















By Mitchell Lisle and Harmeet Kaur Sokhi
In the first half of 2022, there were 817 data compromises impacting over 53 million people in the United States. Each of these security breaches cost an average $4.35 million (US)– a 12.7% increase since 2020.
Governments around the world are implementing stricter laws around data privacy, as more organizations and individuals are affected by breaches every day. As engineering teams play an increasingly important role in this space, it wouldn’t be right to wrap up our deep dive into data engineering without discussing security and privacy.
Security and privacy are often used interchangeably, but they are not the same. Security enables privacy, but doesn’t guarantee it. Privacy typically refers to a user’s ability to control, access, and regulate their personal information, while security refers to the system that protects that data from getting into the wrong hands. You can have data security without data privacy, but not the other way around.
They are equally important and any good information management system will ensure personal data is treated appropriately.
Why shift left?
Too often security and privacy is compromised early on in development projects simply by being overlooked. While this might mean you can initially move fast, over time you’ll need to invest significant time and energy refactoring their software for security and privacy.
To make things even more complicated, the challenges of doing this to a product or solution that is already in production can lead to further risks as it increases the surface area for security or data breaches. For any product that processes data that could be considered Personally Identifiable Information (PII), security and privacy is especially critical to consider from the very beginning of a project.
And that is what we mean by “shifting left:” In software engineering, shifting left is a conscious effort to embed certain practices earlier in the development lifecycle – left being the start of a product lifecycle, right being the end.

Figure 1: Value in shifting left
Many organizations will have security engineers or even a Chief Information Security Officer (CISO), yet many lack technical expertise when it comes to privacy. This has led to the emergence of the privacy engineer – a specialist software engineering role that ensures privacy considerations are embedded into product development, rather than left as an afterthought. The need for this role has intensified partly because organizations there are today increasing legislative requirements to which practices, processes and products must comply. Greater awareness of the ethical dimension of technology also makes the role particularly valuable. In the past, data collection was something often done with little consideration for users’ personal privacy. However, today privacy can be a differentiator: there are plenty of examples of privacy being placed at the center of a product development.
In the same way that we — as developers — think about technical debt, we need to also start paying attention to our “privacy debt”. With data breaches increasing, companies have a decision to make about when they tackle this debt. Those that successfully shift left on security and privacy will significantly reduce the probability of ending up on a growing list of companies who have failed to protect their data.
Safeguarding data
Personally Identifiable Information (PII) is data that directly identifies, in isolation or in combination with other data, an individual. Without the right security in place, hackers can access this data and create profiles – using that information to impersonate them or sell it to other criminals.
Consideration is required when storing any form of personal data. Stop and reflect: is collecting PII necessary to deliver the customer experience? Can you retain trust? For example, a retail recommendation system can offer a tailored experience with a broad age bracket without capturing a customer's date of birth. For organizations that do use PII, being able to find and identify sensitive data is critical to protecting their customers and their reputation. Technologies like data catalogs and appropriate governance frameworks are particularly useful here for ensuring data can be effectively organized and secured.
It is important to note that simply obfuscating or masking PII fields in a dataset does not necessarily de-identify an individual’s data. It may be possible to re-identify the data using other contextual information. For example, hackers use uniqueness as a path to exploit vulnerabilities, so knowing all the ways your data can be unique to an individual is important. A driver of a distinctly coloured car in a large city might be fairly unique, but that same driver in a small country town would be identified easily. This also goes for machine learning approaches that are trained on data with outliers. Outliers can reveal sensitive information about your data and can inadvertently leak it through a prediction API.
One of the complexities organizations face is the need for access to PII to allow development teams to experiment and test as they’re working. Test environments are often not subject to the same security and privacy, because they don’t contain production data. But a data science workflow needs to have data that represents production, so you can train models and do analysis to understand what that model will do in production.
There are many ways you can do this without giving access to production data directly:
Generate fake data that matches the schema of your production data. For some use cases, such as data validation checks, this can be enough to help ensure pipelines work adequately and without error. But if your goal is to train and release a model into production, you should avoid fake data. Not training your model on data that is as close to the real thing as possible raises ethical and accuracy concerns.
Evaluate whether synthetic data, or data that is representative of the real scenario but generated by a model, could work for your use case. You may still need to apply additional privacy preserving techniques on top of this data.
Generate a subset of secure, anonymous data. Anonymization is a challenging and at times impossible task when it comes to PII. Simply removing obvious fields like names, addresses and other identifiers does not mean you cannot re-identify an individual in that dataset. Having a good understanding of privacy engineering practices such as masking, differential privacy and encrypted computation are important to do this effectively.
