














Data engineering
CD4ML with Jenkins in DAGsHub

agent {
dockerfile {
additionalBuildArgs '--tag rppp:$BRANCH_NAME'
args '-v $WORKSPACE:/project -w /project -v /extras:/extras -e PYTHONPATH=/project'
}
}
Details:
# Dockerfile
FROM python:3.8 # Base image for our job
RUN pip install --upgrade pip &&
pip install -U setuptools==49.6.0 # Upgrade pip and setuptools
RUN apt-get update &&
apt-get install unzip groff -y # Install few system dependencies
COPY requirements.txt ./ # Copy requirements.txt file into image
RUN pip install -r requirements.txt # Installing project dependencies
When building docker images from a Dockerfile, we can control which files docker needs to consider to create docker context, by defining ignore patterns in a .dockerignore file. This enables faster and lighter Dockerfile builds. In our case, the only external file needed to build the Docker image is the requirements.txt file:# .dockerignore * # Ignores everything !requirements.txt # except for requirements.txt file ;)Now that we’ve defined the docker image we want to use to run our pipeline, Let’s dive into our Jenkins pipeline stages.

 Figure 1: End-to-end Jenkins pipeline stages
Figure 1: End-to-end Jenkins pipeline stages
stage('Run Unit Test') {
steps {
sh 'pytest -vvrxXs'
}
}
stage('Run Linting') {
steps {
sh '''
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
