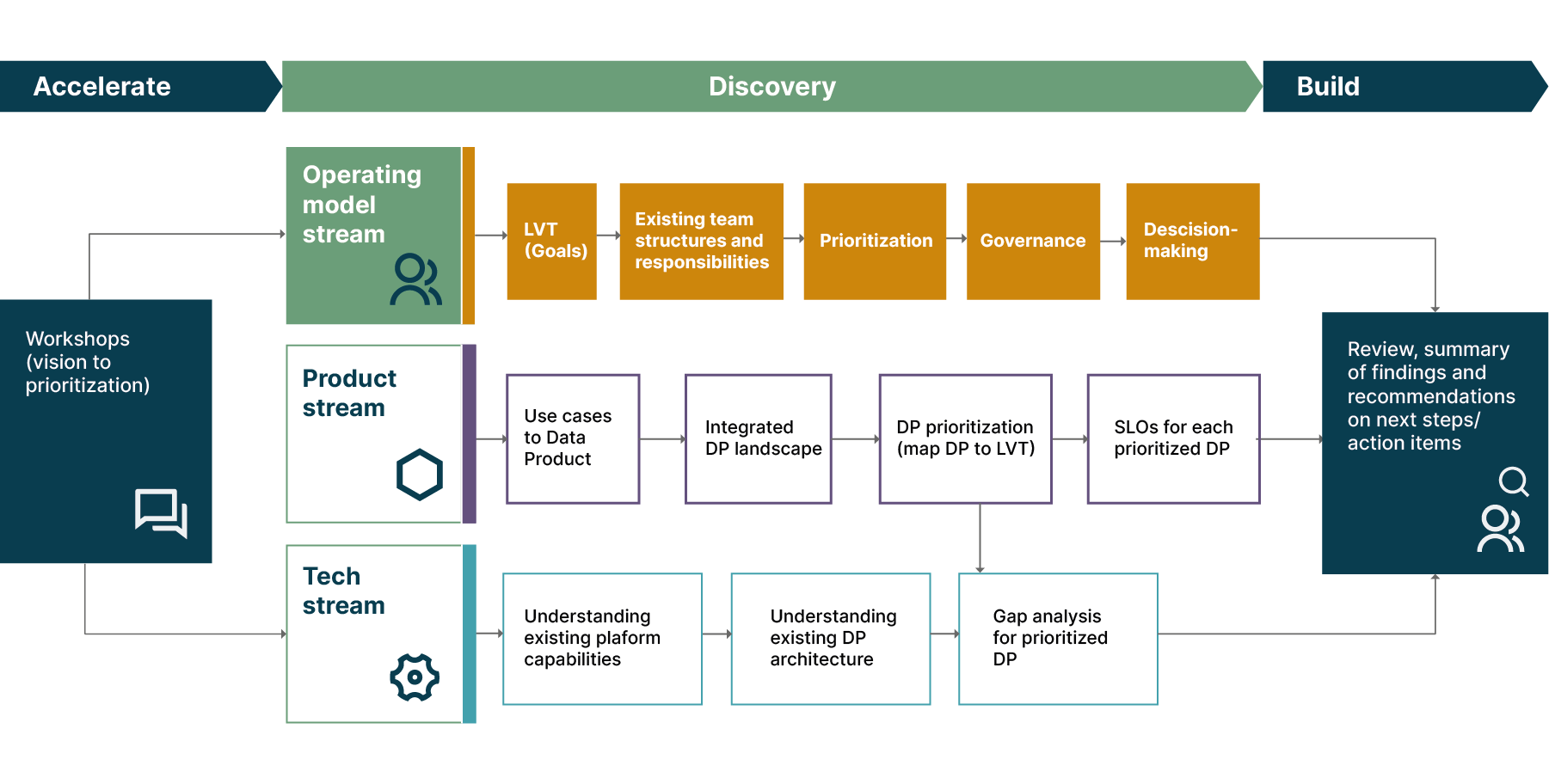
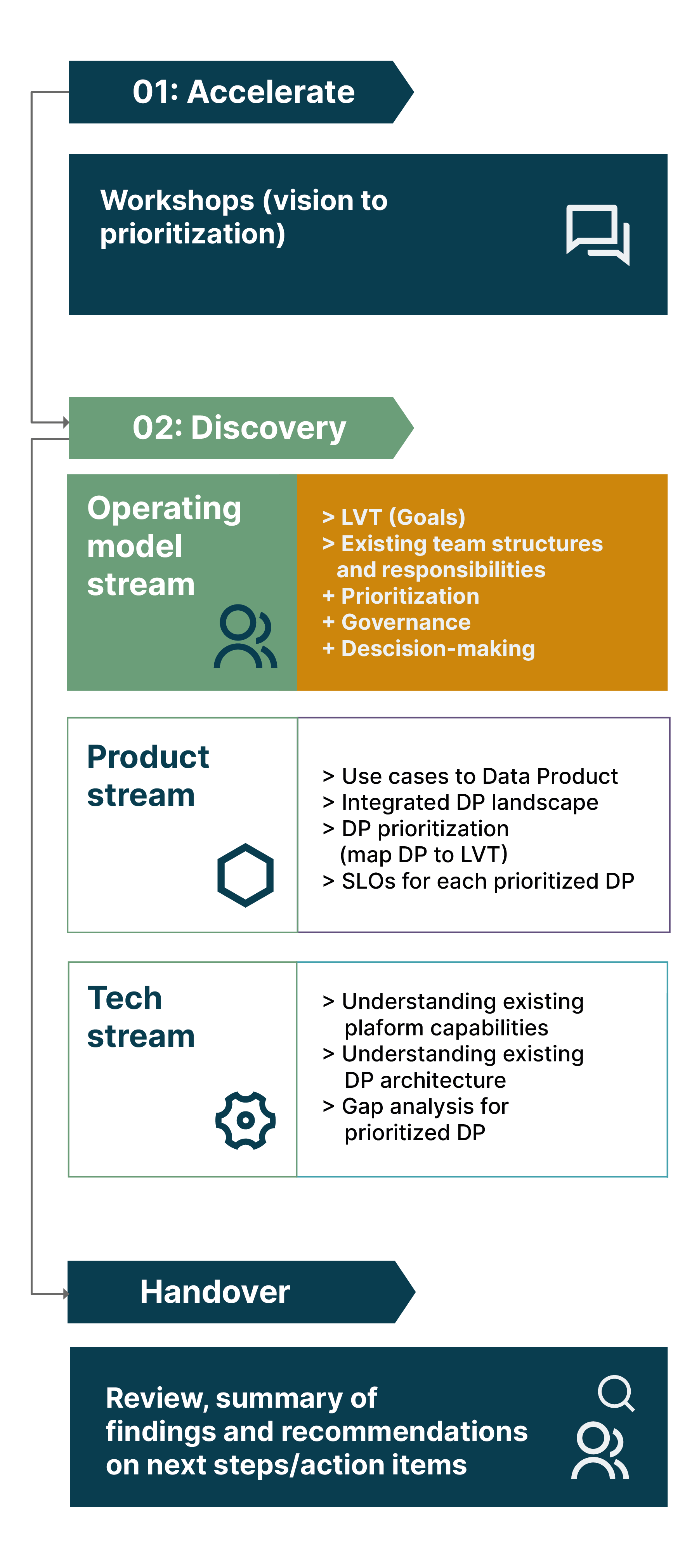
The operating model discovery stream starts with a clear view of the company’s and domain’s vision for Data Mesh. By starting with strategic goals and priorities, the domain can work back toward identifying the necessary steps, changes, and capabilities needed to bring that vision to life — rather than jumping in and working out what’s needed along the way.
In the operating model stream, stakeholders define how they’ll work once they’re part of the Data Mesh, and how processes and practices will need to evolve to enable it. Through that process, they answer critical questions including:
Does our current team structure align with Data Mesh principles, and will it need to change? If so, how?
Who within the domain will take responsibility for our data products and become our internal data lead if we don’t have one? Will they need a defined team to support them?
How will we prioritize between the Data Mesh use cases that our domain wants to explore, and which of those are most valuable to us immediately?
How will we prioritize use cases when they’re relevant and valuable to multiple domains, and how can we incentivize data product sharing to ensure that each product delivers maximum business value?
How will we manage governance internally, what guardrails will we need to put in place, and how can we ensure those guardrails don’t undermine the autonomy and flexibility that Data Mesh enables?
