














Article
Data Mesh in practice: Organizational operating model (Part II)

Since Thoughtworker Zhamak Dehghani published her first article laying out the concept and principles of Data Mesh in 2019, a huge amount has been written on the topic. Now, with a significant number of successful Data Mesh projects under our belt, we’re able to enrich our understanding of the practice of Data Mesh.
In this series of articles, we’ll share practical learnings from our recent Data Mesh implementation engagement at Roche. As the world’s largest global provider of healthcare, Roche generates, manages, and processes vast quantities of data across a wide range of deeply specialized domains. We lay out what it really takes to successfully apply the principles of Data Mesh in a large corporate environment.
As Zhamak points out in her book Data Mesh: Delivering Data-Driven Value at Scale, Data Mesh isn’t just another architectural approach — it’s a sociotechnical paradigm that demands process, operating model, and technological transformation. “Sociotechnical” refers to both the layers and nuanced ways that human social systems interact with — and come to grips with — technology to produce improved outcomes. [1]
Principles guiding all building blocks of Data Mesh
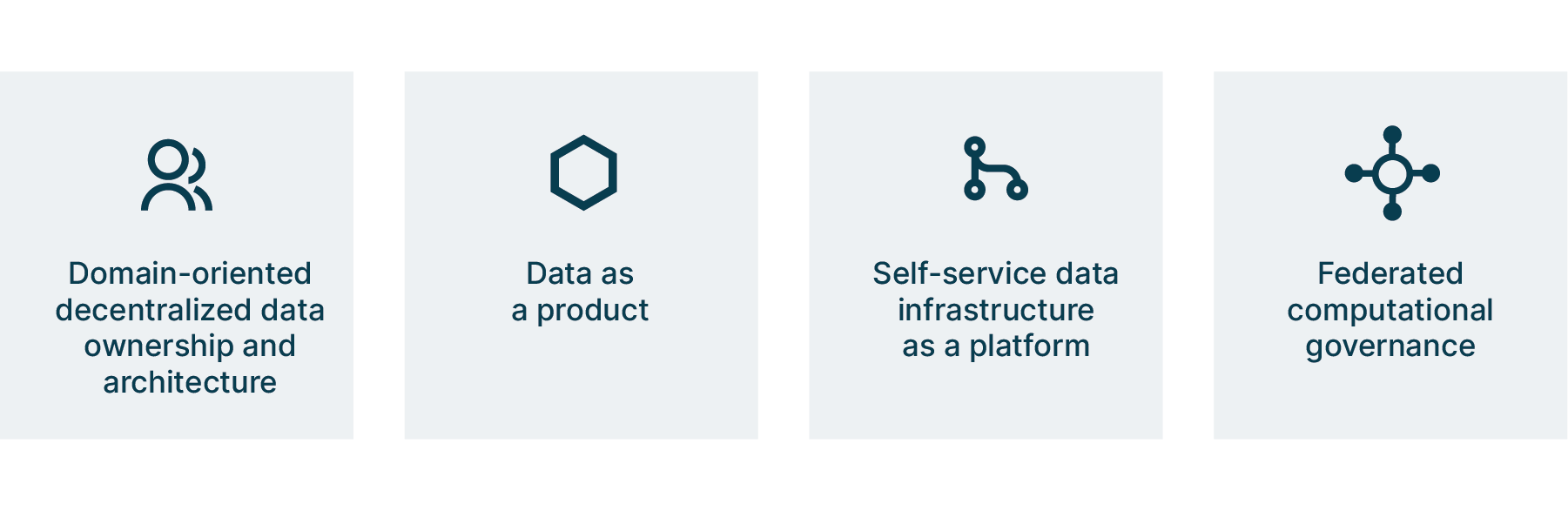
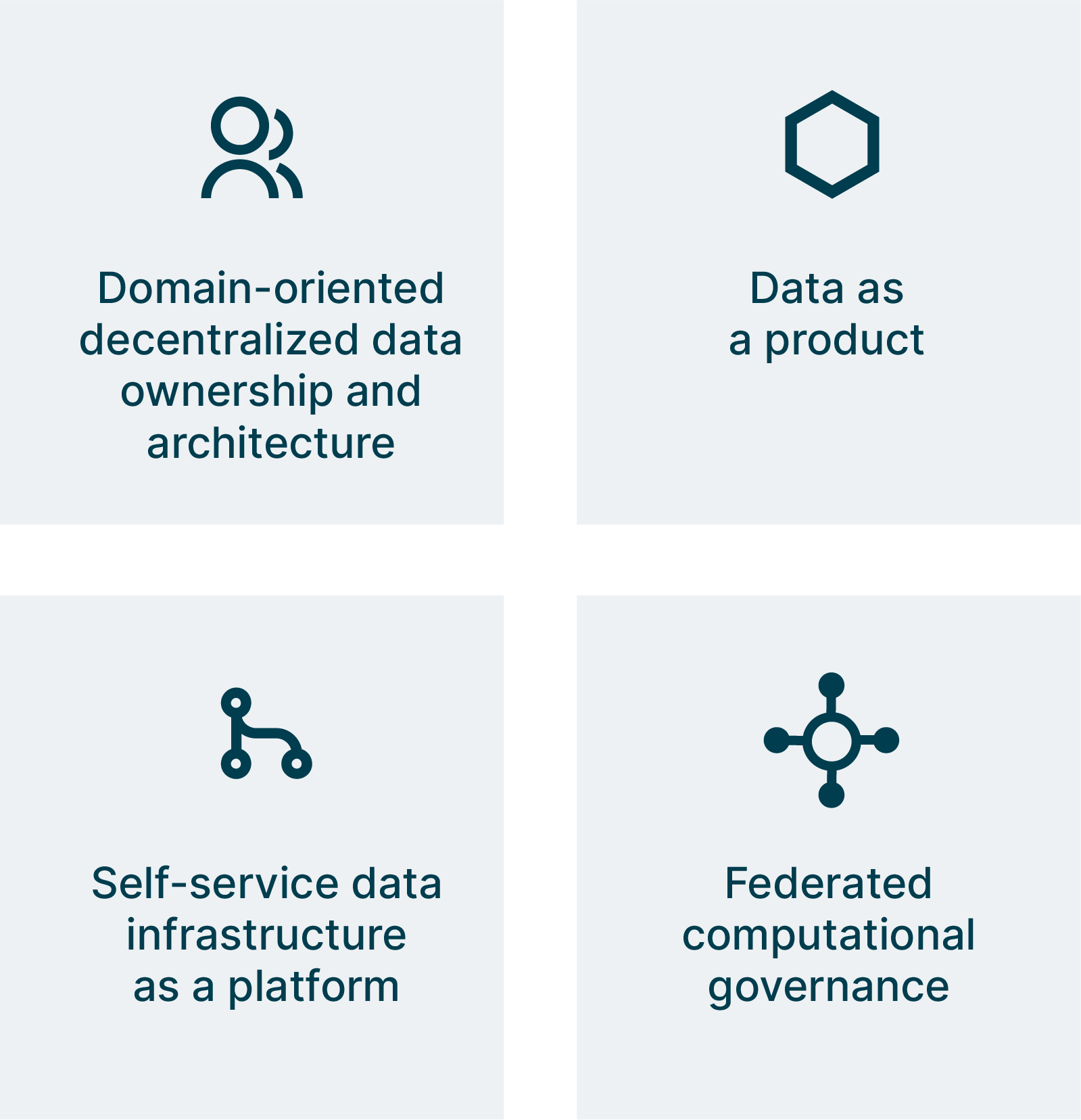
The four principles of Data Mesh — as defined by Zhamak — help us start to understand the range of sociotechnical requirements needed to build a strong Data Mesh.
