














AI and ML
Understanding bias in algorithmic systems

Despite its growing popularity, many organizations overlook the extent to which their AI tools may be biased. This frequently takes the form of implicit bias, group attribution error, automation bias, statistical bias, convenience bias, reinforcement bias — and there are probably plenty more. One common mistake that data science teams make around ethics and responsibility of AI is to think intelligent systems are just about the AI model. In fact, the AI engine is merely one of the many components in the larger system.
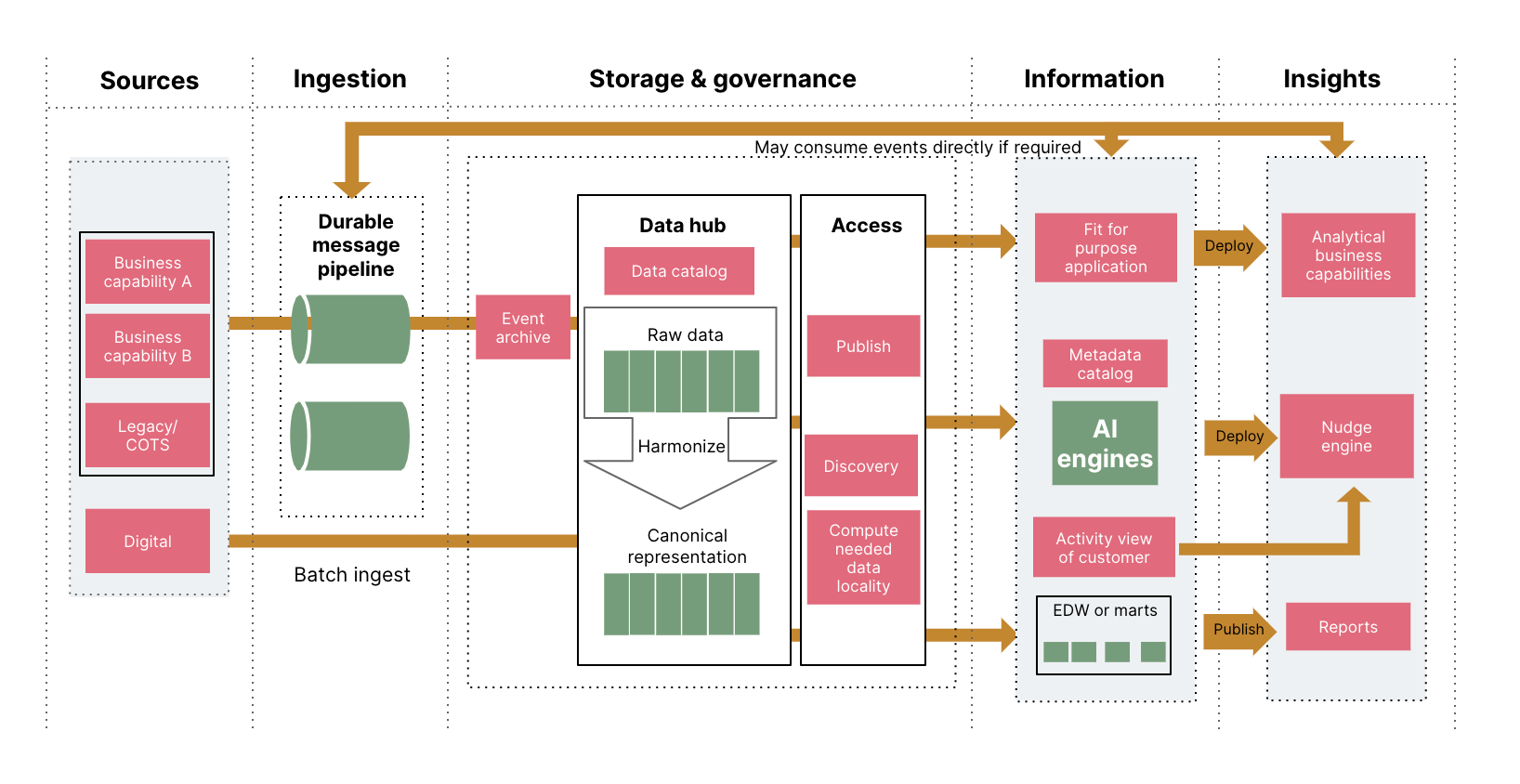
To make an AI system ethical and responsible, you need architectural measures and guardrails at an architectural level to ensure such considerations are factored in at all levels. We believe that the paradigm of evolutionary architectures can really help achieve this goal of creating an ethical and responsible AI system..