As we answer those questions across our Data Mesh projects and engagements, we guide clients towards operating models based on the EDGE operating model, as shown in the graphic below:
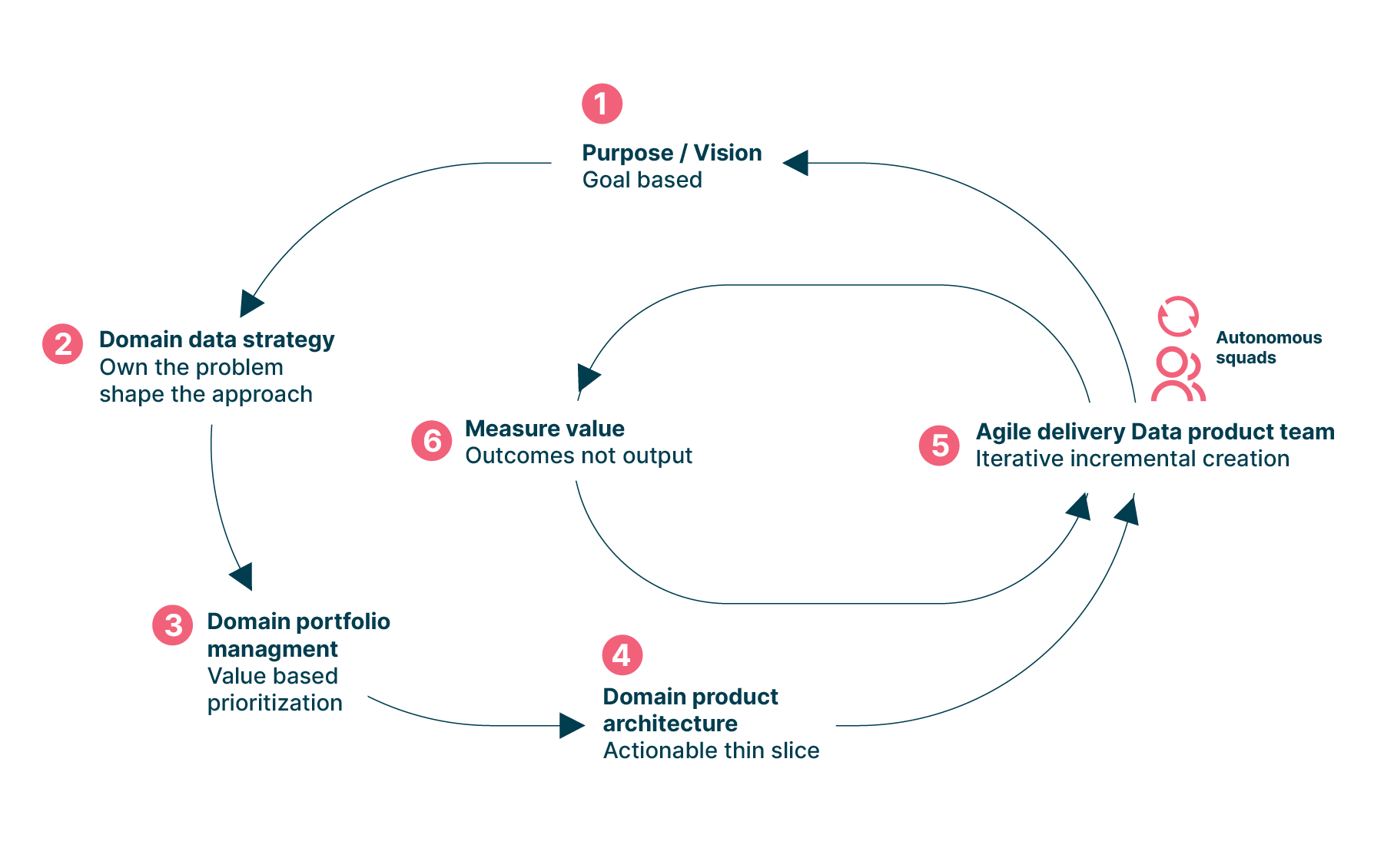
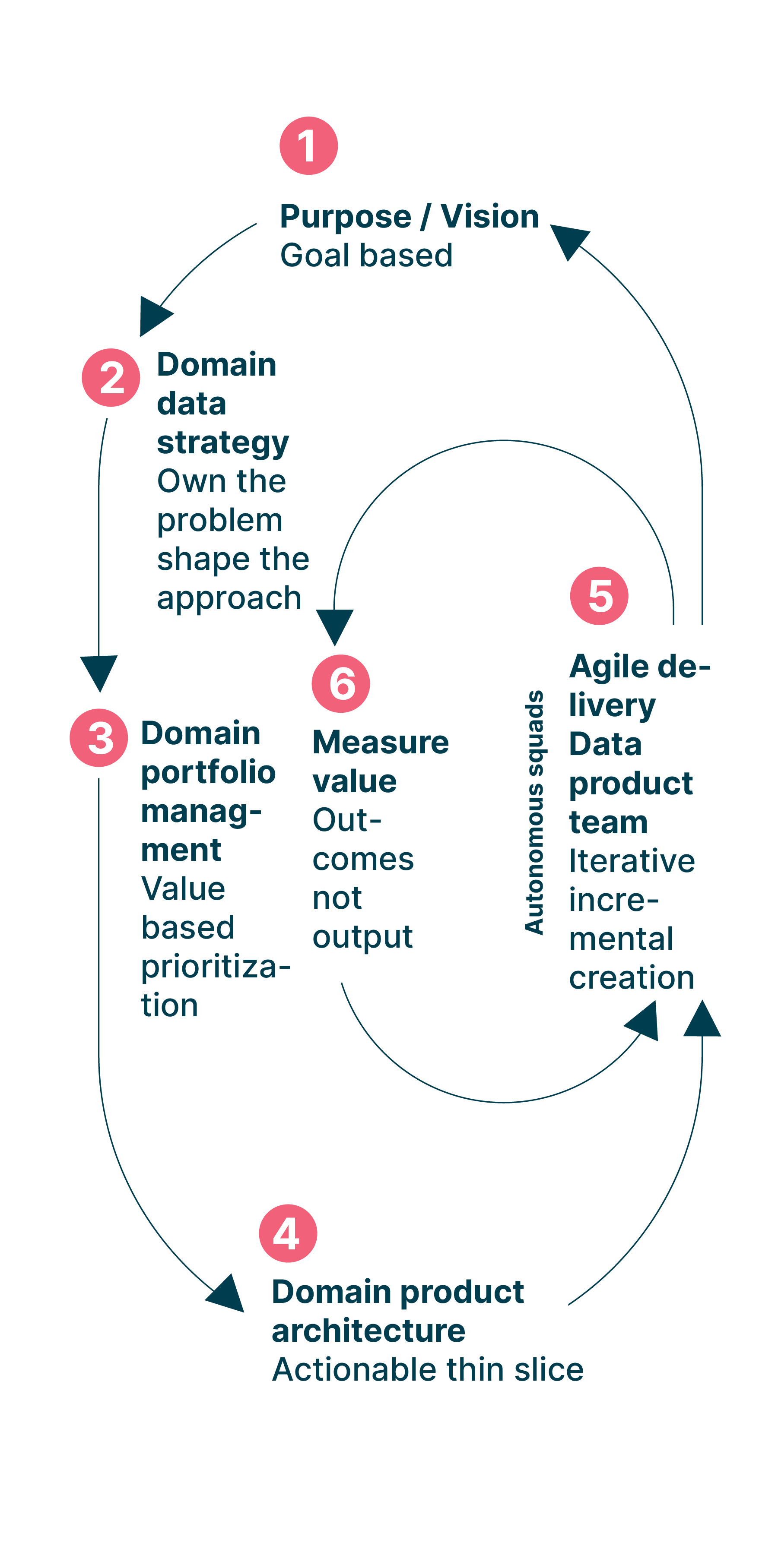
The EDGE model is built on a lot of the same principles as Data Mesh. Both EDGE and Data Mesh:
Emphasize autonomy across domain teams
Empower teams to achieve their goals, their way, without prescriptive delivery requirements
Advocate for developing multiple use cases ‘bets’, sometimes referred to as ‘value hypotheses’, simultaneously, so teams can easily pivot between them if one doesn’t work out
Challenge traditional centralized structures and propose new approaches to governance and the development and execution of strategy
That similarity makes the EDGE model a good fit for many organizations and domains that are adopting Data Mesh for the first time. By taking the EDGE operating model as your starting point, your journey can begin with a model that’s tightly aligned with the principles of Data Mesh. The model also ensures that every decision-maker has a consistent definition of what constitutes ‘value’ for the Data Mesh, and how to prioritize different value hypotheses across domains.
The EDGE model also helps us create one of the most valuable outputs of the operating model discovery process - alignment on priorities. The artifact which represents and communicates this alignment is a Lean Value Tree (LVT). It’s worth noting that other methods call this cascade of outcomes differently; these can be just as valid if the principles described here are applied.
