














Data strategy
Humanizing your data strategy: Seven key ideas for the AI era

Enterprises are rapidly embracing AI, with retrieval-augmented generation (RAG) fast emerging as the preferred approach to ground large language models in proprietary knowledge. However, AI-ready knowledge remains a persistent challenge. Most critical information still resides in unstructured and sprawling systems like Confluence, which are rarely maintained with AI in mind. Relying on a one-time migration won’t succeed, since documentation evolves daily and models quickly fall out of sync without continuous updates.
To address this, we developed an AI-ready knowledge pipeline: an automated workflow that fetches Confluence articles daily, transforms them into structured formats, and stores them securely in Azure Blob Storage. From there, content is embedded, indexed and made instantly queryable via Azure’s search services. The process is fully automated with built-in security and governance, which eliminates manual overheads and ensures daily and trustworthy refreshes.
The impact is significant: organizations can modernize documentation, maintain alignment with fast-changing knowledge and prepare information at scale for AI-driven value creation.
In this Thoughtworks AIOps blog post, we share our experience building an automated pipeline that migrates Confluence content to Azure Blob Storage. Using Azure Cloud services, we designed a workflow that fetches articles daily through the Confluence API, transforms them into markdown, and securely stores them in Azure containers.
Later the data is indexed in Search service using an embedding model. Once the data is embedded we can query that data to meet our needs. Automation is driven by Azure Functions, while Azure Key Vault safeguards credentials and access. This eliminates manual overhead, enforces strong security, and ensures seamless daily updates—offering practical guidance for organizations modernizing documentation and scaling data migration on the Azure cloud.

If your project demands robust solutions for any of the requirements below, our pipeline approach is the ideal choice to unlock seamless, secure, and scalable data integration. These include:
Continuous and incremental updates for live models. AI models, especially those used for retrieval-augmented generation (RAG), need to be constantly trained and fine-tuned with the latest information to provide accurate and up-to-date responses. Relying on a one-time migration isn’t sufficient since documentation and other knowledge sources evolve daily.
Transformation for AI consumption. Unstructured data from sources like Confluence isn’t typically in a format that large language models (LLMs) can handle effectively. The pipeline must include a transformation step to convert the data from its native format (like, HTML) into a structured and compact text format like Markdown.
Scalability and security for large datasets. As enterprises embrace AI at scale, data pipelines need to handle growing volumes of sensitive data. The pipeline needs to be designed to scale efficiently and securely. This includes using a serverless architecture, like Azure Functions, for cost-effective scaling and simplified maintenance. It also requires using a secure vault, such as Azure Key Vault, to safeguard credentials and access, ensuring strong security and compliance.
Automated change detection. Manually monitoring for changes in documentation isn’t feasible for a dynamic knowledge base. An AI-ready pipeline requires automated change detection to identify updates to source documentation. The pipeline must use version properties to ensure it always works with the most recent changes; this will reduce manual overhead and ensure data freshness.
Converting the data to markdown from HTML. Converting HTML to Markdown in an AI workflow means turning noisy, presentation-heavy webpage code into a clean, structured and compact text format that large language models handle more accurately. In practice, this improves grounding, summarization, RAG chunking, prompt examples, fine-tuning corpora and downstream reasoning by providing clean and consistent text units.
Configurable space-specific migration. Instead of migrating entire datasets, the pipeline enables selective migration of only the relevant spaces to Azure Blob Storage. These spaces are fully configurable, ensuring storage and processing are optimized for business-critical data.
Automated change detection via Confluence. Any updates to source documentation (Confluence pages) are automatically detected using version properties. This ensures the pipeline always works with the most recent and validated changes, reducing manual monitoring overhead.
Seamless integration with the Azure tech stack. With native compatibility to the Azure ecosystem, the pipeline can directly connect and configure with services such as Azure Blob, Data Factory, and other Azure components, reducing integration complexity for enterprises already invested in Microsoft technologies.
