














AI and ML
Active learning loops

Many organizations start their machine learning (ML) journey with high hopes, but almost inevitably struggle to realize the potential of ML due to unnecessary detours and unforeseen time sinks.
It has been reported that 87% of data science projects never make it to production. Even among companies who have successfully deployed ML models in production, 58% of them take more than a month to deploy a new model. In addition, it’s common to see valuable but frustrated crew members leave along the way. This hinders the delivery of value to customers and also impacts the people and teams working on these initiatives.
So the question is - is there a more effective way to deliver ML?
There is, and it boils down to fast feedback. Fast feedback is a singular thread that spans almost every MLOps practice. Here are a few examples of practices that help to shorten feedback loops:
Writing automated tests and applying continuous delivery practices to avoid the need for tedious manual testing and catch bugs before they become production incidents
Getting feedback on hypotheses and ideas through user testing, before investing (and dare we say, wasting) months of engineering effort
Running regular retros and building team safety so that we hear about authentic team sentiments regularly and find ways to improve collectively, rather than hearing about them through exit interviews
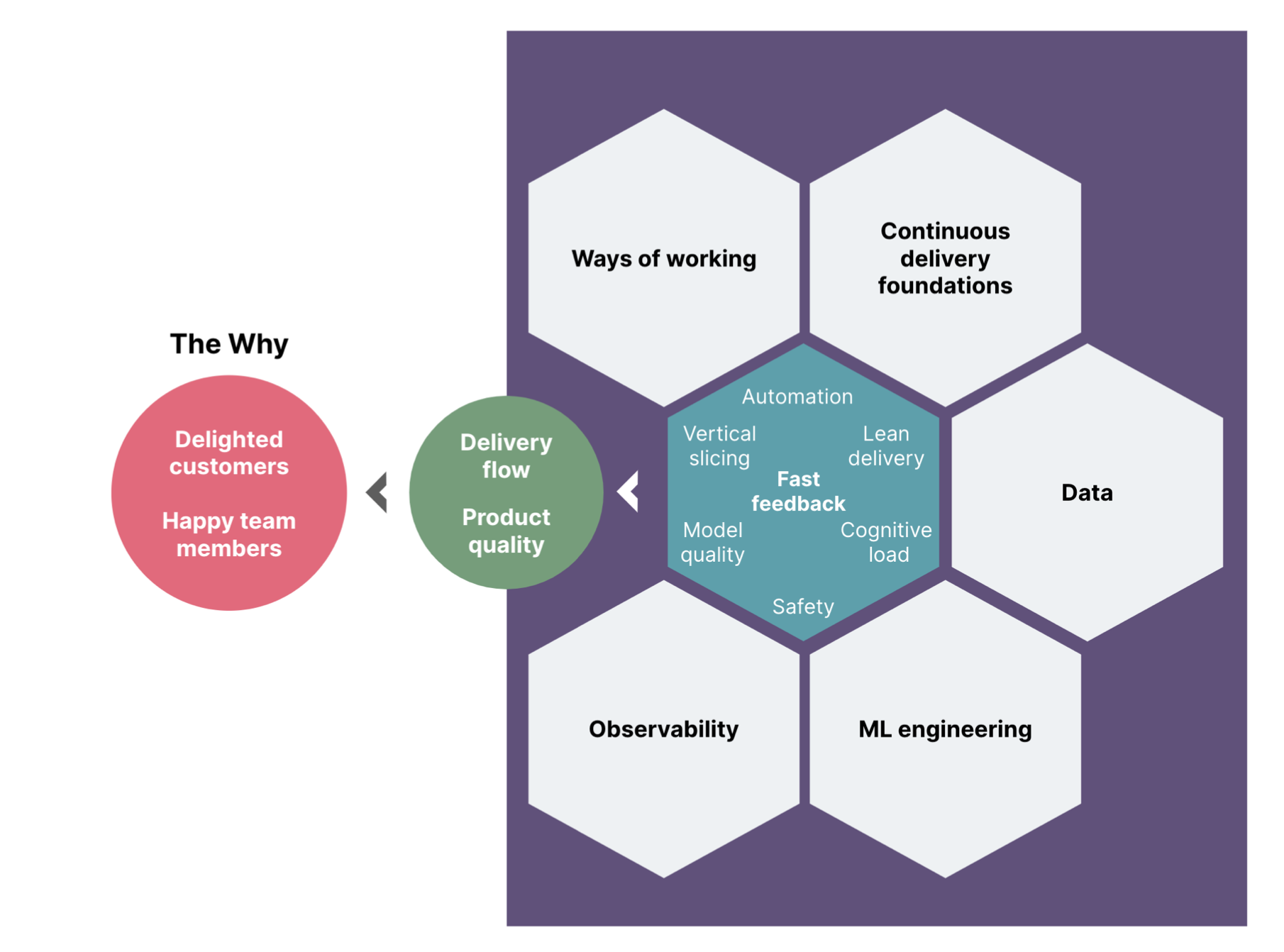
In this mini-blog series, we will describe the principles and practices that keep feedback loops short and allow us to iterate quickly, safely and reliably:
Part II: Shifting quality left
Part III: Improving information flow
Part IIII: Taming cognitive load
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

