














AI and ML
The AI-powered workforce: Cultivating the new breed of talent for 21st century operations


As enterprises advance their digital transformation, the complexity of IT systems grows exponentially. Multi-layered technology stacks — applications, servers, microservices, containers and data platforms — intertwine with legacy systems and cloud-native architectures. Rapidly evolving business demands globally elastic deployments which have in turn rendered traditional IT operations models increasingly inadequate.
Faced with overwhelming metrics, alerts, unexpected failures, ever-changing operational knowledge and continuous system iteration requirements, IT teams often find themselves trapped in a vicious cycle of "firefighting responses."
However, artificial intelligence (AI) offers a breakthrough. By unlocking efficiency boundaries in problem resolution and enabling continuous learning, AI is transforming IT operations from reactive patching to proactive evolution.
Traditional IT operations follow a linear "detect-diagnose-troubleshoot-resolve-learn" process, but its core flaw lies in delayed problem detection and exponentially rising resolution costs.
When anomalies occur, engineers must sift through thousands of logs, metrics and alerts to pinpoint root causes — a time-consuming, error-prone task reliant on human expertise. Before adopting modern solutions, clients typically spent hours diagnosing complex system failures, risking substantial business losses during that time.
Worse, high resolution costs often force teams to adopt short-sighted fixes: restarting services, applying patches or silencing alerts. While these actions restore functionality temporarily, they introduce hidden risks — degrading observability, code quality and system reliability. Over time, this leads to a downward spiral of higher costs, reduced system resilience and technical debt.
AIOps (artificial intelligence for IT operations) breaks this cycle by intervening early. It extracts patterns from massive datasets, issues preemptive warnings, analyzes root causes, recommends solutions, automates resolutions and codifies knowledge into reusable insights. This creates a virtuous cycle where earlier intervention lowers long-term costs.
