














Generative AI
Context-aware incident handling with MCP: A strategic view with a practical case

Since the mid-2010s, SRE has been the foundation of modern software operations. It made large-scale distributed systems controllable.
Today, systems are no longer only distributed; they’re becoming cognitive and partially autonomous. Decision-making is moving into the system, while AI is simultaneously augmenting human cognition and code generation.
This raises a first-principles question: can our existing SRE model still keep systems under control, or, just as distributed systems once required the invention of SRE, are we entering a new paradigm?
As a control system, SRE requires software systems to be observable, modelable, predictable and intervenable. Without these properties, no system can be governed at scale.
The three pillars of logs, metrics and traces are not debugging tools but modeling primitives:
Logs model the event timeline.
Metrics model the state space.
Traces model the causal topology.
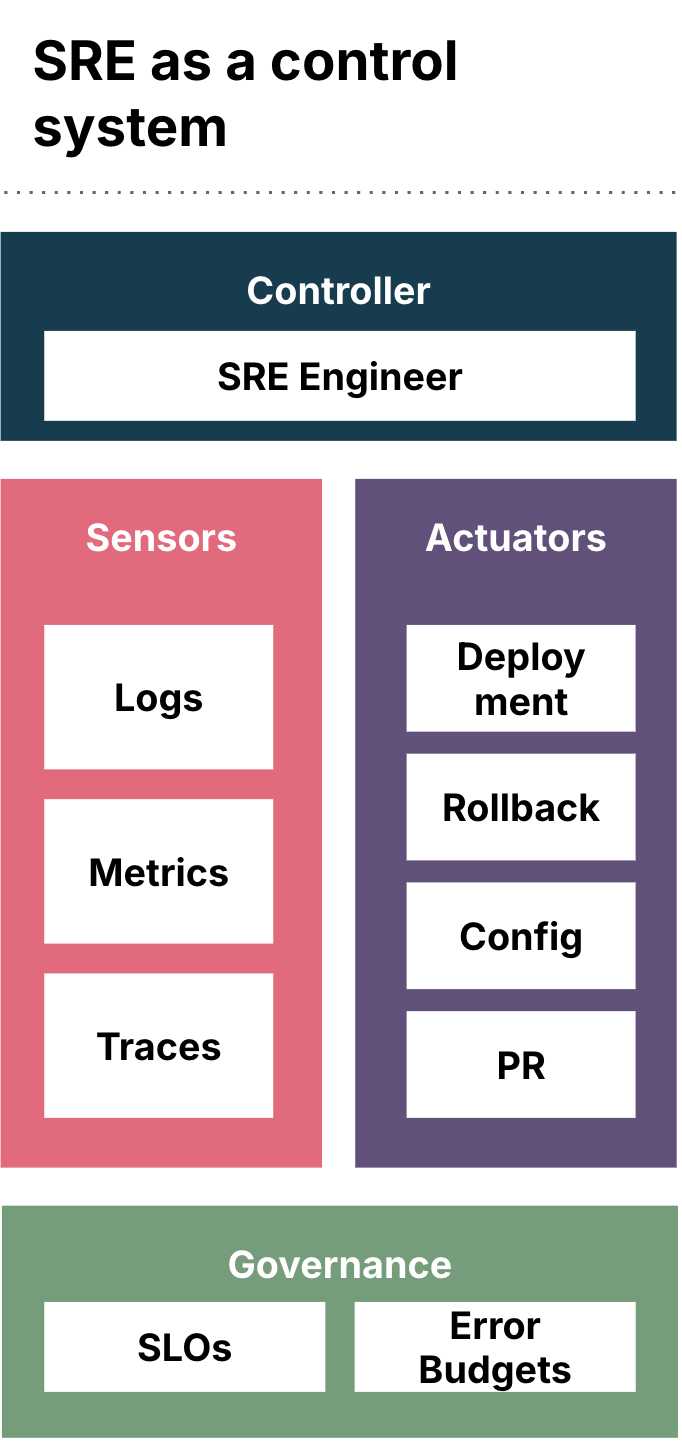
Together, they form the minimal system model required for control (Diagram 1.). Without this model, large-scale distributed systems are not operable. With it, they become engineering objects.