The LVT is broken down into three tiers:
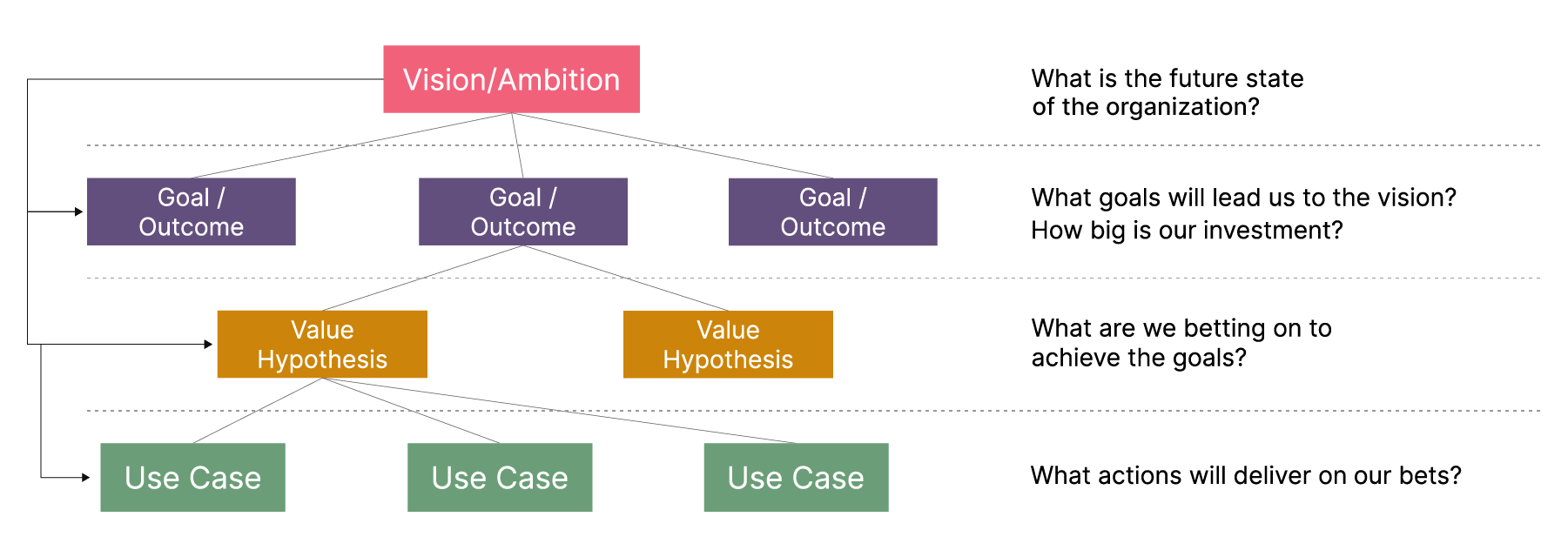
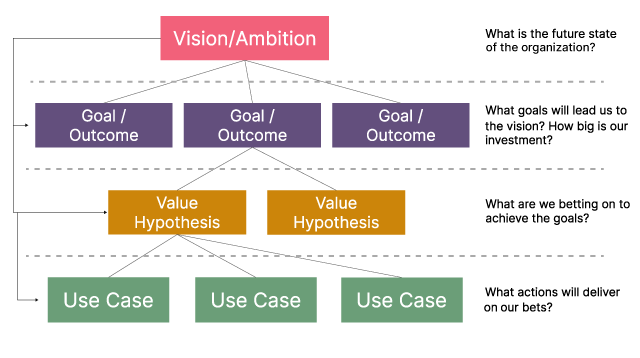
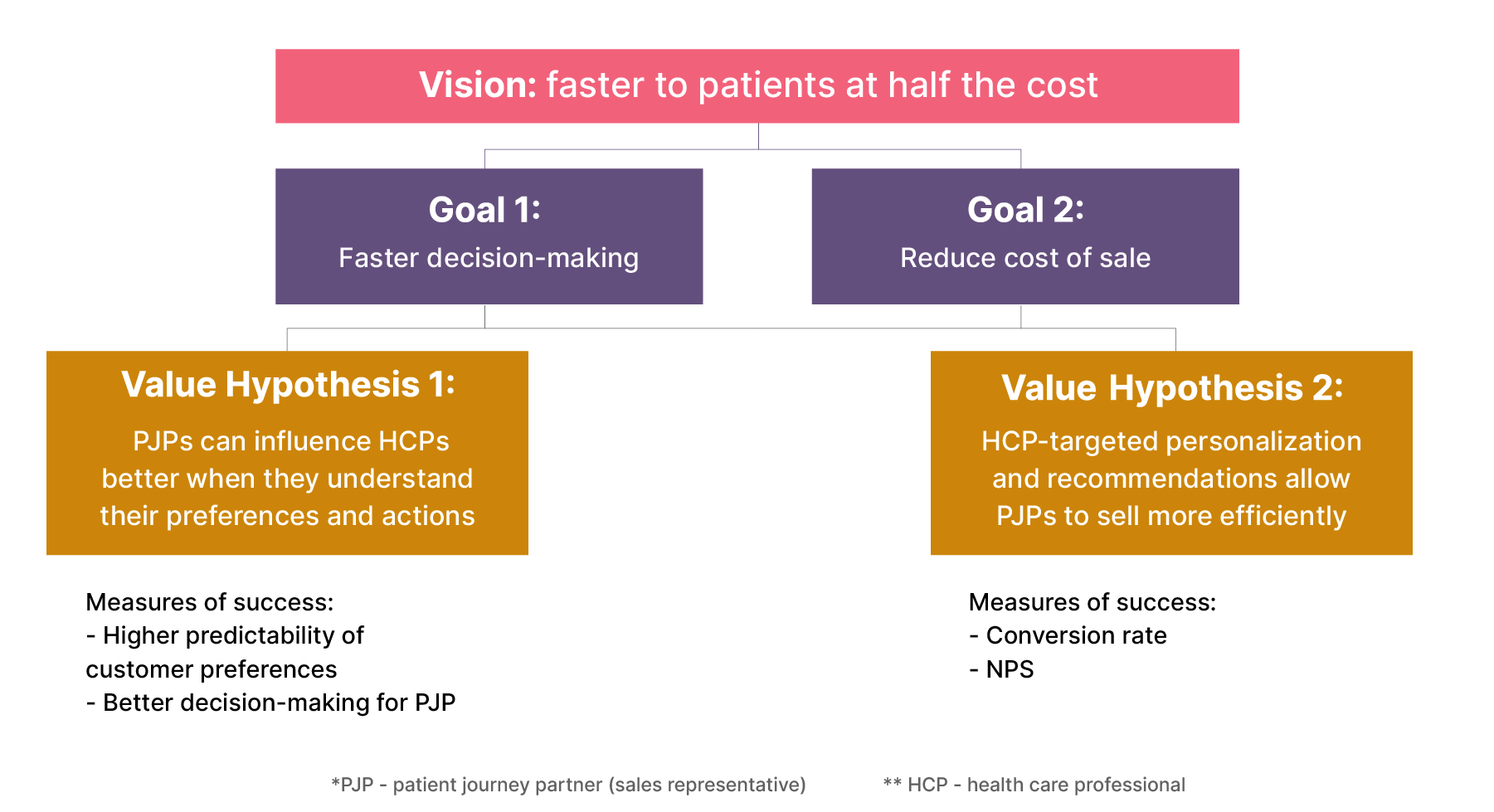
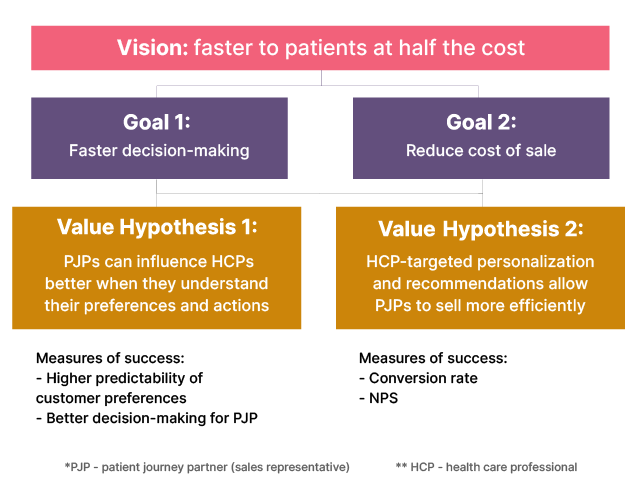
Throughout this article series, we’ll follow a running example from our recent Data Mesh implementation project at Roche. The example LVT below was created through a discovery exercise with one of Roche’s commercial business units — a team responsible for accelerating healthcare outcomes and bringing healthcare products to patients faster. This is done by PJP (Patient Journey Partners) engaging with their corresponding HCPs (Health care professionals), who in turn bring the medication to the patient population.
Here’s how we mapped their vision, goals, value hypotheses, and measures of success into an LVT:
Data Mesh is a decentralized architectural paradigm. So, for the millions of businesses built around centralized structures and organizational designs, it represents a significant evolution, and requires well-planned change.
If you simply try to shoehorn Data Mesh into a centralized organizational structure, it’s very unlikely to deliver the value you want it to. Within centralized structures, it’s easy to create scenarios where central teams and leaders solely drive Data Mesh adoption, and domain teams know very little about the initiative, or what it’s designed to do. Naturally, that leads to low adoption and buy-in, and ultimately results in a Data Mesh implementation that has very little impact on the business.