Evolutionary architecture is a software architecture paradigm. Fundamental to evolutionary architecture is the concept of a fitness function. A fitness function is anything that helps you objectively assess a desired characteristic of the system. So, if we want to ensure we embed the tenets of FATTER AI into a given system, fitness functions can help us do just that in an automated way. It works by allowing us to transform certain aims or goals into tests that provide us with feedback every time a change is made in a given model. The success of these tests can be taken as a signal of whether an AI system can be considered responsible. If the tests fail, this is indicating that our goals are not being fulfilled and are not, therefore, properly responsible.
It’s often said that algorithms are a black box — that their functioning cannot be precisely explained. However, it’s important to acknowledge and understand that even white box algorithms need to be more transparent and accountable — mere explainability of the decision is not enough.
We believe that to be truly effective, AI needs to be FATTER: fair, accountable, transparent, trustworthy, explainable and responsible.
Fairness is a property of an AI system that’s just and unbiased towards its users. Could an AI assisted judicial system that penalizes people of color be considered fair?
Accountability refers to the ownership of consequences. If a self-driving car hits a pedestrian, someone needs to own those consequences and be answerable to them.
Transparency is a function of users/observers clearly understanding what’s happening inside the system. If my job application is being evaluated by a machine, is it possible for me to know on what parameters it is being judged?
Trustworthiness is about being consistently reliable. If a machine can predict heart attack risks for individual patients, can it do this consistently?
Explainability refers to the ability to understand how a machine reached a given decision — and why. If a machine rejected my job application, why did it consider me unfit for that position?
Responsibility is about the broader application of an AI system. As a concept, it forces us to consider its overall benefit to humanity and its potential harm.
You’ll notice that these tenets overlap and that’s intentional. They all serve each other and provide the base on which the others build. Also, the implication of these tenets constantly evolve. What’s fair or responsible today might not be so tomorrow. So, AI needs to be adaptable to that.
While we knew what Fatter AI needs to do in theory, we had a lot of questions about applying it in practice. What does it take to make a system explainable? How do we achieve explainable data sets? What promotes data interpretability? What creates quality data? In pursuit of these answers, we mapped each Fatter AI tenet to multiple architectural tenets and then took a least common denominator to identify the core architectural tenets of Fatter AI systems.
Fig 1: Table mapping FATTER tenets to architectural characteristics
| Fairness | Accountability | Transperancy | Trust | Explainability | Responsibility |
| Data quality | Data quality | Decomposability | Data quality | Reproductibility | Security |
| Testability | Observability | Observability | Reproductibility | Decomposability | Privacy |
| Monitoring | Monitoring | Reproductibility | Interpretability | Observability | Anonymization |
| Observability | Reproductibility | Interpretability | Security | Tracability | Integrity |
| Experimentability | Testability | Idempotency | Privacy | Idempotency | Correctness |
| Correctness | Tracability | Simplicity | Compliance | ||
| Compliance | Compliace |

Let's understand each one in more detail and explore how we can operationalize them at an architectural level.
The first question about the effectiveness of any AI system is can we trust the data? This is answered by asking a number of different questions:
Where has the data come from?
How and why was it collected?
What changes has it been through (and why)?
Who has had and currently has access to it?
Is it complete?
To what extent is it representative of the real world?
To ensure data quality, you need to ensure validity, integrity, consistency, trustworthiness, completeness, standardization, usability, timeliness and accuracy of data. Let's take a look at a few examples to understand a few of the data quality aspects.
