














Continuous delivery
Managing feature toggles in teams (Part 1)

Some time ago, Steve Upton and I wrote an article about Feature Toggles. Since then, through many discussions and applying the ideas from the article, I encountered many new challenges and questions around Toggles which I like to address in part 2 and part 3. This part focuses on challenges with database migrations.
Again, this article uses the term “Feature Toggle” mostly to describe “Release Toggles” or short-lived feature toggles, that should ideally have a maximum lifetime of maybe one sprint before being cleaned up.
The two key issues that people are facing with toggles can be summed up by:
Toggling application logic that requires database migrations can be risky and difficult. Especially when already existing tables or columns are manipulated, but you do not want to change their original behavior before the feature release.
When implementing a feature like this, take care that both states of the feature toggle (ON and OFF) are valid for the state that the database is in at any given time. Preferably create proper integration tests to validate this. Furthermore, to prevent data loss, keep an eye on the reversibility of your actions. Feature toggles are meant as easy-to-reverse steps, but database migrations can become very costly in that regard.
Most database migrations fall in one of three categories, which will be covered in the following sections:
The following tips also apply for combinations of these three. More details and alternative approaches can be found in this article on Evolutionary Database Design or Pramod Sadalage’s “Refactoring Databases”.
If a table or column is added for your feature or if a column becomes more tolerant, most queries in your code should be able to ignore these added fields without a problem. So just run your database migration first, then add the toggled feature to the code which requires the new data. When releasing, simply clean up the toggle. When rolling back the change, add a database migration to drop whatever was added for the feature. Until the release, this kind of migration is easily reversable.
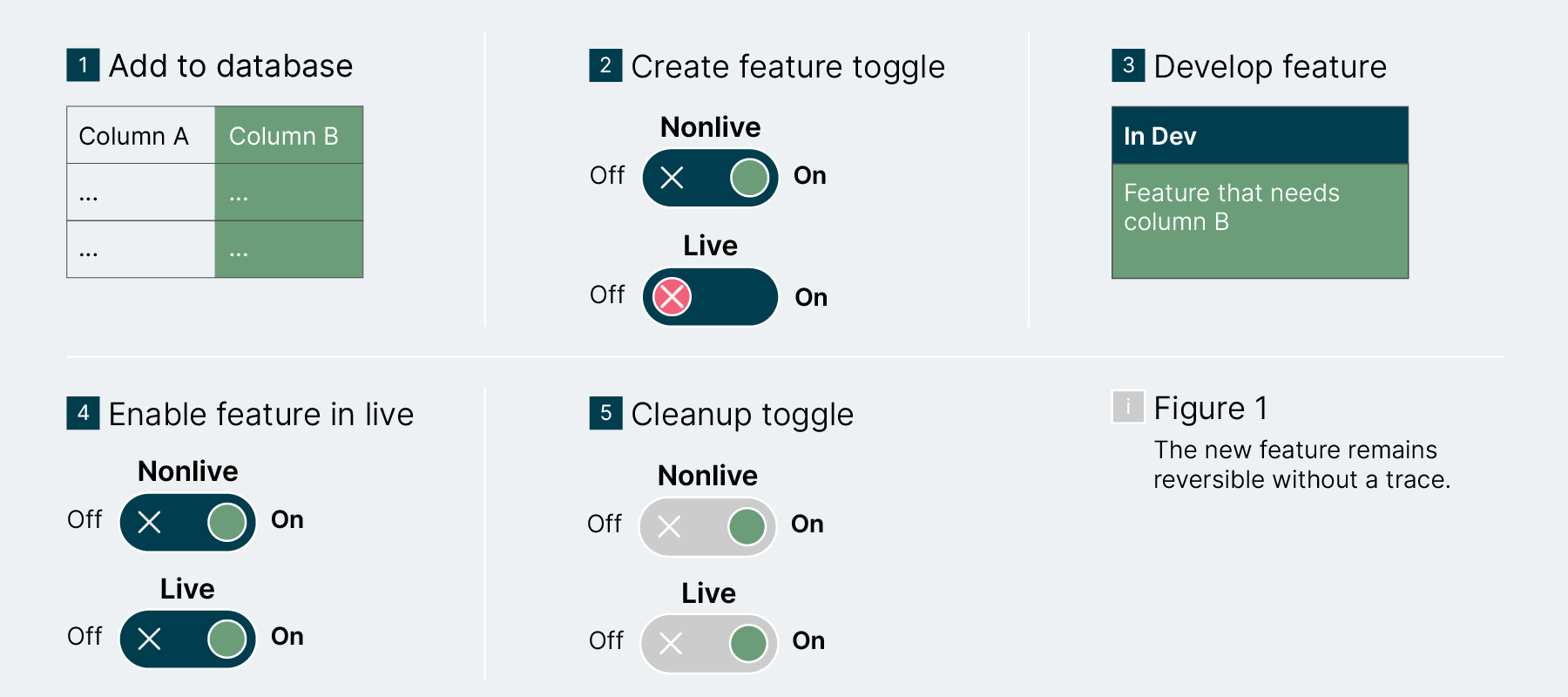
If a table or column is made redundant by your feature or if a column becomes more restrictive, the already existing queries will have trouble handling migrations that make these changes. In that case, just approach it the other way around: First add the toggle and feature. Wait for the feature to be released. Then clean up the toggle along the old behavior that requires the additional data. Finally, you can run the database migration without any risk since the data you are clearing out is no longer used.
A risk of this approach is that the feature’s story has usually been tested and signed off already when you are running the final database migration. This change is a destructive one and can likely only be reversed with a data loss.

Figure 2: The new feature remains reversible until the actual migration takes place in Step 5.
The trickiest situations are migrations that manipulate columns, for example by changing their type or name. Often, this can be achieved by temporarily adding a new column or table which fulfills the new requirements. For the rest of the section, I will assume we added a new column with a different name or type. There are now multiple approaches to handling this situation and each has its own drawbacks and tradeoffs.
You can be supporting both behaviors at all times: You continue writing into the old column and to the new column regardless of whether the toggle is enabled. Otherwise switching back and forth would not be possible without a data loss. This approach involves breaking the rule of fully hiding the new behavior from the live environment. Even when the new feature is not used yet, it can lead to unexpected failures when writing and performance loss.
You can also choose to migrate the data from the old column when removing the old behavior. Here you only write to the new column when the feature toggle is enabled, but continue writing to the old column when it’s disabled. Keep in mind that your new feature is not able to access all the data from the new column until the data has been migrated to the new. This should only be used when you do not intend to switch back and forth between the toggle states in the production environment.
Since introducing a toggle here can involve risks when migrating the data (e.g. questions like which data to keep?), be mindful and discuss the possible repercussions before writing any code. Consider different ways of achieving the goal, including not using a toggle at all for it.
In Part 2 of this series and here, we saw many scenarios where feature toggles are giving us quite some challenge to overcome. But there are just as many scenarios where feature toggles give us big benefits through decoupling deployment from release:
With all this, we can remember why we are using feature toggles in the first place and can take them as a sensible default — while keeping in mind that they are not a tool to fix all of our problems and sometimes we can also go without them.
Read the rest of this series:
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