flake8 . --count --max-complexity=10 --max-line-length=127 --statistics
black . --check --diff
'''
}
}
stage('Setup DVC Creds') {
steps {
withCredentials(
[
usernamePassword(
credentialsId: 'DVC_Remote_Creds',
passwordVariable: 'PASSWORD',
usernameVariable: 'USER_NAME'),
]
) {
sh '''
dvc remote modify origin --local auth basic
dvc remote modify origin --local user $USER_NAME
dvc remote modify origin --local password $PASSWORD
dvc status -r origin
'''
}
}
}
Explanation:

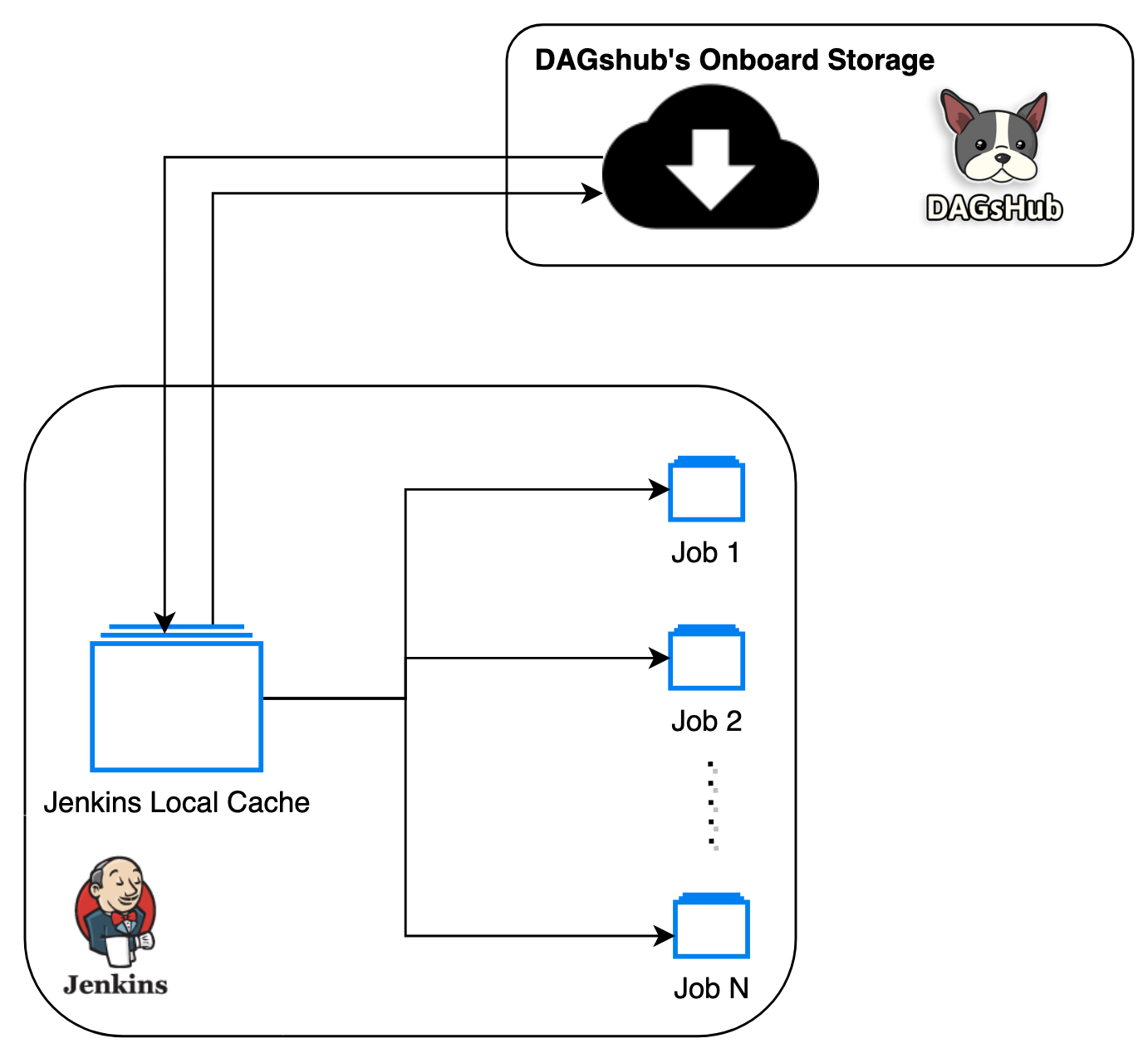
stage('Sync DVC Remotes') {
steps {
sh '''
dvc status
dvc status -r jenkins_local
dvc status -r origin
dvc pull -r jenkins_local || echo 'Some files are missing in local cache!' # 1
dvc pull -r origin # 2
dvc push -r jenkins_local # 3
'''
}
}
| Options | Pros | Cons |
| For All Commits | We will never miss any experiment | This will increase build latency. It will be extremely expensive if we use cloud resources for training jobs. Might be overkill to run the DVC pipeline for all commits/changes |
| Only for changes in the master branch | Only master branch experiments are saved, which ensures only "approved" changes and experiments are tracked. | We can not compare experiments in the feature branch before merging it to master.“Bad” experiments can slip through the PR review process and get merged to master before we could catch it. |