Validity: For a medical system leveraging blood glucose level report, the report record date should not be more than 3 months old. In an e-commerce system, the birthdate of the customer should be between the year 1900 and the current date.
Integrity: Integrity in the context of data quality refers to the consistency and accuracy of data across an entire dataset or system. Taking the same example of an e-commerce system, ensuring every customer has a unique identifier is a good example of integrity. Integrity is also about relationships between two or more data points. Ensuring every order is uniquely associated with just one customer is another example of data integrity.
Consistency: It refers to the uniformity of the data representation. The customer invoices should be represented consistently in USD or one currency of choice. The invoice value should be consistent for the type container in which the value is held across the system.
Completeness: refers to the extent to which a dataset contains all the necessary information required for the intended purpose, without significant gaps or missing values.
Evolutionary architecture leverages the principle of ‘bring the pain forward’ to make this happen. This means doing things that may cause pain earlier and more often, but will eventually help in identifying issues rapidly.
In essence, evolutionary architecture helps set up automated guardrails around data quality issues. Some ways in which this happens are:
Treating your data as code, paying attention to data quality much earlier in the lifecycle
Validating input data using data quality rules
Ensuring data immutability, i.e. never mutating in-situ and returning a new copy of the data
Data versioning as a first-class concept, tagging any change to data at the source level with a unique ID
In the spirit of treating data as code, it is essential to validate input data using data quality rules. These data quality rules can be implemented through fitness functions. Below you’ll find some example fitness functions that demonstrate how this might work. (These fitness functions are, for example, an AI system that assists a medical practitioner in determining the cardiovascular health risk of a person.)
Note** These are simple fitness functions to demonstrate the idea. What it means for your domain would likely be more complex than these.
Timeliness
describe 'Training Data Timeliness do
it 'has blood sugar readings not older than 3 months ' do
expect(blood_sugar.observation_date()).to > 3.months.ago
end
End
describe 'Training Data Timeliness do
it 'has customer interaction trends not older than one year for customer churn prediction' do
expect(timestamp(debit_transaction)).to > 12.months.ago
end
end
Correctness
describe 'Data Correctness' do
it 'has age in valid range' do
expect(age.is_between(15,100)).to be true
end
it 'age has valid data type ' do
expect(age).to be_an_instance_of(Numeric)
end
it 'has valid gender' dexpect(['F','M','O'].include?(gender)).to be true
end
it 'gender has valid data type ' do
expect(gender).to be_an_instance_of(String)
end
end
Completeness
describe "Training Data Completeness" do
it "has age field populated" do
expect(age).to be_truthy
end
it "has gender field populated" do
expect(gender).to be_truthy
end
end
A lack of transparency and lack of explainability are two of the most pressing challenges when it comes to operationalizing responsible AI.
Often, explainability is seen only in terms of the models being used: in other words, when people talk about explainability, they’re often just talking about ‘model explainability’. This is a problem because it underplays the impact of complex, unexplainable systems and data architectures. We propose to move away from this uni dimensional view of model explainability to also include a view of both systems and data architecture. To do this, we recommend looking at data decomposability and pipeline decomposability.