SRE emerged in response to engineering failure, with humans losing the ability to control their systems. In the mid-2010s, software architecture crossed a structural complexity boundary. At the same time, the cost of failure increased dramatically as digital business exploded.
| Dimension | Before 2010 | After 2010 |
Architecture | Monolithic, tiered | Distributed, microservices |
Deployment | Low-frequency, manual | Continuous delivery |
Dependency model | Linear, hierarchical | Graph-based, networked |
Failure mode | Localized, isolated | Emergent, cascading |
State space | Finite and enumerable | Exponential |
Back then, SRE wasn’t born as practive for optimization but instead one built to recover control. By modeling events, states and causality, SRE made distributed systems controllable again. That’s why SRE became an institutional foundation of system control, not a tool.
The three pillars of SRE — logs, metrics, and traces — are often treated as universal observability primitives. In reality, they rest on five control-theory premises:
Assumption | Meaning |
Deterministic behavior | The same input produces the same outcome |
Enumerable state space | System states can be modeled and sampled |
Stable causality | Dependency relationships remain consistent over time |
Logs reflect reality | Observability data records actual system behavior |
Single objective | The system optimizes toward a stable goal function |
Under these assumptions, distributed systems, though complex, remain controllable. Logs reconstruct event sequences; metrics approximate system state; traces expose causal topology. Together, they form a sufficient system model.
This is why SRE worked as a reliability discipline for deterministic execution systems, assuming behavior is the result of code and topology. However, fifteen years later, these assumptions may not be guaranteed.
Fifteen years after the birth of SRE, we’re entering a new regime of complexity. This is one defined not only by scale, but by a fundamental change in what systems essentially are. There are five forces that define this new context:
Force 1 Accelerating complexity
| Force 2 Deterministic and non-deterministic systems are converging | Force 3 Software delivery itself is changing | Force 4 Control authority is shifting | Force 5 Cognitive augmentation is compensating |
System scale, dependency depth, change velocity and automation chains continue to grow, pushing observability cost up and cognitive tractability down. | Enterprises are now operating hybrid environments where legacy systems, modern deterministic platforms and probabilistic AI systems are tightly coupled and mutually dependent. | Vibe coding and AI-generated software are reshaping how systems are built, introducing an unprecedented scale and velocity of machine-generated change that must be governed. | AI models, autonomous agents and decision engines are entering production control loops, sharing decision-making between humans and machines. | LLMs dramatically improve human’s ability to understand complex systems. |
This context mirrors the moment when distributed systems first broke human control capacity fifteen years ago. Just as SRE emerged then, a new control paradigm is now required.
Control theory is simple: when system complexity exceeds an organization’s ability to observe, model, predict and intervene, the existing control system collapses.
At that point, failures become hard to replay, behavior becomes hard to predict, interventions become risky and responsibility becomes blurred. These are all signals that controllability has been lost.
This is exactly what enterprises experienced back in 2010s before the rise of SRE, and it’s what they’re beginning to experience again as intelligence integrates into enterprise IT systems at scale.
Before failures hit enterprise IT operations, IT leaders must confront the emergence of a structurally inevitable paradigm shift in SRE.
Enterprises are entering a new operating context where system complexity continues to grow, non-deterministic behavior is becoming native, AI-generated code is entering production at scale, and autonomous intelligence is moving directly into business workflows.