Build an isolated secure environment specifically for model building and training with access to a copy of production data. This approach is more costly and introduces risk since you’re copying data to another location. You’ll also need a separate environment with all of the same security and privacy controls as production.
The biggest shift you have to make to improve security and privacy is to think small. Data minimization is your friend – helping you build what you want, using the smallest subset of data you really need.
Adopt sensible security practices
There are a number of practices you can put in place to help you make decisions when it comes to developing secure data products.
Appointing security champions with experience in security activities and processes will help guide your development teams on the right decisions to make.
Put a data classification process in place to allow you to tag sensitive data and apply governance policies across the organisation based on the sensitivity of your data.
Here is a simple mental model for your data as it enters your systems.
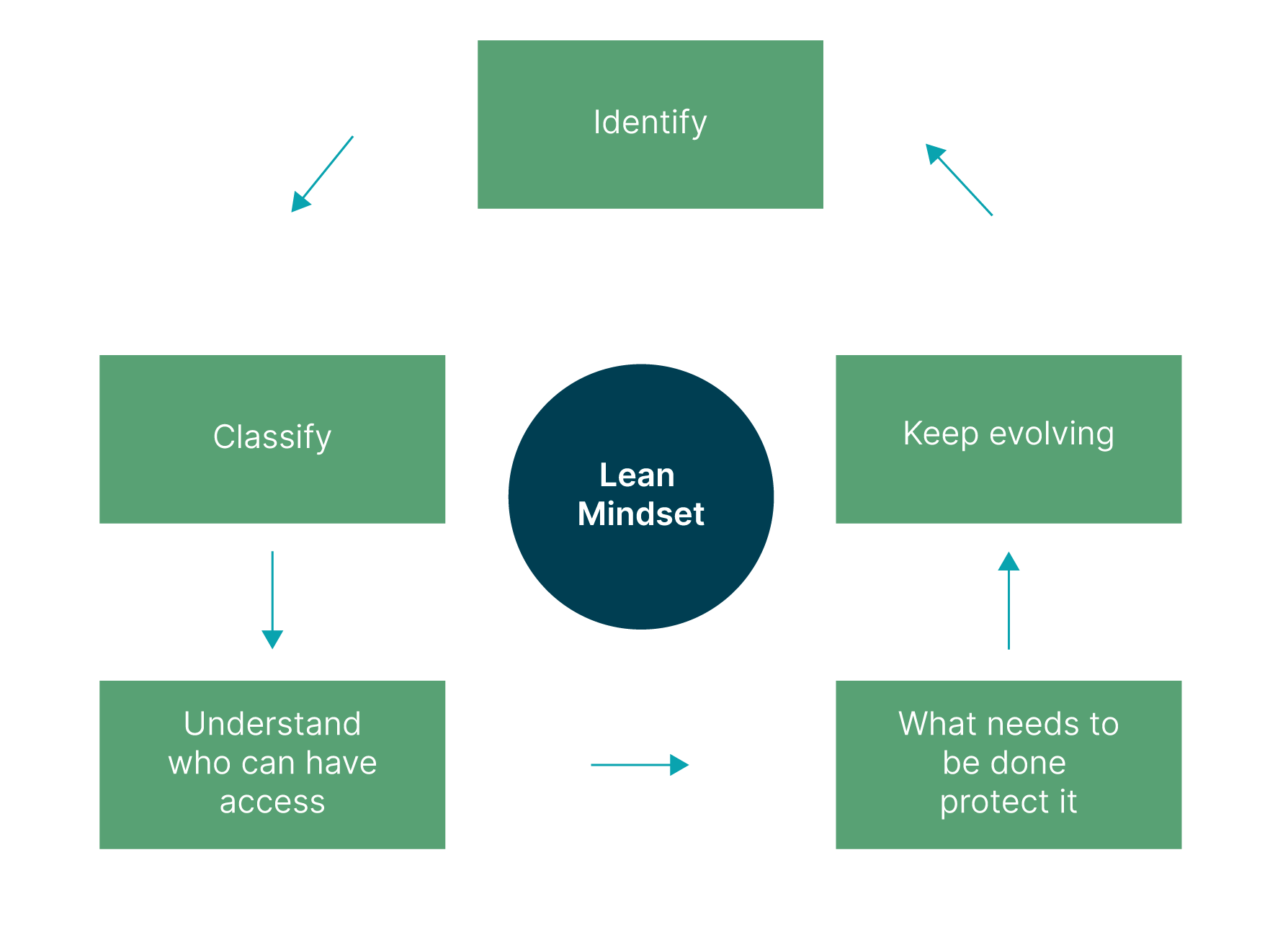
Figure 2: Lean mindset
3. Run frequent security workshops, such as threat modelling, to so you can make impact incrementally, prioritizing work as you go. Focus on small, actionable changes you can make to ensure these sessions continue to deliver value to your security infrastructure.