Traditional monitoring tools often drown teams in "alert fatigue": a single server CPU spike might trigger dozens of alerts, with only one indicating the true issue.
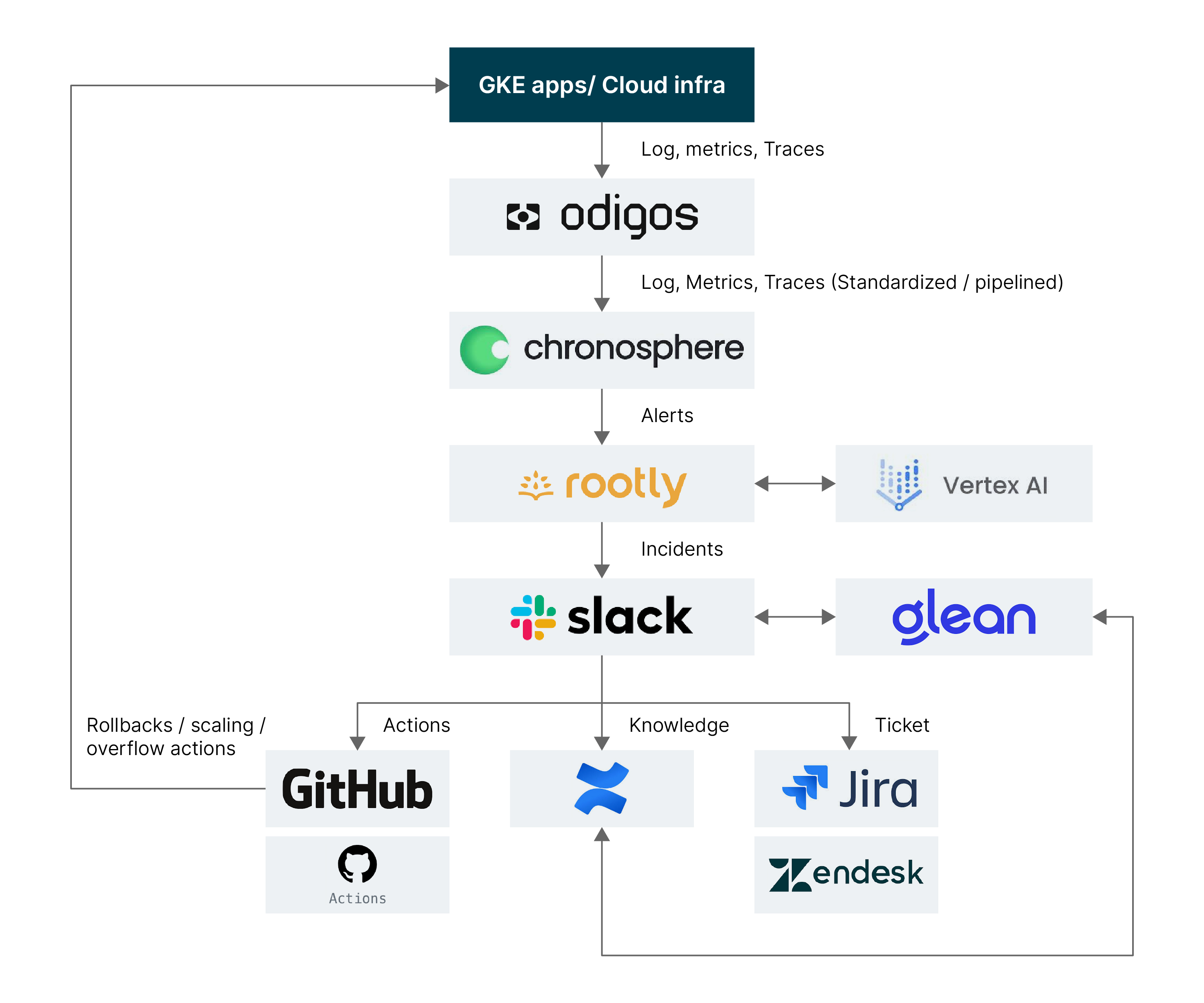
Partnering with observability and incident management platforms, Thoughtworks developed an end-to-end AI-driven SRE solution integrating metrics collection (via Chronosphere and Odigos), alert prioritization, anomaly handling and root cause analysis. The system leverages Google Vertex AI’s LLMs for incident summaries and knowledge extraction, Slack for real-time collaboration and Glean for AI-powered knowledge management. Automated actions — executed via GitHub Actions — estimated to resolve 20% of alerts upfront, while 60% are addressed before tickets are generated, significantly reducing workload.
Ticket processing traditionally involves repetitive tasks: parsing user descriptions, searching knowledge bases, assigning tasks and performing manual checks. AI revolutionizes this in three ways:
NLP-driven ticket structuring: Automatically links user-reported issues to relevant metrics, recent changes and historical context.
Knowledge graph-powered automation: For example, when a "login failure" ticket is detected, AI checks authentication services, firewall rules and deployment logs, resolving 60% of simple issues autonomously.
Smart task routing: Dynamically assigns tickets based on fault type, engineer expertise and workload, reducing cross-team coordination overhead.
In a project with a Southeast Asian government, Thoughtworks leveraged this approach to fully automate their Pre-L1 support team, repositioning eight full-time roles into strategic, value-creating positions and saving millions of dollars annually.
Healthy systems with robust architecture, automation and observability drastically reduce operational costs. Thoughtworks’ DAMO™ managed services advocates "continuous modernization": iterative optimizations over disruptive rebuilds.