| Setup a manual trigger | We can decide when we want to run/skip an experiment. | Automation is not complete. There is still room for manual errors. |
| “Special” Commit message syntax | We can decide when we want to run/skip an experiment. | Automation is not complete. There is still room for manual errors. Commits are immutable, and it would be awkward to amend or create a new commit just to add the instruction. It also mixes MLOps instructions with the real purpose of the commit messages - documenting the history of the code |
| On Pull Request | We can run and compare experiments before we approve the PR. No “Bad” experiments can now slip through the PR review process. | None |
stage('Update DVC Pipeline') {
when { changeRequest() } //# 1
steps {
sh '''
dvc repro --dry -mP
dvc repro -mP # 2
git branch -a
cat dvc.lock
dvc push -r jenkins_local # 3
dvc push -r origin # 3
'''
sh 'dvc metrics diff --show-md --precision 2 $CHANGE_TARGET' //# 4
}
}

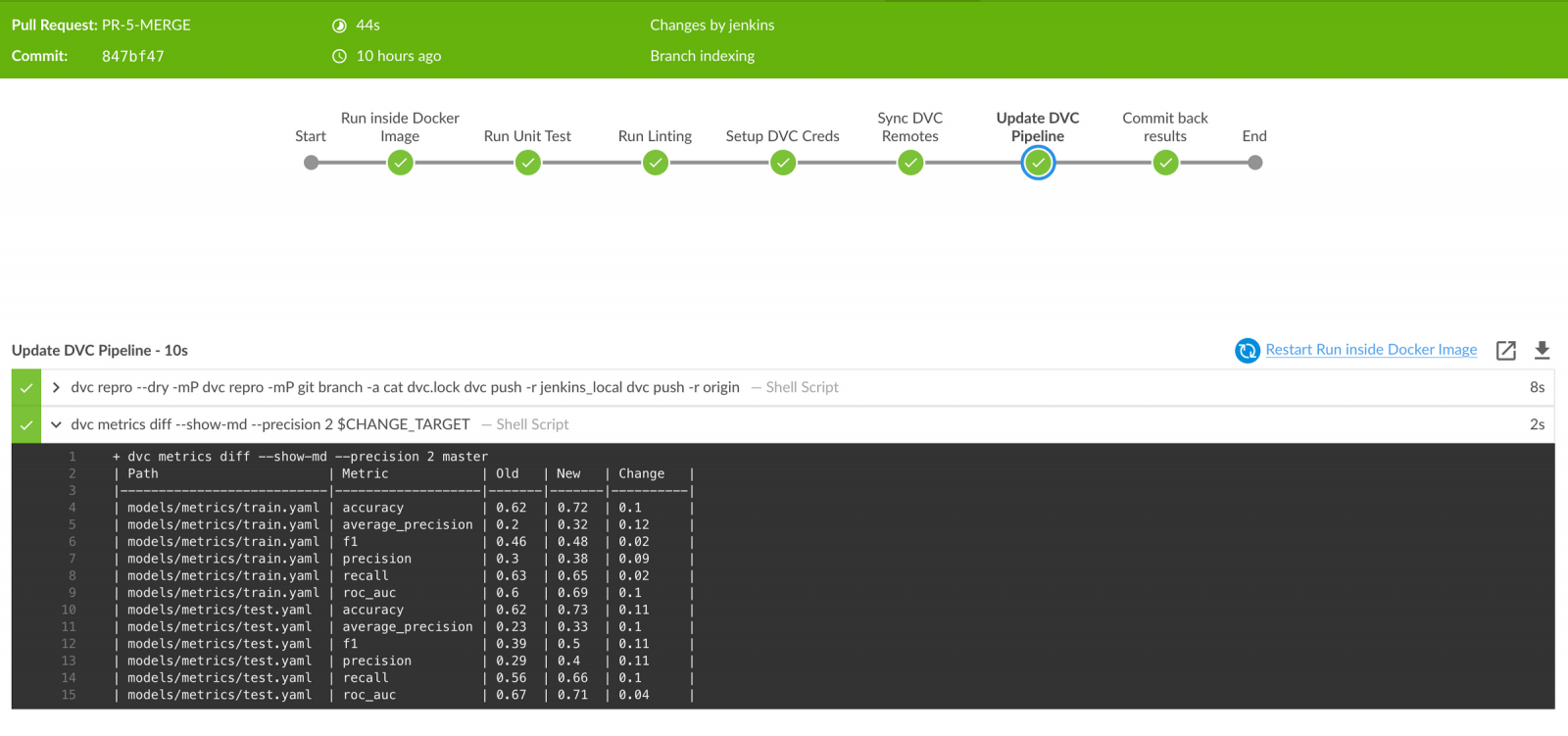 Figure 3: Comparing metrics between feature branch and master
Figure 3: Comparing metrics between feature branch and master
stage('Commit back results') {
when { changeRequest() }
steps {
withCredentials(
[
usernamePassword(
credentialsId: 'GIT_PAT',
passwordVariable: 'GIT_PAT',
usernameVariable: 'GIT_USER_NAME'),
]
) {
sh '''
git branch -a
git status
if ! git diff --exit-code dvc.lock; then # 1
git add .