4. Use the CIA (Confidentiality, Integrity, Availability) triad to think about security:
- Confidentiality: The asset cannot be accessed by people or systems that shouldn’t access it.
- Integrity: The asset cannot be changed by people or systems that shouldn’t change it.
- Availability: Every person and system that should be able to access an asset can do so.

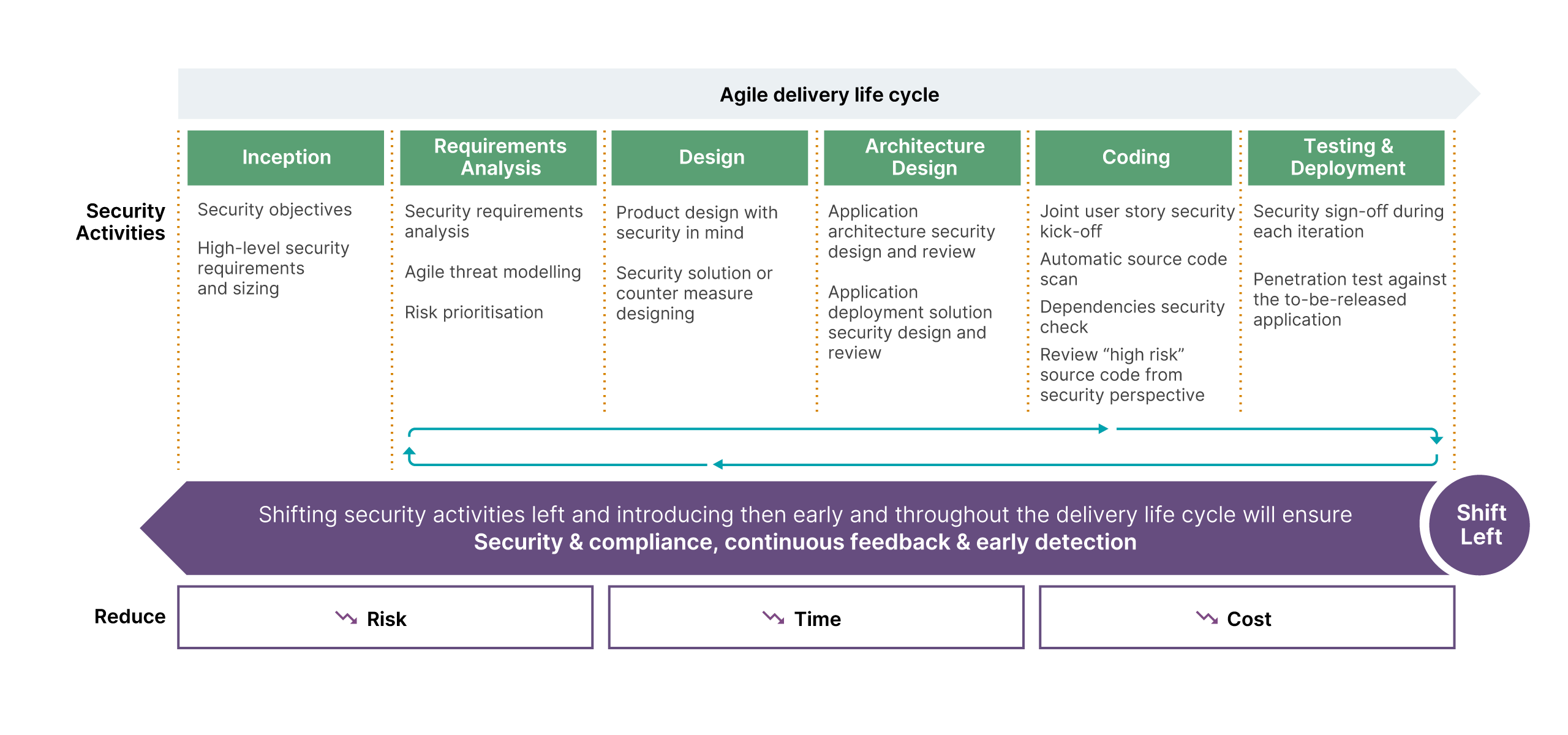
Figure 4: Phases of a project lifecycle
Read our Responsible tech playbook for more useful tools, techniques and principles. Use it to inform your next planning session, and to better address critical security and privacy considerations; many of the tools and frameworks you find in it will help you to assess your own risks.
Invest in security from the start
Building security and privacy into your process will improve the quality of your software and enable you to move faster without having to rely on major refactors to ensure your systems are up to standard.
The later you leave security and privacy in the development process, the more at risk you are of a significant data breach or security incident. Investing in everything needed to embed security and privacy in your system is well worth it in the long run: for your organization and your customers.