The first two, ‘domain ownership and architecture’ and ‘data as a product,’ both demand significant changes to operating models. Whereas ‘self-service platforms’ and ‘federated computational governance’ demand deep engineering expertise and evolutionary architectures. These are two very different types of change, and if they aren’t understood and approached in the right way, they can undermine the huge potential value of the Data Mesh approach.
In this new series of articles, we will take a deep dive into the organizational, process and operating model changes required to support Data Mesh, the practical demands of building data products, and the architectural requirements of the approach. Throughout the series, we’ll show you how we’ve balanced the diverse changes needed to bring Roche’s vision for Data Mesh to life, and share some of our proven principles and practices to help you do the same.
Before embarking on any data journey, especially a Data Mesh one, it’s essential that you have a clearly articulated data strategy at the organizational level. To create that strategy, teams must answer value-oriented questions, such as:
How are data, AI, and other leading capabilities going to deliver value for our business?
Do we want data to help us increase revenues, cut costs, improve customer experiences, or create new revenue streams — or some combination of the four?
What are our key strategic data use cases, and how can our data strategy support them?
Answering those questions enables organizations to make informed decisions about what they really need from their data architecture, and help shape how they ultimately measure the value delivered by their chosen architectural approach. In this article series, we’re looking at the process that follows that definition — exploring the journey that begins once an organization has clearly defined its data strategy and determined that Data Mesh is the right architectural choice to support and deliver it.
Across this article series, we focus on the practices, principles, and steps that Thoughtworks takes to plan and execute successful Data Mesh journeys. Each article explores a different aspect of those journeys, but here’s a quick snapshot of how those actions come together across the journey as a whole:
Cross-domain planning and scoping
Operating model: from project to product
Product thinking
Technology evolution
Cross-domain maintenance and evolution
If you’re looking for insight into a specific aspect of the Data Mesh journey, you can jump ahead to the relevant article using the links below, where you’ll find expanded explanations of the practices and principles introduced above:
Article #2: Planning your operational and organizational evolution
Article #4: Executing your technological and architectural transformation
To open the series, we’ll look at a few of the consistent, high-level challenges faced when adopting Data Mesh, before introducing our design-thinking-based double diamond process that we use to kickstart successful, high-value Data Mesh journeys.
Following the principle of network effects [2], the value of Data Mesh increases with the number of interoperable use cases it serves, so scaling is a top priority for enterprises adopting the model. However, their eagerness to scale at speed has consistently created a challenge across all of the implementations we’ve seen.
From the social perspective of our sociotechnical paradigm, organizations adopting Data Mesh are on a learning journey. They have a lot of experimenting to do to determine what’s going to work best for them. In the process, they’ll discover powerful business and customer use cases that deliver unique value for their organization. Naturally, they want to apply those lessons across as many domains as possible.
However, if you scale too fast, you won’t have the opportunity to learn effectively or incorporate what you’ve learned. Going too quickly creates a dynamic where distributed domains are all doing their own learning, but not learning from one another or collaborating on collective data efforts. Teams falling prey to this challenge get stuck in the experimentation stage, searching for ways to solve their own issues without identifying any of the enterprise-wide challenges that the organization as a whole could overcome using Data Mesh.
To address this potential trade-off and overcome the challenges it creates across our Data Mesh projects, we’ve designed a set of practices to help organizations successfully balance both the learning and scaling demands of Data Mesh adoption. In keeping with the federated nature of the Data Mesh, our approach allows for parallel work by decentralized teams.
Our long experience practicing Domain Driven Design has helped us understand the benefits of drawing clear boundaries around contexts to separate concerns and allow teams to focus on solving problems within the context they fully understand and can control. It is natural that many Data Mesh implementations try to define domains to which they can assign data product ownership. However, in our experience, it is not necessary to reorganize business units or departments for the sole purpose of designing data product teams and data products. In many cases, you can start assigning data product ownership within your existing structure, and evolve it as required, as your journey progresses. In determining who owns the data, we follow the business outcomes to business processes and existing decision making frameworks around it.