SRE as a control must evolve. That’s why we want to introduce a new control architecture:
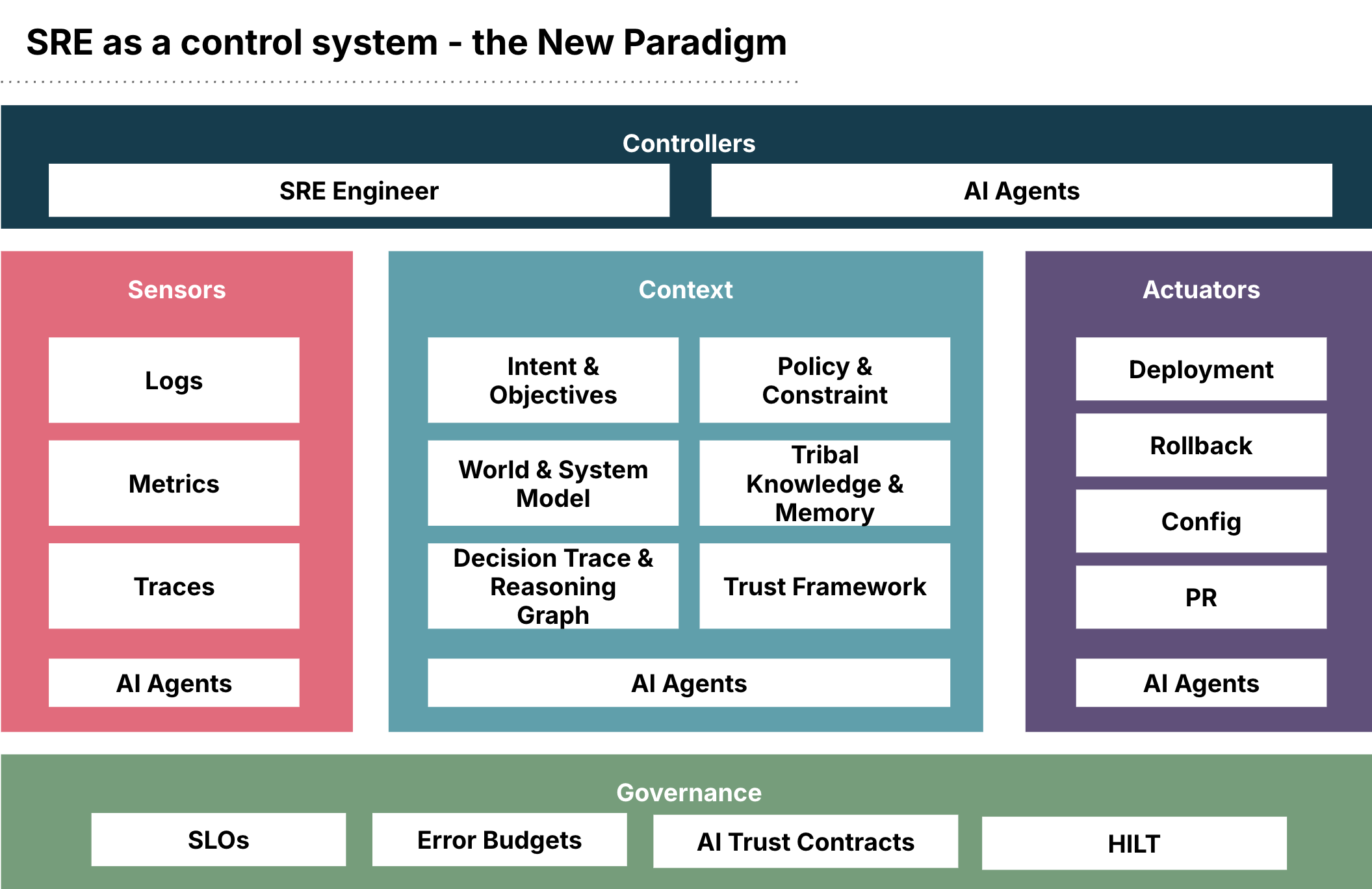
In the new model, we use LLMs to compensate for human cognitive limits by introducing AI agents into the controller, sensors, and actuators.
As controllers, AI agents work with engineers to explore problems, reason about incidents and propose actions.
As sensors, they continuously retrieve and interpret telemetry to surface patterns and hypotheses.
As actuators, they execute changes and remediation steps under human guidance.
SRE is no longer a human-only activity. It is AI-augmented (with controls).
A new context component is introduced as a first-class part of the system. This layer captures intent, policies, system understanding, historical knowledge and decision rationale, and is continuously enriched by AI agents. It turns raw telemetry into meaning and provides the substrate on which decisions are formed. Without this layer, systems can be observed but not properly understood.
Governance is extended beyond system reliability to include AI trust controls. Traditional SLOs and error budgets remain for execution, but they’re complemented by controls over autonomy, decision quality, drift, policy compliance and auditability. The goal is no longer only to keep services running, but to ensure the intelligent agents augmenting SRE behave correctly and can be trusted.
Together, these changes transform SRE from a discipline that controls execution into one that is intelligent by itself and governs the new state of complexity.
SRE was created in the 2010s to make distributed systems controllable. It succeeded by turning complexity into an engineering problem through modeling, observability, and disciplined control.
Today, systems are no longer only distributed. They are becoming cognitive, autonomous and increasingly self-directed. Decision-making is moving into software, while AI is reshaping how systems are built, changed and operated. The original control model is no longer sufficient.
We believe building intelligence into the new control system is the only way to govern intelligence itself. It’s no longer possible to rely solely on human cognition and the classical SRE construct.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