Instead, organizations need to consider how well they’re set up for Data Mesh success. You don’t (Typically) need to rebuild your organization from the ground up, but it’s certainly worth reevaluating your organizational model and structure, to see if there are any ways that you could better support and enable the collaborative and bottom-up input required to drive Data Mesh success.
That isn’t a quick or insignificant step. Organizational evolution requires its own transformation program and careful change management. You’re laying a foundation for decentralized data success and domain-driven innovation. Depending on how your organization operates today, aligning your structure and ways of working with that can be almost as significant as your Data Mesh implementation itself.
While the concept of Data Mesh is now well-known in the data and digital space, for many domain teams, it’s still new territory. So, it’s important that they understand what joining the Data Mesh means for them, and what their individual responsibilities within it will be.
Once a domain joins the Data Mesh, the people that make up that domain team become custodians of the data and data products they create. That’s a type of responsibility many won’t be used to, so we use the discovery process as an opportunity to educate teams about what it means for them, and what they’ll need to do once everything is implemented.
Establishing accountability is also important at this stage. The whole team may be on board with the concept of Data Mesh and be eager to start building their own use cases and data products. What is the new role of leadership in this setup? Governance may be federated within the Data Mesh, but within each domain, who is ultimately accountable for data products and decisions made regarding them?
Answering those questions and allocating and defining any new roles required is a valuable part of the discovery exercises we’ve run so far. However, it’s also important to put relevant incentives and support in place to ensure that the people nominated to take on new roles and responsibilities are supported and encouraged to do so.
As part of the process, domain owners — those individuals also accountable for the business outcomes of the domain — align defined objectives and priorities with their managers and peers in other domains to ensure cohesion in outcomes.
Data product teams then own their products collectively, just like software teams own their code collectively. Each data product needs a nominated owner who acts as the team's ambassador and key communicator to their stakeholders and other data product teams. They take charge of the product roadmap and lifecycle, communicating expectations and facilitating collaboration.
Finally, the data platform team provides services to the data product teams using the platform. Depending on the platform's scope and scale, a platform may have multiple teams working on providing those services, in which case they’ll also scope their work along complete outcomes, just like the data product teams do.
The platform owner takes on product management tasks for the platform, working with the team to plan the platform’s evolution, take on feedback from users and communicate any planned changes. For companies with multiple platforms, it's imperative that the various platform owners align on how they’ll guarantee interoperability, but we’ll explore that in more detail later.