Data Mesh empowers domains to make their own data-related decisions and build their own data products. That’s a lot of autonomy — especially compared to traditional centralized data architecture approaches, where everything must go through a single IT or data team.
That level of freedom naturally raises a lot of important questions: Who needs to be part of goal definition conversations? How should outcomes be measured? Who keeps an eye on progress towards targets and offers management support to teams when they need it?
To help answer those questions, we drew upon Thoughtworks’ EDGE operating model for inspiration on how to connect high-level business goals right the way down to a data product team’s backlog items. We found that EDGE lends itself well to the context of domains adopting Data Mesh. Rather than giving teams prescriptive outputs that they need to work toward, they’re aligned around specific goals to deliver customer value. Each domain has the autonomy to decide the best way to reach their domain-specific goals.
The result is a set of domains that are all aligned with organizational strategy and data strategy, but empowered to work toward strategic goals in ways that make sense based on their context, and apply their domain-specific knowledge to leverage data in creative ways, enabling them to deliver more customer value.
As Data Mesh best practice is constantly evolving, there is no single ‘best path’ for teams to follow. They’ve determined that Data Mesh is right for them, defined some initial use cases, and got to work on making it happen. Unfortunately, in some cases, that’s led to ineffective projects that haven’t made it past the POC phase.
Through our experience, we’ve applied the Design Council’s ‘double diamond’ approach to onboarding a new domain to Data Mesh, as shown below.
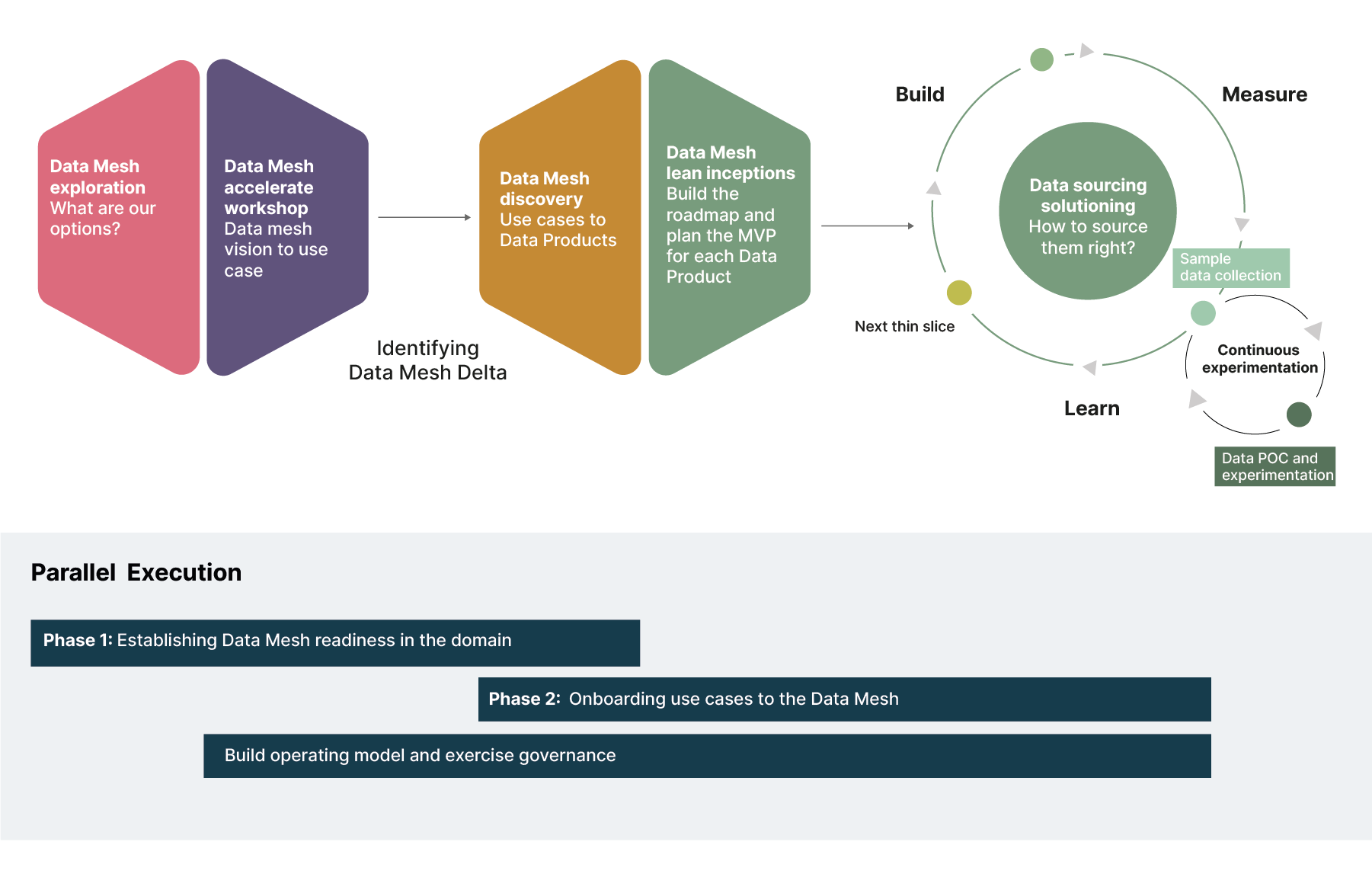
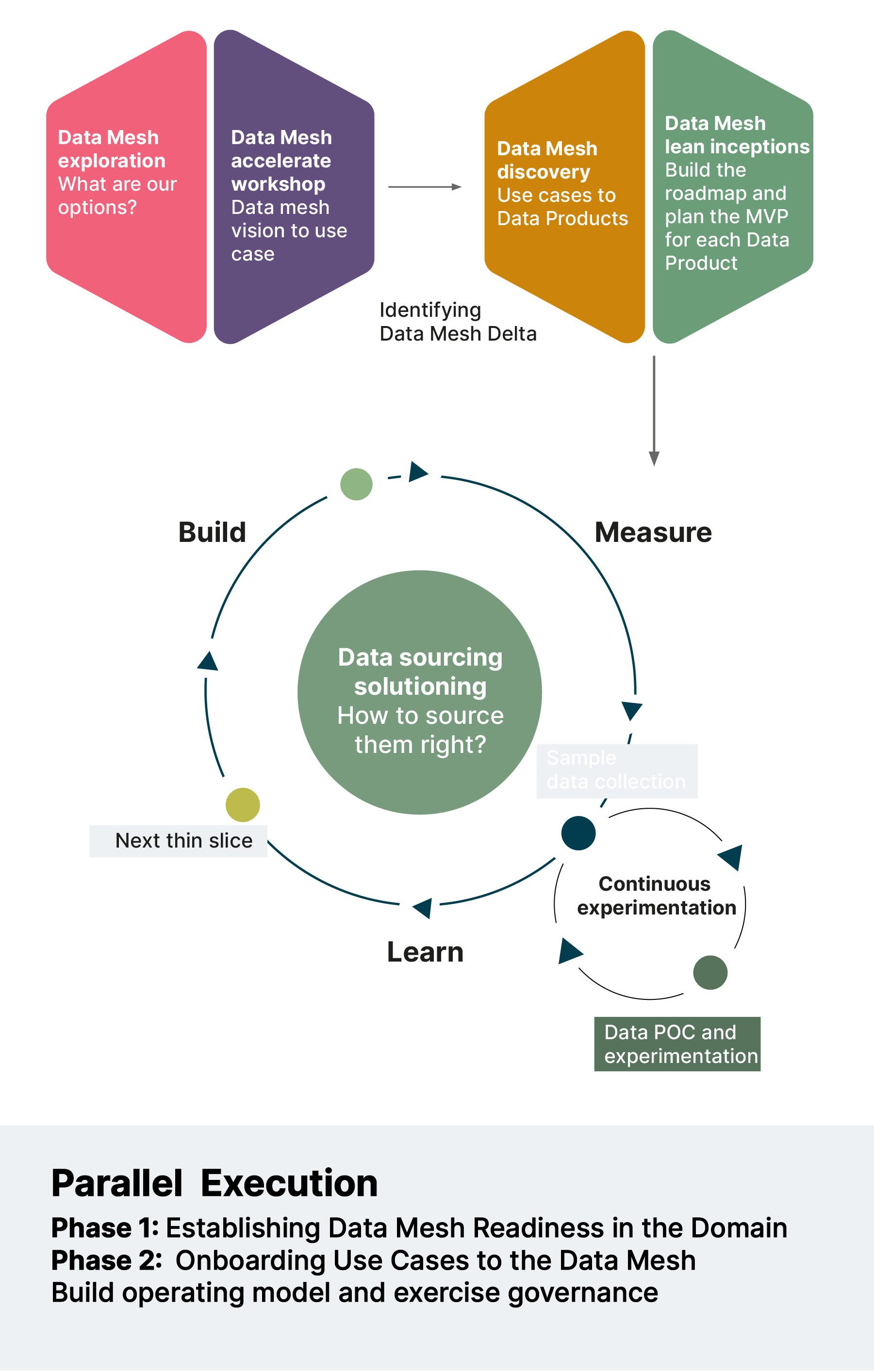
The double-diamond ensures that domains focus on the business ‘why’ and ‘what’ before they move on to think about the engineering ‘how’. The first phase of the double diamond incorporates the vital discovery step providing the ‘why’ and ‘what’, while the second phase of the double diamond addresses the ‘how’.