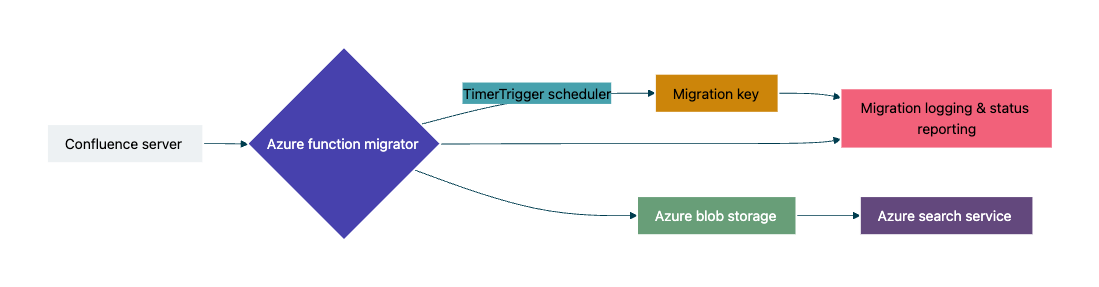
Our approach goes beyond a traditional data migration pipeline by embedding AI-driven intelligence into every stage of the process. This ensures organizational knowledge is transformed into a strategic enterprise asset.
* Accelerated knowledge discovery. By enriching extracted content with AI-powered summarization, keywords and semantic tags, employees can find relevant answers faster, reducing time spent searching through documents.
* Smarter enterprise search. With semantic embeddings integrated into Azure Search, users can ask natural language questions instead of guessing keywords. This enables smarter, context-aware discovery of knowledge.
* Always current, business-ready knowledge. Intelligent incremental updates ensure only meaningful changes are indexed, so leaders and teams always work with the most up-to-date information — without wasted resources.
* AI-ready knowledge fabric. Information isn’t just migrated; it’s transformed into a retrieval-augmented generation (RAG)-ready foundation. This prepares the business for AI assistants and automated decision-support systems.
* Enterprise-grade security. All data and secrets remain encrypted and governed within Azure Key Vault, ensuring knowledge transformation is done in line with enterprise compliance standards
The services we used for this migration were Azure Blob Storage, Azure Function, Azure KeyVault, Azure Identity and Azure Search Service.
Let’s now take a look at how the migration was done, step-by-step.
The pipeline follows the below steps:
Sets up the environment by loading configurations, initializing Azure Blob Storage client, authenticating with Confluence API and establishing logging systems.
Retrieves and filters Confluence spaces based on configuration settings to determine which spaces will be processed for migration.
Extracts all content (pages and blog posts) from Confluence spaces along with their metadata, content IDs and version information for tracking changes.
Transforms the extracted content by converting HTML to Markdown, sanitizing paths and preparing metadata with YAML front matter for Azure storage.
Performs Azure storage operations including uploading new content, updating modified content and removing deleted content while maintaining the space hierarchy.
Maintains comprehensive statistics and logs tracking the number of pages added, updated, deleted,and total processing time for each space.
Finalizes the migration by cleaning up old blobs, generating migration summaries, and handling any errors that occurred during the process.
