














AI and ML
Effective machine learning (Part I)

Discover big ideas in less time. In our Data & AI mini-blog series, our passionate Thoughtworkers from the Data & AI practice share insights and know-how on tough and technical topics in bite-sized pieces.
Organizations seeking to use data in a more flexible way have driven the evolution of centralized data architectures. From data warehouses to data lakes, and more recently “delta lakes,” the pattern of technological change can clearly be characterized as one that makes it easier for users to adapt to new opportunities and demands. But what are the key differences you should be aware of next time you hear these concepts discussed?
Data warehouses fully integrate storage, metadata and compute. This provides data consistency and integrity but limits scalability. Data lakes then separated compute from storage to allow both to scale independently; this unlocked new opportunities for big data applications. However, some features that are available in data warehouses, such as ACID transactions, are not by default supported by data lake table formats such as Parquet. This is where delta lakes come in: delta lake storage layers such as Delta Lake, Hudi and Iceberg bring useful guarantees around data processing to data-lake-style separated compute and storage.
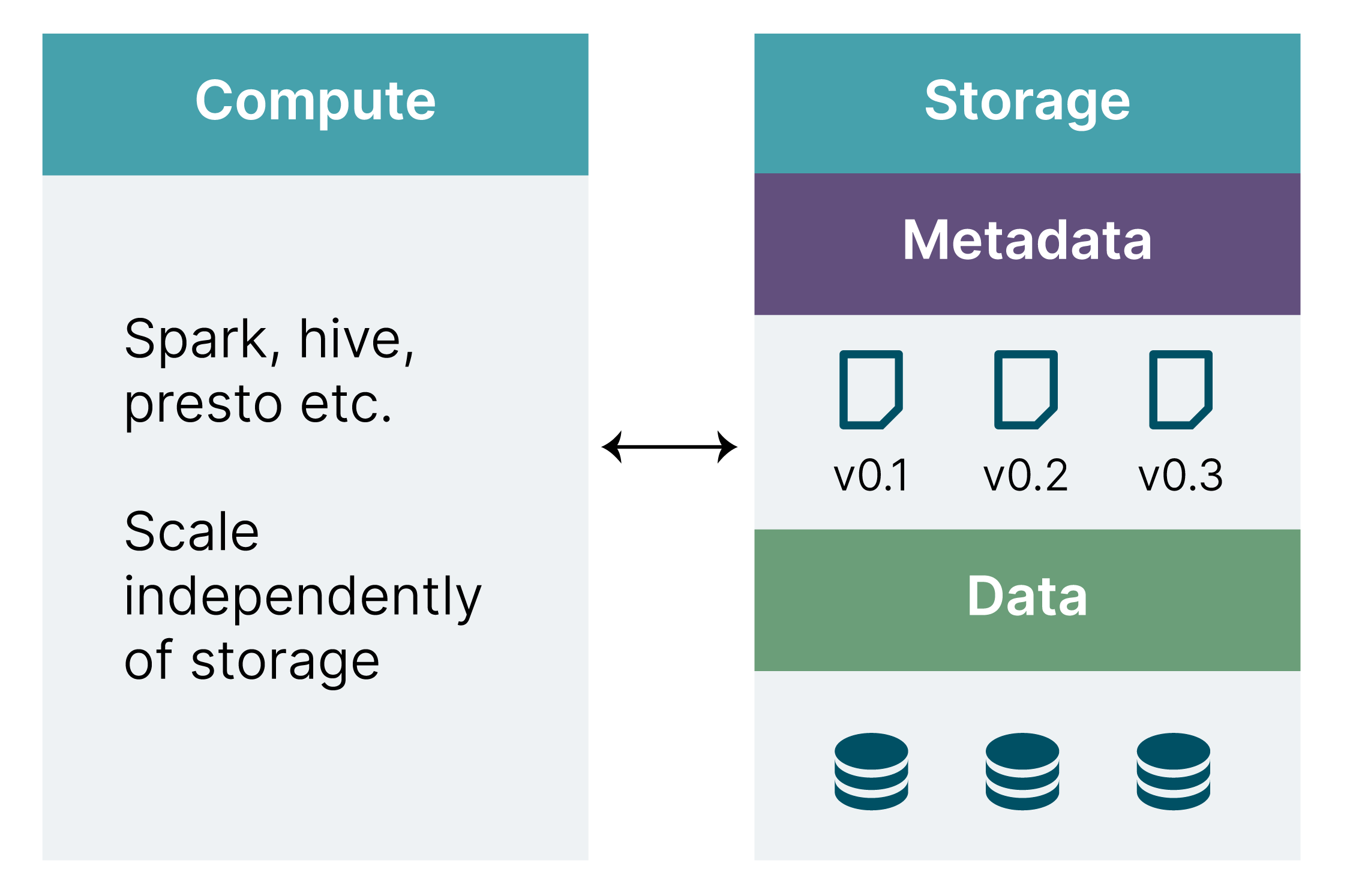
Delta lake storage layer examples include: Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark and the big data workloads. Iceberg is originally from Netflix and was open-sourced in 2018 as an Apache incubator project and has very similar features to Delta. Hudi is yet another Data Lake storage layer that focuses more on the streaming processor.
We see a wide range of solutions in our work, and while we are in general moving to more decentralized data mesh architectures, we are always open to help make sense of your landscape and options.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