For instance:
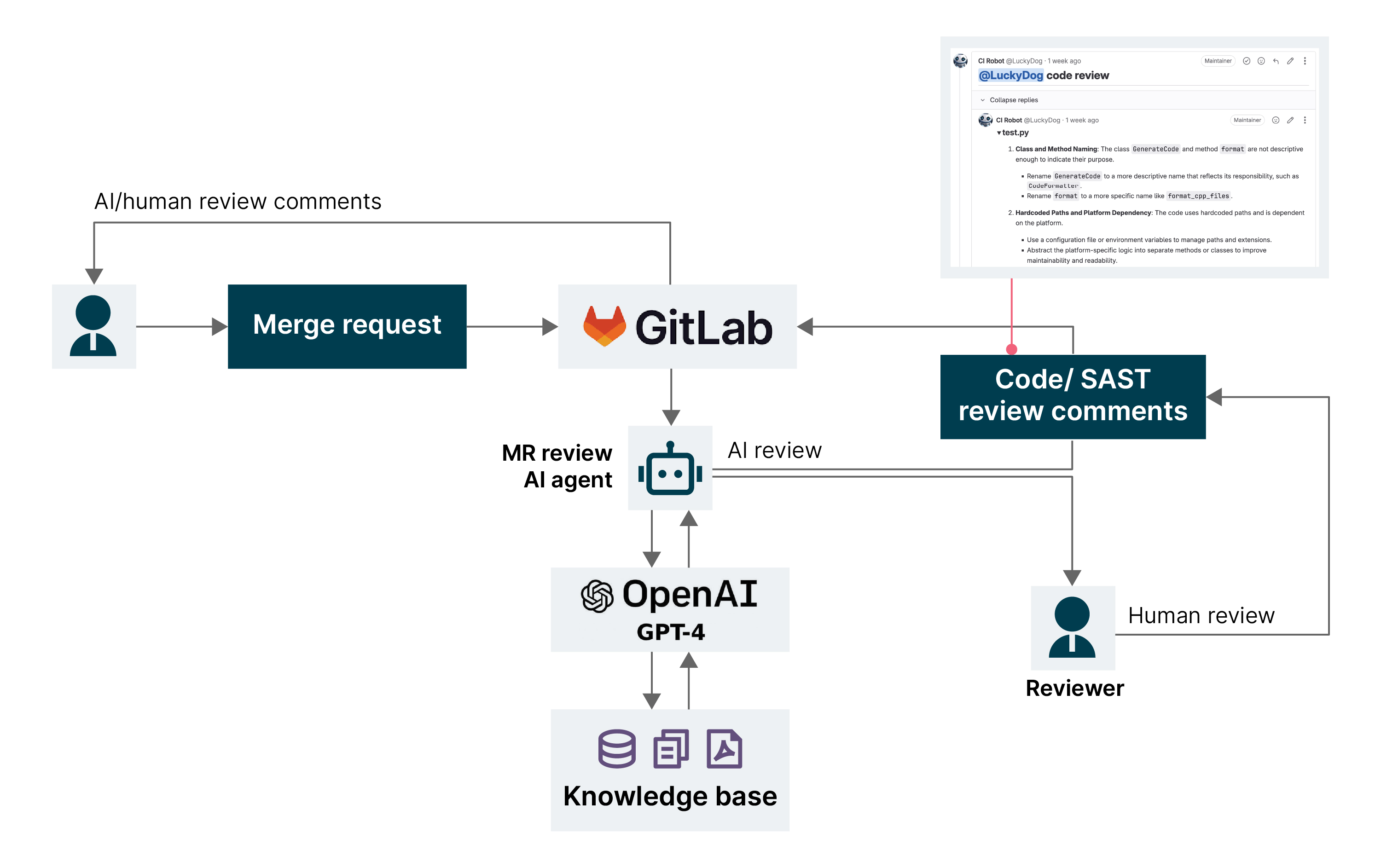
AI-augmented code reviews: Use AI to detect architectural flaws, security risks or code quality issues during commits, ensuring continuous system health.