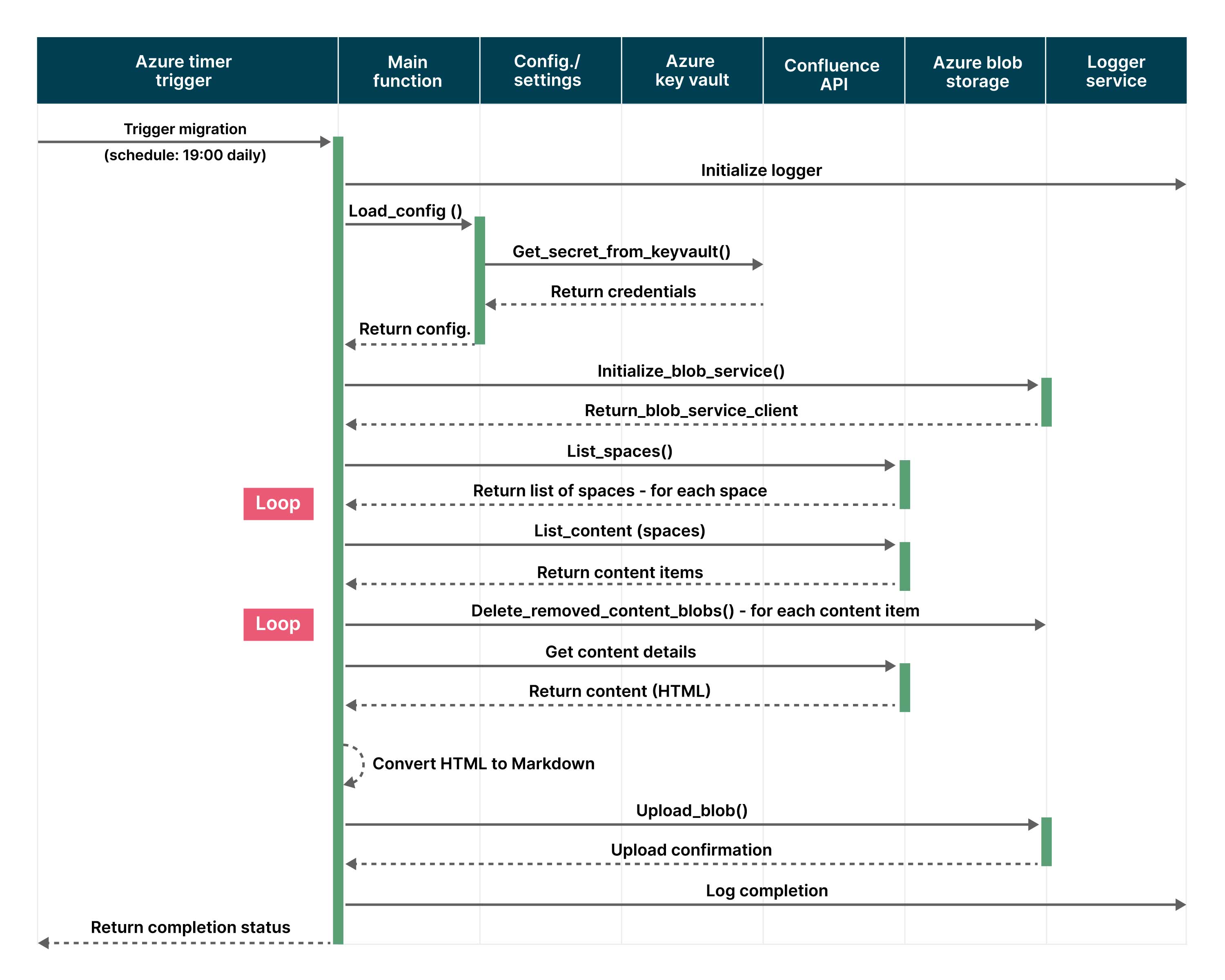
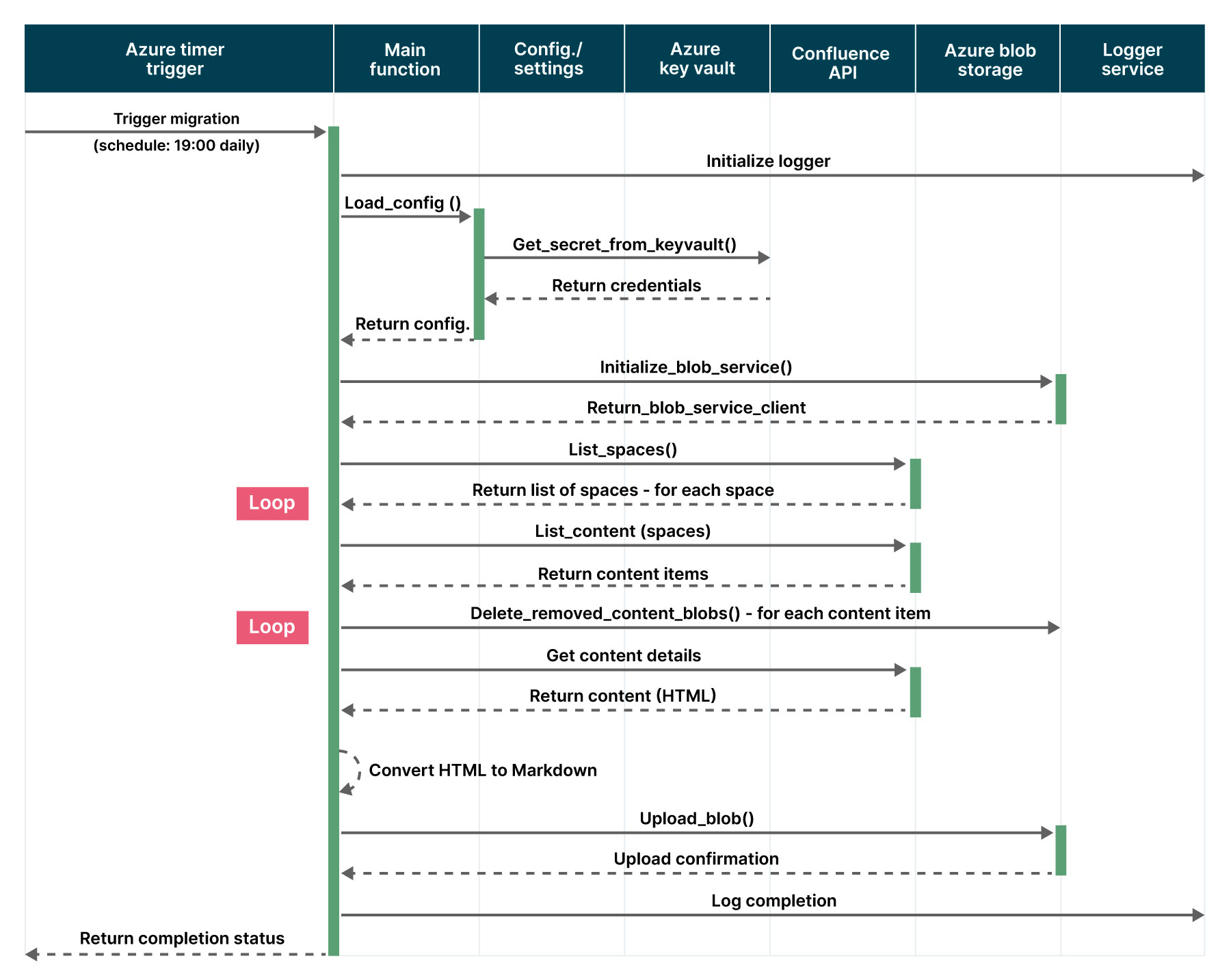
Sequence diagram for data flow
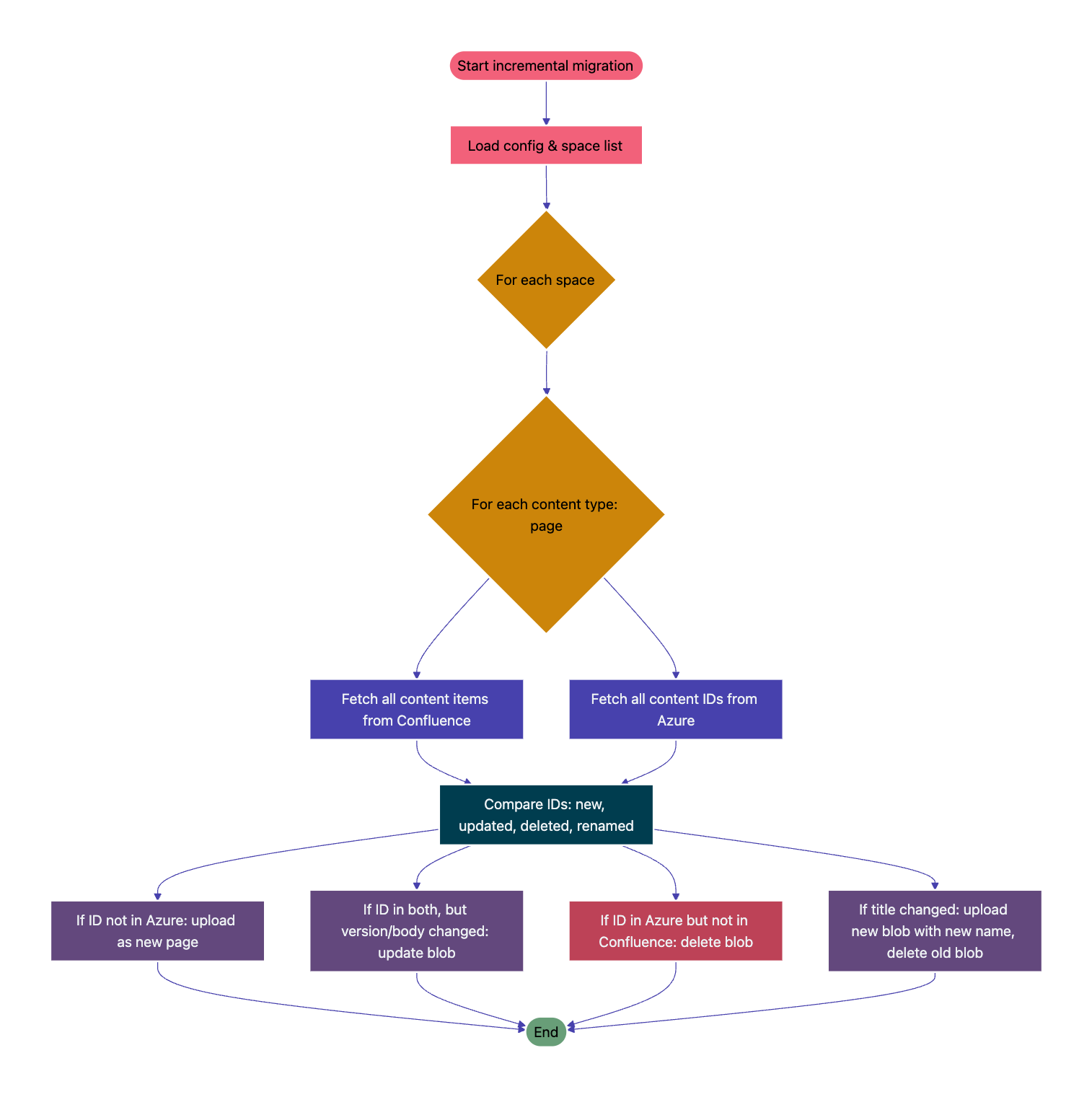
So, what did we learn from doing this migration? The process taught us a number of things:
Adopting Markdown (.md) ensures clean, lightweight and consistent documentation that integrates well across platforms. It makes pipeline steps easier to track, share and update.
Connecting with Confluence using SSL certificates enhances security by encrypting data exchange. This approach ensures compliance with organizational standards and protects sensitive information.
Focusing only on relevant data reduces noise, improves processing speed and increases accuracy in pipeline outcomes. It also optimizes storage and prevents unnecessary complexity.
Migrating Confluence content to Azure Blob Storage requires careful planning and robust implementation. Our solution provides a scalable and reliable migration process, secure handling of sensitive content, comprehensive monitoring and validation and strong error resilience with recovery capabilities.
The serverless architecture using Azure Functions proved ideal for this use case, offering cost-effective scaling and simplified maintenance. To speed up adoption, the entire pipeline is automated, and based upon the configured timeline in Azure Function, the new data either get in sync with the latest data in the confluence. This way it enables teams to have the latest data for implementing and adapting Enterprise AI Search capabilities for client needs.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