Another important output of the operating model stream are clear governance structures, like the example below.
Interaction between governing bodies and data product teams
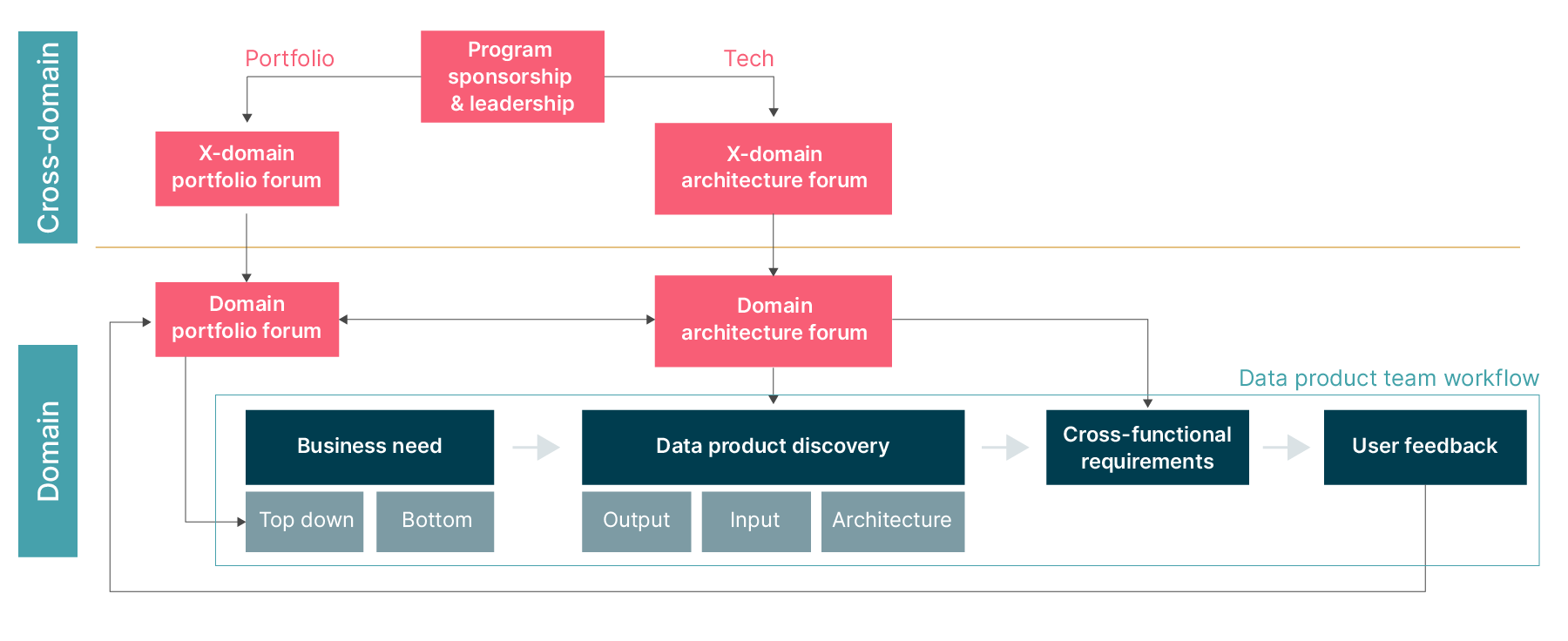
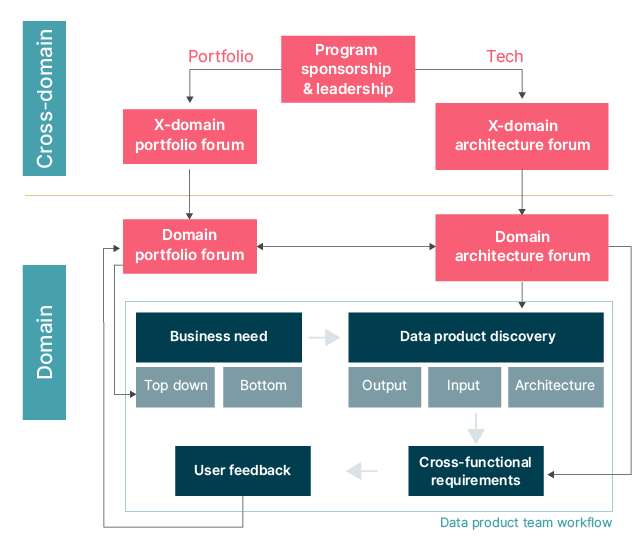
The structure shows how governing bodies and data product teams should interact and helps communicate where different responsibilities lie. Crucially, it also helps demonstrate how governance within the Data Mesh transforms from a top-down approach where a single team acts as a gatekeeper, into a bottom-up approach where domain and cross-domain teams can make suggestions for how data products should be managed and connected.
Across the Data Mesh, we need to look at three different types of governance:
Portfolio governance: Portfolio governance is applied at the cross-domain level and is concerned with making sure the company-wide goals are being met and appropriate value hypotheses are articulated. Special attention is paid to achieving the cross-domain outcomes needed for the company-wide goals. Measures of Success from the LVT are continuously discussed to understand which bet has paid off and which needs adjusting or replacing. The domain owners and executive management representatives play an active role in this conversation.
Domain governance: At the domain level, product and domain owners decide on which data use cases to pursue, and make sure that the right data products are being created to support and help achieve overarching goals. Those teams break use cases down to identify the data product required to realize them. Large clients tend to run another round of portfolio governance within the domain to address the volume of work and federation of decision making.
Technology governance: Domain architects and technical leads agree on how to build data products and set standards for domain and product teams to follow. These guardrails ensure interoperability between data products, without limiting domain-driven innovation.
We’ll explore more about technology governance in the final article of this series, where we’ll take a detailed look at computational and federated governance across the Data Mesh.
The operating model stream of the discovery process brings domain teams to the point where they’ve defined several high-value Data Mesh use cases, and prioritized the use cases they’d like to begin their journey with. This doesn’t just help ensure their journey starts with fast, clear, high-value wins — it also helps establish repeatable processes for decision-making and prioritization on future Data Mesh projects and bets.
In deciding on the use case and the measure of success for the use case, the team has also already defined the very first consumer data product — the value measure by which they’ll track and communicate their progress in adding business value from data.
Crucially, it does one more thing. Determining the use cases a domain wants to focus on provides valuable input for the product stream of the exercise, establishing what kind of data products might be needed to bring those use cases to life.
In the next article, we’ll explore the product stream and look at the processes we’ve built to prioritize data product creation and ensure data products are tightly aligned to domain and organizational strategy.