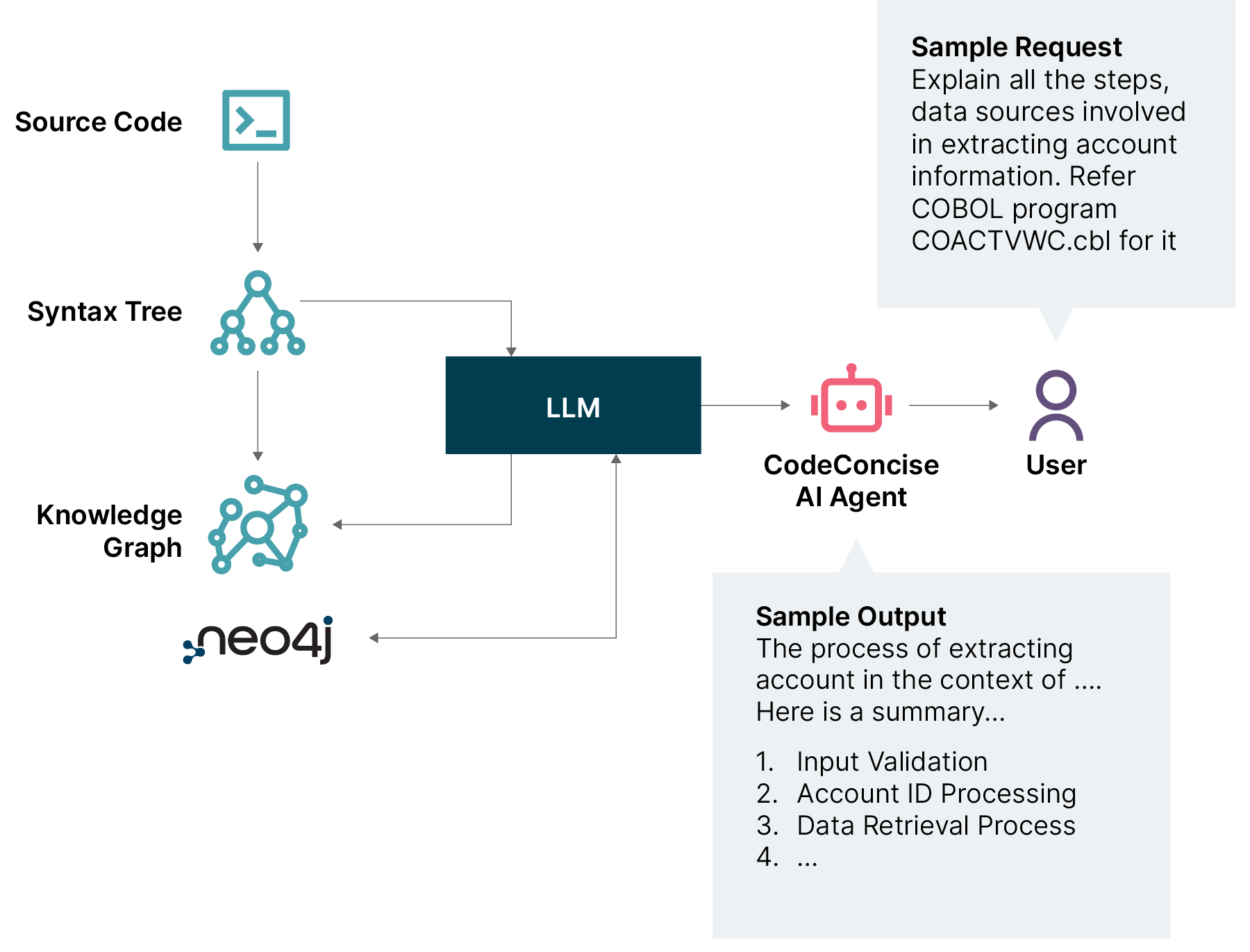
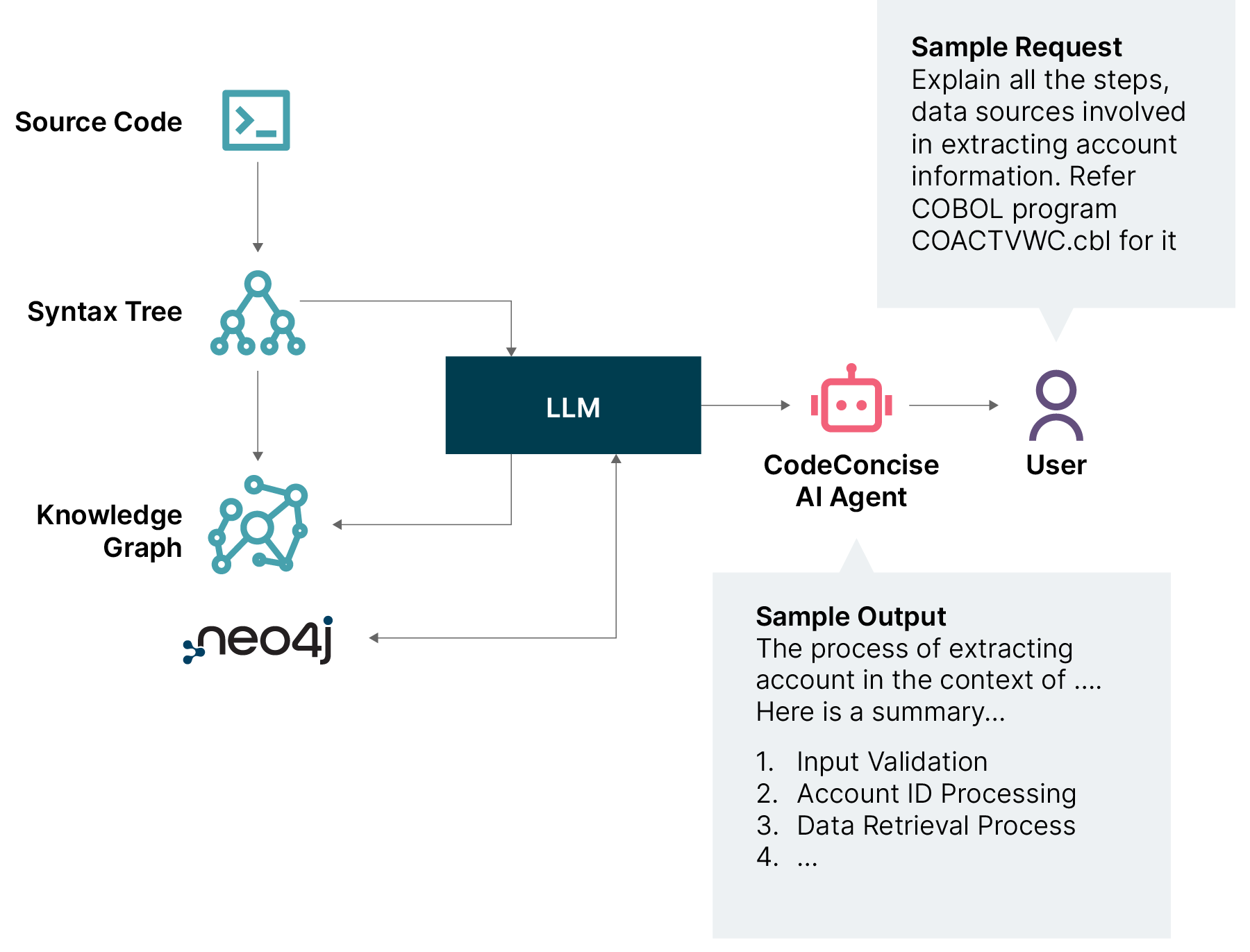
Legacy knowledge extraction: Combine LLMs and knowledge graphs to mine business logic and system insights from legacy code, aiding architecture evolution and maintenance.
AIOps transcends tool adoption, driving evolution across three dimensions:
Proactive prevention: Early warnings and root cause analysis intercept issues before they impact business.
Human-machine collaboration: AI handles high-volume, rule-based tasks, freeing humans for complex decisions and innovation.
Co-ownership of system evolution: AI safeguards code health and guides architectural improvements, while LLMs extract and transform domain knowledge.
The long-term value? As AI matures, IT systems grow smarter and more stable, enabling digital innovation while reducing maintenance costs.
AI is redefining IT operations’ "efficiency" and "value." It shifts teams from "system fixers" to "architecture guardians" and "business enablers," transforming IT from a cost center to an innovation engine. While future advancements like autonomous operations may emerge, the true goal is human-AI collaboration — the cornerstone of enterprise resilience in the digital age.