git status
git config --local user.email $JENKINS_EMAIL # 2
git config --local user.name $JENKINS_USER_NAME # 2
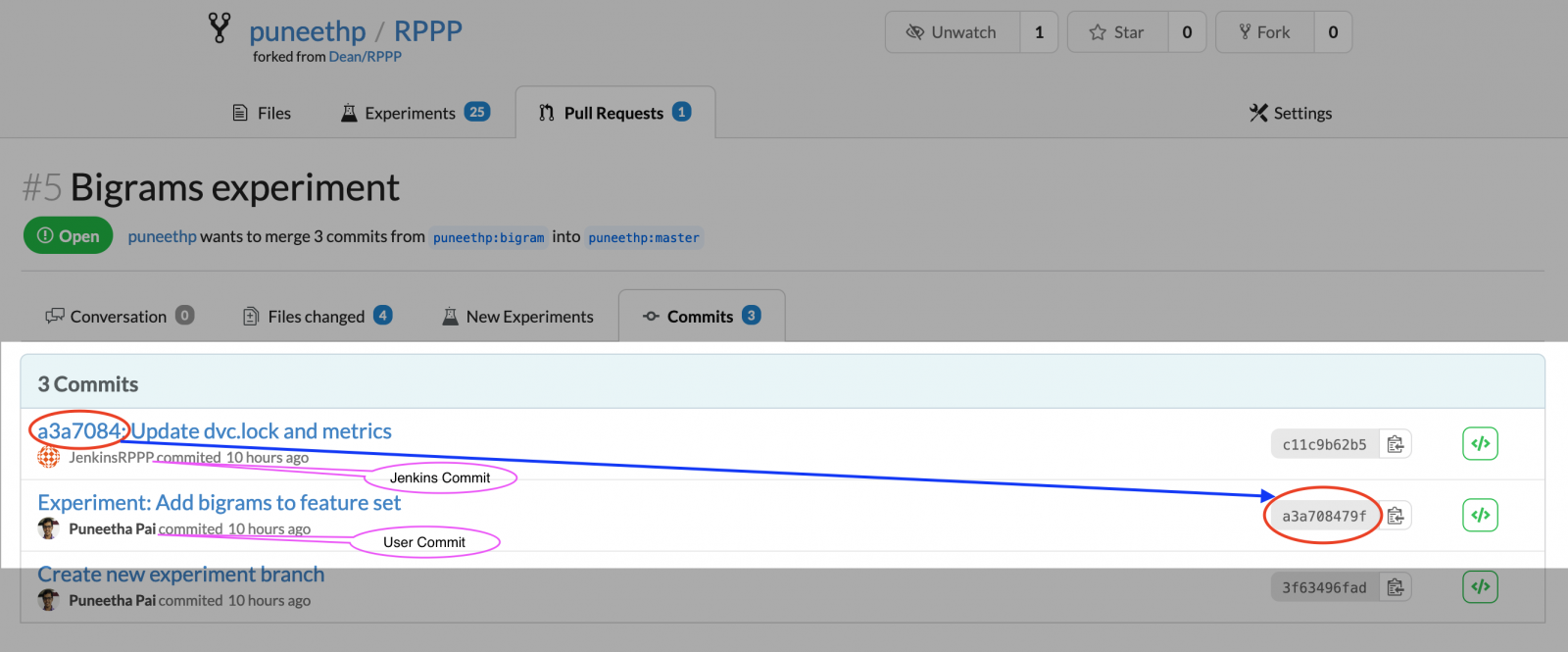
git commit -m "$GIT_COMMIT_REV: Update dvc.lock and metrics"
# 3
git push https://$GIT_USER_NAME:$GIT_PAT@dagshub.com/puneethp/RPPP HEAD:$CHANGE_BRANCH # 4
else
echo 'Nothing to Commit!' # 5
fi
'''
}
}
}

Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