Data decomposability: Evolutionary architectures impact how you decompose datasets that are consumed by the system to train AI models. The horizontal split of data helps better formulate test-train-validate datasets. It’s important to understand that this is different from the feature engineering aspects, which do a vertical split of the data. Here is an example:
describe 'Data Decomposition' do
it 'does not have temporal skewness' do
expect(training_set.timestamp_range() == validation_set.timestamp_range())
end
it ‘does not have income bias between data splits’ do
expect(average(training_set.income) == average(validation_set.income))
expect(standard_deviation(training_set.income) ==
standard_deviation(validation_set.income))
endnd
describe ‘Training Data Relevance' do
it ‘has information gain < 0.2 for gender’ do
expect(input_feature).contains('gender')
expect(model.get_information_gain()).to < 0.2
end
it ‘has information gain < 0.3 for income’ do
expect(input_feature).contains(‘income’)
expect(model.get_information_gain()).to < 0.3
end
end
Pipeline decomposability: Evolutionary architectures adopt a modular approach to minimize the complexity of a maze of data pipelines. Through modularity, components can be separated along well-defined boundaries, simplifying making changes. When we design data transformers as immutable, first-class functions, we implicitly design the system for concurrency and parallelism. Ultimately, we build the ability to compose a great pipeline by putting the small puzzle pieces together. Here is an example:
describe 'Data Transformation' do
it 'standardizes gender nomenclature' do
expect(['F','M','O'].include?(gender)).to be true
end
it ‘transforms age field into age groups defined in the pipeline' do
expect(age_group).to be in [“20-25”, “25-30”, “30-35”, “35-40”]
end
it 'derives full_name without trailing spaces' do
expect(full_name).to be_truthy
expect(full_name.has_no_trailing_spaces()).to TRUE
end
it 'does output a Schema.List<Nonempty> strings as a bag of words for pre processing user_feedback’ do
expect(output).to == be_an_instance_of(Schema.NonEmptyList)
end
end
For AI systems, monitoring is often reduced to merely monitoring algorithmic performance using a confusion matrix. This is also done only during training of the algorithms and is not continuously built into the system as part of a feedback loop. Building Fatter AI systems requires us to monitor much more than just algorithms.
This means using fitness functions to monitor algorithmic performance, resilience, bias, system performance, correlation between user feedback and business metrics.
Let's look at an example for monitoring bias for a loan application system. In the given example we want to ensure that our training data has equal odds for a given attribute say “locality” on the loan acceptance. This is an example of a continuous fitness function which is always on and being monitored continuously.
Monitoring for bias
describe ‘Training Data Skewness' do
it ‘has equal odds for demographic attribute locality for loan acceptance' do
expect(true_positive_rate_of(‘locality1’) == true_positive_rate_of(‘locality2’))
end
it ‘has equal odds for demographic attribute ethnicity for loan rejection' do
expect(false_positive_rate_of(‘ethnicity1’) == false_positive_rate_of(‘ethnicity2’))
end
it ‘has equal opportunity for demographic attribute occupation for loan acceptance' do
expect(true_positive_rate_of(‘occupation1’) == true_positive_rate_of(‘occupation2’))
end
end
Monitoring for Algorithmic performance
describe 'Model Training has tolerable log-loss' do
it 'Model log-loss < 5% ' do
expect(model.get_log_loss()).to < 5
end
end
describe 'performance comparison of new model vs the existing model' do
it 'has the predictive accuracy in acceptable range' do
expect(new_model.get_log_loss() <= old_model.get_log_loss())
end
end
Incremental change allows for experimentation. For example, an improvement made in a recommendation algorithm can be A/B tested with a small subset of users to get early feedback and incorporate that into the next steps. This change can be implemented in the production algorithm only if it results in significant improvements. Testing against a baseline, a newer model with greater complexity should always perform better than the existing model in production.
Monitoring answers the question ‘what is not performing’ while observability tells us why. Evolutionary architectures allow this to happen from two ways: auditability and debuggability. Auditability is the ease with which one can understand/audit the data pipeline. For instance, is it possible for me to step through the different stages in my pipeline. Inspect the trace and see the input and output at each stage.
Debuggability is the ease with which one can carry out root-cause analysis.
By treating observability as a first class concern, you can make your AI systems robust, ethical and Fatter.
Observability
describe "Compliance Standards" do
describe "GDPR Compliance" do
it "should report types of personal information processed" do
expect(gdpr.reports_PII_types()).to be(true)
end
it "should have been audited in the past year" do
expect(gdpr.audit_age()).to < 365
end
end
While there are various tools to automate each of these aspects, the fundamental change we are recommending here is to approach intelligent systems as more than just AI. To consider the architectural foundation of AI systems as an integral part of making it Fatter.
We acknowledge that when implemented in the real world, there are always tradeoffs. For instance, there is a trade off between predictive accuracy and model explainability. While working on developing evolutionary architectures, you will have to consider these conundrums. When that happens, remember that FATTER is also an evolving concept. The goal is to focus on the right tenets for the present, make changes in right increments and allow yourself to propel change as and when you need it.