By going through a detailed discovery process, domain teams know exactly what they’re getting into and can strategically align with business goals and customer value. They’re able to clearly lay out what they want to achieve by joining the Data Mesh, how it can help them contribute to strategic goals, and what they’ll need to get there. It starts the onboarding process, while also providing a framework for everything that needs to come after it.
One approach we have found very successful here is to define, as part of the discovery, the “Data Mesh delta” — the gap between where the domain currently is vs what they want to achieve with Data Mesh. To identify this delta, we break our discovery process down into three streams:
The operating model stream
The product stream
The tech stream
In line with the principles of Data Mesh, those streams can run concurrently. The graphic below shows the three-stream discovery process that we’re currently running across multiple domains at Roche:
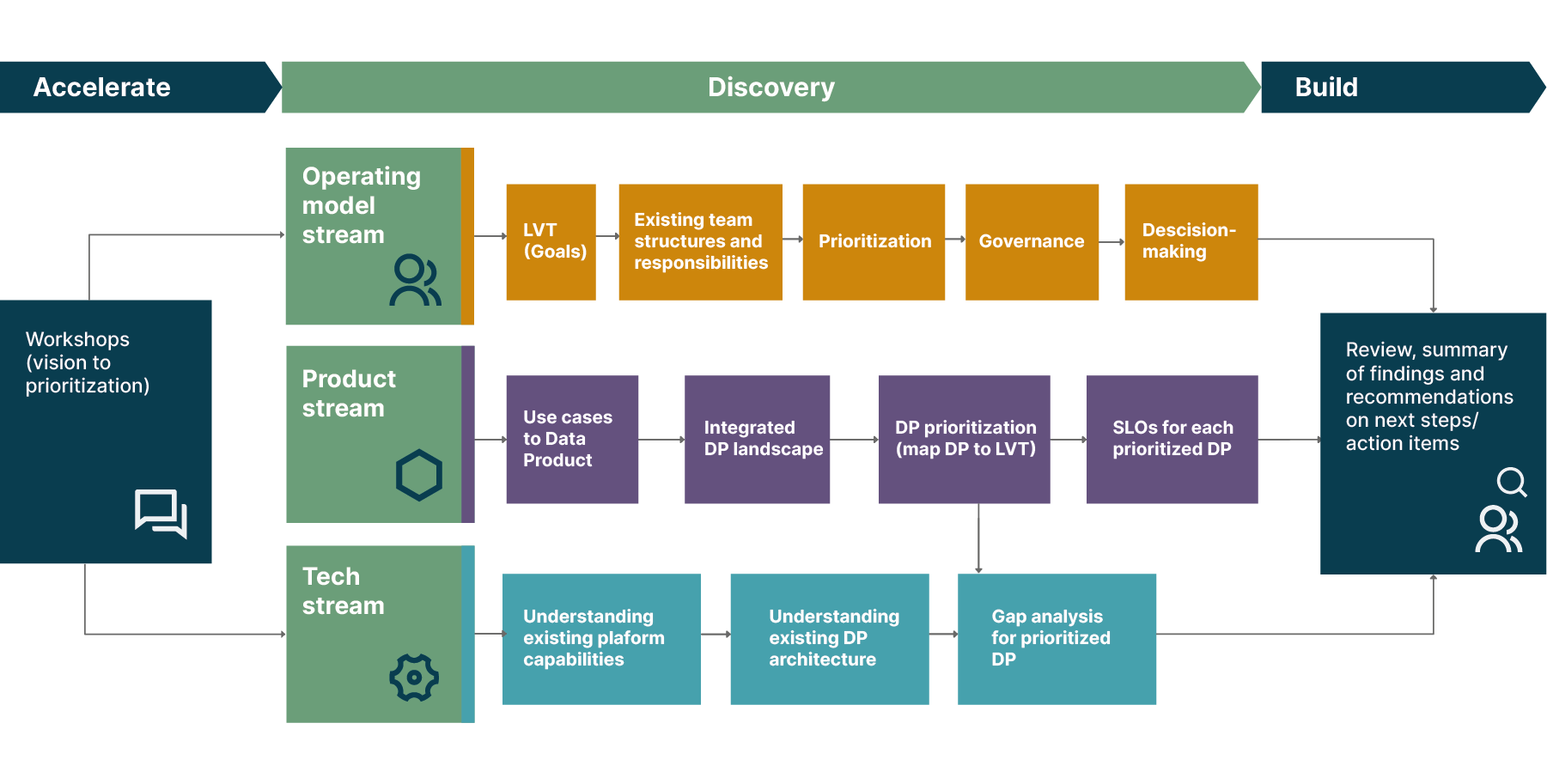
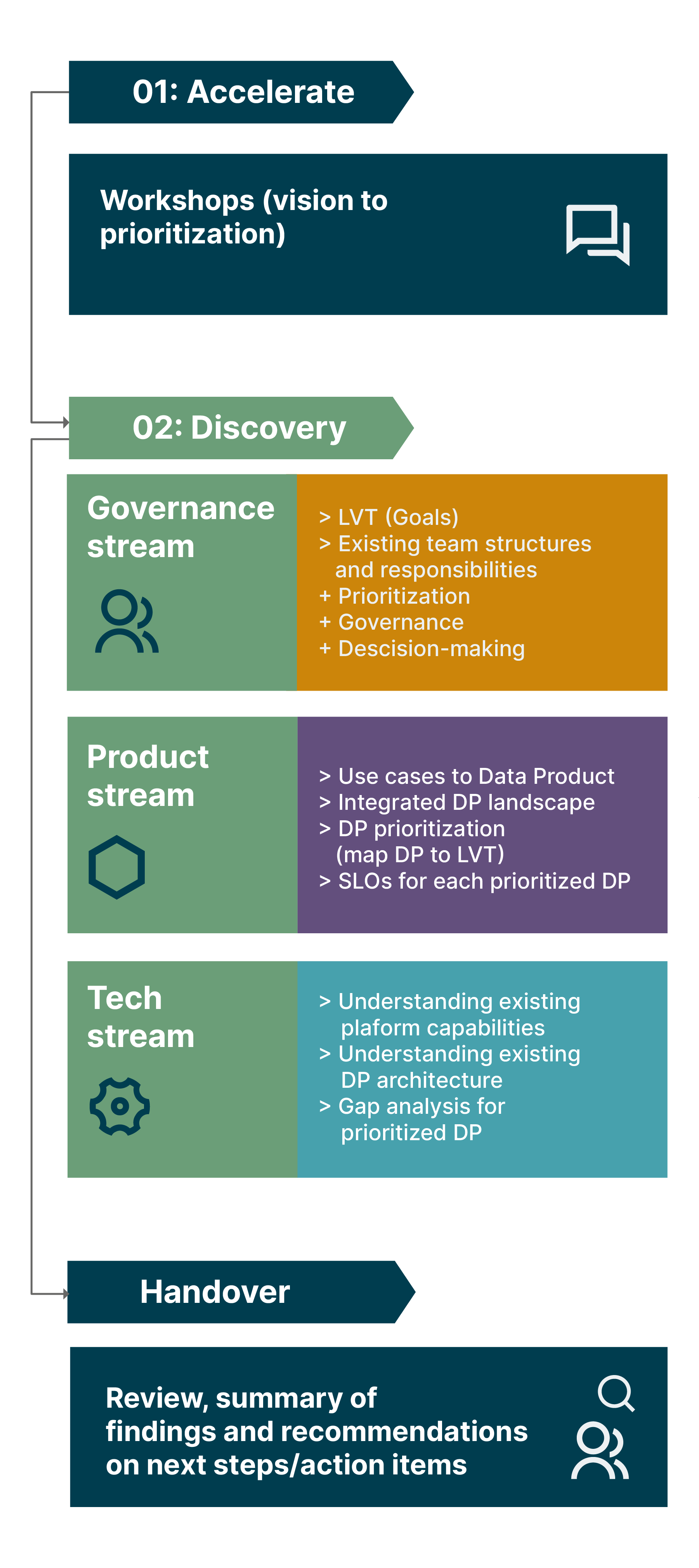
The three streams identified and explored during the discovery process don’t just help to scope and plan a domain’s onboarding onto the Data Mesh. They provide a framework for how onboarding should be executed, and the simultaneous organizational, process, and technological changes that are needed to ensure that Data Mesh ultimately delivers its full value for each domain, and the organization as a whole.
In the following articles that comprise this series, we’ll take a deep dive into the three different types and areas of change required to achieve Data Mesh success. Each article will offer insights to those that work across the relevant domains, concluding with a high-level overview of the diverse changes and decisions required to successfully adopt, embed, and drive value from Data Mesh.
Throughout the series, we’ll share artifacts and insights from our recent Data Mesh implementation engagement with Roche. Through the lens of their journey, we’ll show you exactly how these different types of change come together to create a robust Data Mesh implementation and onboarding strategy..
In our next article, we’ll explore the organizational and operating model decisions that teams need to make throughout their Data Mesh journeys, introducing principles and practices used across our projects to ensure success and maximize value creation.
Footnotes
[1] The term “sociotechnical” was introduced by researchers at the Tavistock Institute in London in the middle of the 20th century. The canonical paper explored how a change in sociotechnical arrangements of work resulted in improvements in team cohesiveness, work satisfaction, and reduced sickness and absenteeism. See Trist EL and Bamforth K (1951) Some Social and Psychological Consequences of the Longwall Method of Coal-Getting: An Examination of the Psychological Situation and Defences of a Work Group in relation to the Social Structure and Technological Content of the Work System. Human Relations 4(1): 3–38. DOI: 10.1177/001872675100400101.

